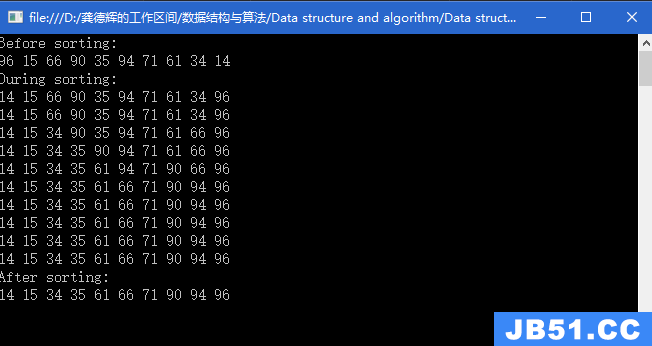
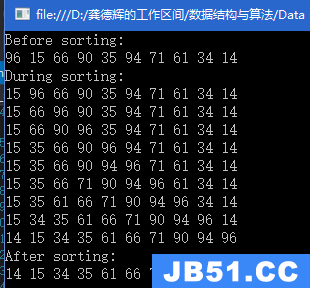
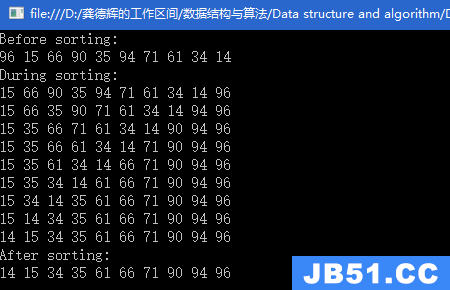
题目链接:http://poj.org/problem?id=1436
————————————————————————-.
Horizontally Visible Segments
Time Limit: 5000MS Memory Limit: 65536K
Total Submissions: 5262 Accepted: 1932
Description
There is a number of disjoint vertical line segments in the plane. We say that two segments are horizontally visible if they can be connected by a horizontal line segment that does not have any common points with other vertical segments. Three different vertical segments are said to form a triangle of segments if each two of them are horizontally visible. How many triangles can be found in a given set of vertical segments?
Task
Write a program which for each data set:
reads the description of a set of vertical segments,
computes the number of triangles in this set,
writes the result.
Input
The first line of the input contains exactly one positive integer d equal to the number of data sets,1 <= d <= 20. The data sets follow.
The first line of each data set contains exactly one integer n,1 <= n <= 8 000,equal to the number of vertical line segments.
Each of the following n lines consists of exactly 3 nonnegative integers separated by single spaces:
yi’,yi”,xi - y-coordinate of the beginning of a segment,y-coordinate of its end and its x-coordinate,respectively. The coordinates satisfy 0 <= yi’ < yi” <= 8 000,0 <= xi <= 8 000. The segments are disjoint.
Output
The output should consist of exactly d lines,one line for each data set. Line i should contain exactly one integer equal to the number of triangles in the i-th data set.
Sample Input
1
5
0 4 4
0 3 1
3 4 2
0 2 2
0 2 3
Sample Output
1
Source
Central Europe 2001
—————————————————————————.
题目大意:
就是在二维平面上有n个平行于Y轴的线段,问你两两能用水平线(平行于X轴)直接连接在一起的三元组有多少个。
大概就这意思吧
解题思路:
遇到知道题目的做法一定是考虑怎么判断两个线段是不是能够直接连接在一起的,其实只要维护一个线段树从左向右或者从右向左扫一遍就行了,对于每个线段每个都染色,维护最左或最右边的颜色就行了,只要先查询,后更新就能判断出当前的线段和之前出现过的几个线段能够直接相连接的了。
但是要注意的是,在维护线段树的时候不能直接用(y1,y2)来更新。因为会在(1,4,1)(1,2,2)(3,2)(1,3)这样的情况下出现第四条线段查询的时候查询不到第一条,所以维护的室友要用(y1*2,y2*2)来维护,这样的话。就能空出来一个5,这样就能够查询到了。
期间两个边的链接关系用一个bool型的二维数组就可以了,这样不会MLE了
最后统计结果的时候因为时间给的很宽只要三层for中间剪下枝就能怼过去了。
※数据不保证一定是从左到右的 一定要排序啊.
附本题代码
——————————————————————————————–.
//#include <bits/stdc++.h>
#include <stdio.h>
#include <iostream>
#include <algorithm>
#include <string.h>
#include <math.h>
#include <vector>
#include <map>
#include <queue>
using namespace std;
#define INF (~(1<<31))
#define INFLL (~(1ll<<63))
#define pb push_back
#define mp make_pair
#define abs(a) ((a)>0?(a):-(a))
#define lalal puts("*******");
#define s1(x) scanf("%d",&x)
#define Rep(a,b,c) for(int a=(b);a<=(c);a++)
typedef long long int LL ;
typedef unsigned long long int uLL ;
const int MOD = 1e9+7;
const int N = 8000+5;
const double eps = 1e-6;
const double PI = acos(-1.0);
/***********************************************************************/
bool path[N][N];
struct node {
int l,r;
int val;
int md() {return (l+r)>>1;}
int len(){return (r-l+1);}
}tree[N<<3];
#define ll (rt<<1)
#define rr (rt<<1|1)
#define mid (tree[rt].md())
void build(int rt,int l,int r)
{
tree[rt].l=l,tree[rt].r=r,tree[rt].val=0;
if(l==r) return ;
build(ll,l,mid);
build(rr,mid+1,r);
}
void pushdown(int rt)
{
if(tree[rt].val)
{
tree[ll].val = tree[rr].val = tree[rt].val;
tree[rt].val =0;
}
}
void update(int rt,int &L,int &R,int &val)
{
if(L<=tree[rt].l&&tree[rt].r<=R){tree[rt].val=val;return ;}
pushdown(rt);
if(L<=mid) update(ll,L,R,val);
if(R> mid) update(rr,val);
return ;
}
void query(int rt,int &id)
{
if(tree[rt].val){path[id][tree[rt].val]=true; return ;}
if(tree[rt].l==tree[rt].r) return ;
if(L<=mid) query(ll,id);
if(R> mid) query(rr,id);
return ;
}
struct segment{
int y1,y2,x1;
}e[N];
bool cmp (segment A,segment B)
{
return A.x1<B.x1;
}
int main()
{
int _;
while(~s1(_))
{
while(_--)
{
int n;
s1(n);
memset(path,0,sizeof(path));
build(1,8000*2);
int y1,x1;
Rep(i,1,n)
{
s1(y1),s1(y2),s1(x1);
e[i].y1=(y1<<1);
e[i].y2=(y2<<1);
e[i].x1=x1;
}
sort(e+1,e+n+1,cmp);
Rep(i,n)
{
query (1,e[i].y1,e[i].y2,i);
update(1,i);
}
LL sum = 0;
Rep(i,n)Rep(j,n)
if(path[i][j])
Rep(k,n)if(path[i][k]&&path[k][j]) sum++;
printf("%d\n",sum); //因为只存了单向边 所以就不用去重了
}
}
return 0;
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。