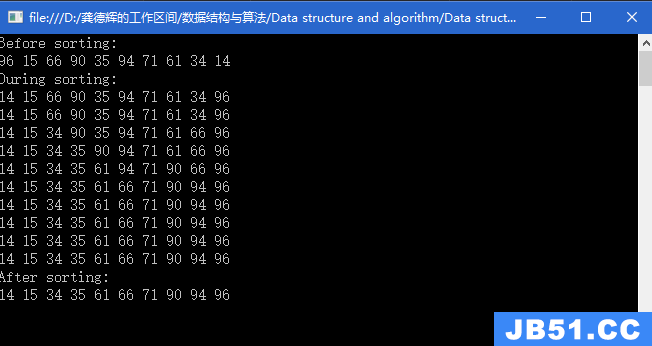
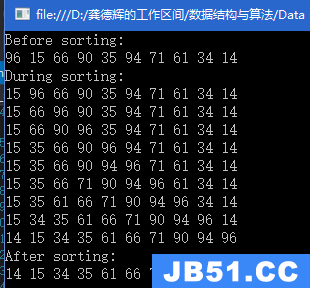
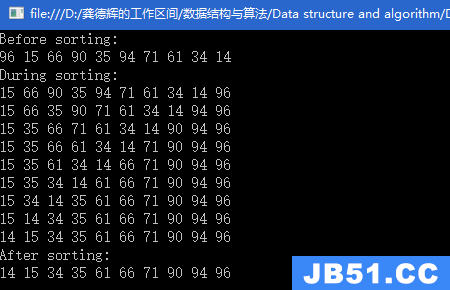
题目链接:http://poj.org/problem?id=2828
——————————————————-.
Buy Tickets
Time Limit: 4000MS Memory Limit: 65536K
Total Submissions: 18998 Accepted: 9435
Description
Railway tickets were difficult to buy around the Lunar New Year in China,so we must get up early and join a long queue…
The Lunar New Year was approaching,but unluckily the Little Cat still had schedules going here and there. Now,he had to travel by train to Mianyang,Sichuan Province for the winter camp selection of the national team of Olympiad in Informatics.
It was one o’clock a.m. and dark outside. Chill wind from the northwest did not scare off the people in the queue. The cold night gave the Little Cat a shiver. Why not find a problem to think about? That was none the less better than freezing to death!
People kept jumping the queue. Since it was too dark around,such moves would not be discovered even by the people adjacent to the queue-jumpers. “If every person in the queue is assigned an integral value and all the information about those who have jumped the queue and where they stand after queue-jumping is given,can I find out the final order of people in the queue?” Thought the Little Cat.
Input
There will be several test cases in the input. Each test case consists of N + 1 lines where N (1 ≤ N ≤ 200,000) is given in the first line of the test case. The next N lines contain the pairs of values Posi and Vali in the increasing order of i (1 ≤ i ≤ N). For each i,the ranges and meanings of Posi and Vali are as follows:
Posi ∈ [0,i − 1] — The i-th person came to the queue and stood right behind the Posi-th person in the queue. The booking office was considered the 0th person and the person at the front of the queue was considered the first person in the queue.
Vali ∈ [0,32767] — The i-th person was assigned the value Vali.
There no blank lines between test cases. Proceed to the end of input.
Output
For each test cases,output a single line of space-separated integers which are the values of people in the order they stand in the queue.
Sample Input
4
0 77
1 51
1 33
2 69
4
0 20523
1 19243
1 3890
0 31492
Sample Output
77 33 69 51
31492 20523 3890 19243
Hint
The figure below shows how the Little Cat found out the final order of people in the queue described in the first test case of the sample input.
Source
POJ Monthly–2006.05.28,Zhu,Zeyuan
——————————————————.
题目大意:
就是一堆人排队去买票,然后每一次有一个人插在某一个位置上,现在问你,最后买票的顺序
解题思路:
首先要明确的是一定要逆序进行维护,逆序的话在插队的时候才能够确定他的最终位置
以第一组样例来说的话,
逆序看 那么一定能够确定
69在第2个位置上
33在第1个位置上
77在第0个位置上
这个是一定的 .
那么这时候在想51应该排在哪里,
写出这个的话可能更好理解一些
77
77 51
77 33 51
77 33 69 51
把这个想像成一个树的话 那么逆序插入的话 就能直接判断元素所在的位置了,如果正序插入的话 还会涉及遍历后续所有元素,太耗时了.
那么这时候怎么判断之前在这个位置的元素应该放到什么位置呢?
想到这点的人真的是太机智了(现在越来越感觉自己的智商不够用了
用线段树的节点来存储这个节点所包含的区间 还有几个位置,
这样的话只要在每一次找到树中还剩下的第x个位置插入进去就行了
明白了这个就不难实现了
如果不太理解的话可以看下代码的注释
附本题代码
—————————————.
//#include <bits/stdc++.h>
#include <stdio.h>
#include <string.h>
#include <iostream>
#include <algorithm>
#include <math.h>
#define abs(x) (((x)>0)?(x):-(x))
#define lalal puts("*********")
#define Rep(a,b,c) for(int a=(b);a<=(c);a++)
#define Req(a,c) for(int a=(b);a>=(c);a--)
#define Rop(a,c) for(int a=(b);a<(c);a++)
#define s1(a) scanf("%d",&a)
typedef long long int LL;
using namespace std;
const int inf = 0x3f3f3f3f;
const int MOD = 9901;
/**************************************/
const int N = 200000+10;
struct node
{
int l,r;//区间
int val;//叶子节点的元素
int flag;//这个区间有的空位置的位置数
int mid()
{
return (l+r)>>1;
}
}tree[N<<2];
#define ll (rt<<1)
#define rr (rt<<1|1)
int a[N],b[N],cnt,ans;
void build(int rt,int l,int r)
{
tree[rt].l=l,tree[rt].r=r;
tree[rt].flag=r-l+1;
if(l==r) return;
int m = tree[rt].mid();
build(ll,l,m);
build(rr,m+1,r);
}
void update(int rt,int pos,int val)
{
tree[rt].flag--;//因为要插入一个值 所以就会少一个位置
if(tree[rt].l==tree[rt].r)
{
tree[rt].val = val;
return ;
}
if(tree[ll].flag>=pos) update(ll,pos,val);
else update(rr,pos-tree[ll].flag,val);//因为这次遍历的是右儿子,所以在右儿子中找的是第pos-tree[ll].flag个位置
}
bool fl= 0;
void dfs(int rt) //就是遍历叶子节点 输出结果
{
if(tree[rt].l==tree[rt].r)
{
if(fl) printf(" ");
printf("%d",tree[rt].val),fl=true;
return ;
}
dfs(ll);
dfs(rr);
}
int main()
{
int n;
while(~s1(n))
{
fl=false,build(1,1,n);
Rep(i,n) s1(a[i]),s1(b[i]);
Req(i,n,1) update(1,a[i]+1,b[i]);//因为建树是1~n所以讲元素位置右移一个
dfs(1),puts("");
}
return 0;
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。