

BYOL论文笔记(Bootstrap Your Own Latent A New Approach to Self-Supervised Learning)
一、基本架构
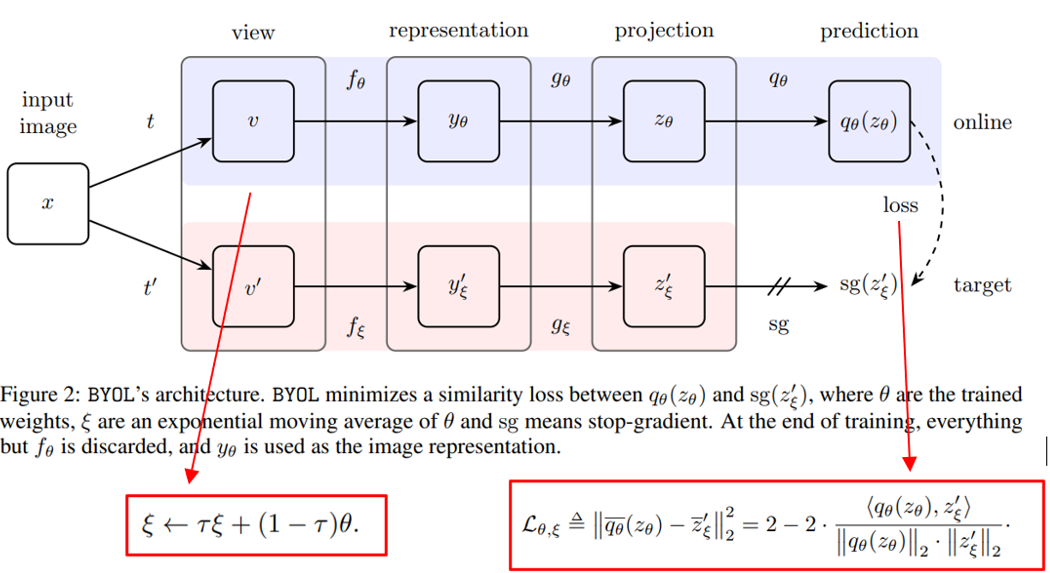
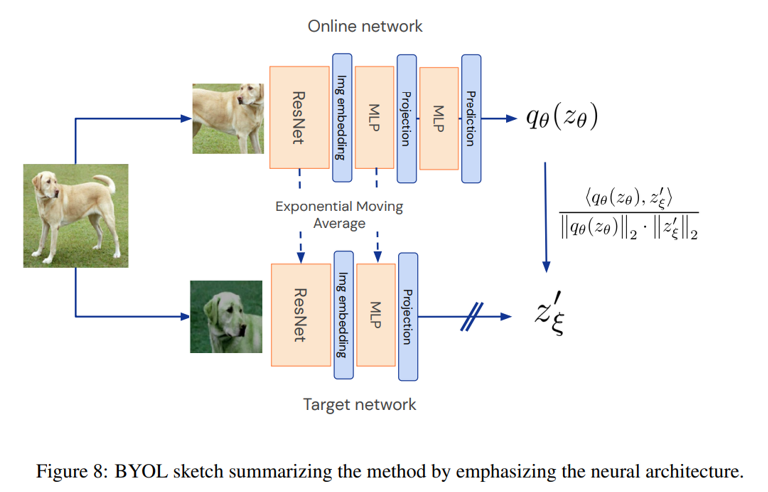
二、BYOL实现细节
数据增强:使用在SimCLR中同样的一系列数据增强,包括随机水平翻转、颜色扰动、高斯模糊等。
网络架构:使用resnet50、resnet50(1x)作为基本的编码器,使用两层的MLP作为online和target网络的投影器(2048-4096,4096-256),预测层和投影层使用同样的结构。
优化:使用lars优化器,1000epoches, batch size of 4096, 使用 512 Cloud TPU v3 cores
三、评估和消融实验
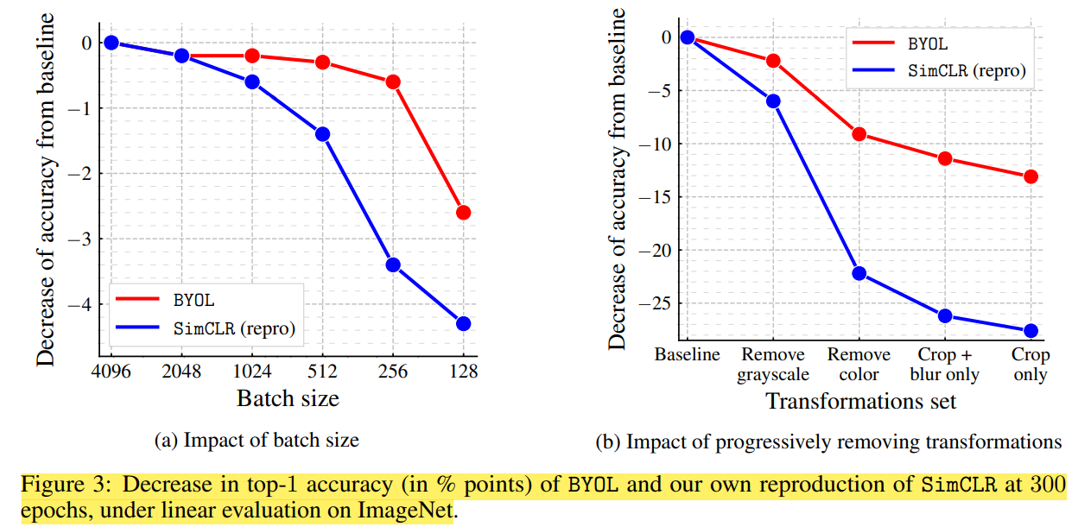

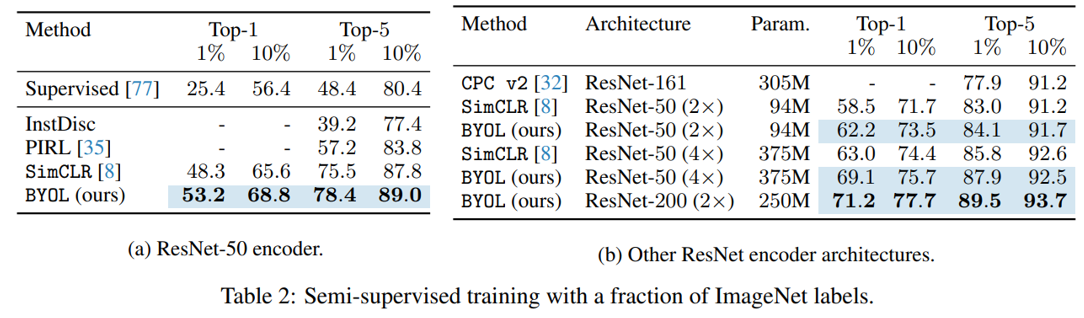
四、总结:
通过减小正例之间的距离,扩大负例之间距离的对比学习方法大多依赖大的batch size、内存或者特定的负例挖掘策略,它们的效果也取决于数据增强方式和种类的选择。
这篇文章认为不依赖负例是它具有较高鲁棒性的首要原因。使用BYOL方法,更小的batchsize和更少的数据增强类型相对于SimCLR来说精度下降的更少一些。
可利用:
官方github提供resnet50_1x的预训练模型(tensorflow版本)以及Batchsize=2048、1024、512、256、128、64的checkpoint
solo-learn提供了相关的方法和类
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

