什么是堆?
这里的堆不是指计算机里的“堆栈”,而是指一种数据结构,它的结构是一颗二叉树。
我们把一个关键码集合中所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足以下两个之一:
堆的创建
这里创建一个最小堆:
堆的插入和删除
由于堆的每次插入都在已经建好的最小堆的后面插入,但插入之后,还需要对堆进行自下而上的调整。
堆的删除:从堆顶中删除堆顶元素。移除堆顶元素后,用堆的最后一个结点填补堆顶元素,并将元素个数减一,在对堆进行自上而下的调整。
堆的应用
- 优先级队列:优先级队列的底层实现就是堆。
- 在一堆数据中找最大的前K个:先将前K个数据按照小堆进行创建,在依次遍历要查找的数据,如果该数据大于堆顶元素,则用它替换堆顶元素,并将堆调整,这样最终就可以得到最大的K个元素。
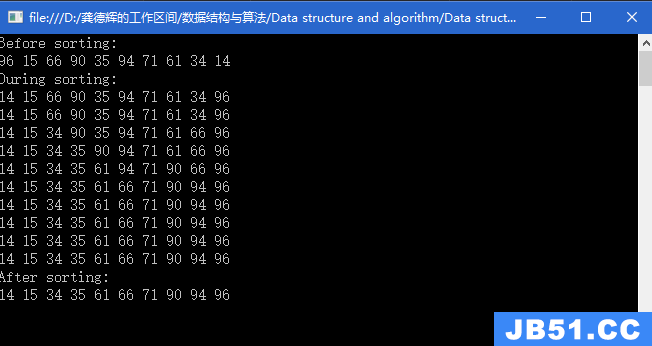
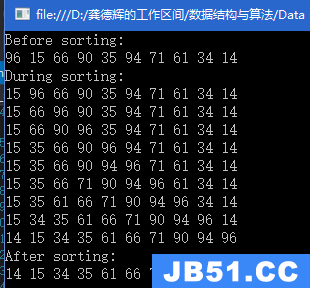
- 堆排序:如果是升序,我们需要创建一个大堆,利用和删除元素类似的想法,我们将堆顶元素和最后一个互换没然后调整堆,最终就可以得到一个升序的序列;反之,排列降序,就创建小堆。
下面是代码实现:
#include <iostream>
#include <vector>
using namespace std;
template <class T>
struct Less//小堆
{
bool operator()(const T& left,const T& right)
{
return left->_data < right->_data;
}
};
template <class T>
struct Greater//大堆
{
bool operator()(const T& left,const T& right)
{
return left > right;
}
};
template <class T,class Compare = Less<T>>
class Heap
{
public:
Heap()
{}
Heap(T *arr,size_t size)
{
_arr.resize(size);
for (size_t i = 0; i < size; i++)
_arr[i] = arr[i];
if (size > 1)
{
int root = (size - 2) / 2;//size_t的数据大于等于0造成死循环
for (; root >= 0; root--)
_AdjustDown(root);
}
}
void Push(const T& data)
{
_arr.push_back(data);
size_t size = _arr.size();
if (size > 1)
_AdjustUp(size - 1);
}
void Pop()
{
size_t size = _arr.size();
if (_arr.empty())
return;
swap(_arr[0],_arr[size - 1]);
_arr.pop_back();
if (_arr.size() > 1)
_AdjustDown(0);
}
bool Empty()const
{
return _arr.empty();
}
size_t Size()const
{
return _arr.size();
}
T Top()const
{
return _arr[0];
}
private:
void _AdjustDown(size_t parent)
{
size_t child = parent * 2 + 1;
size_t size = _arr.size();
while (child < size)
{
if (child + 1 < size && Compare()(_arr[child + 1],_arr[child]))
child += 1;
if (Compare()(_arr[child],_arr[parent]))
{
swap(_arr[parent],_arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
void _AdjustUp(size_t child)
{
size_t parent = (child - 1) / 2;
size_t size = _arr.size();
while (child > 0)
{
if (Compare()(_arr[child],_arr[child]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
private:
vector<T> _arr;
};版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。