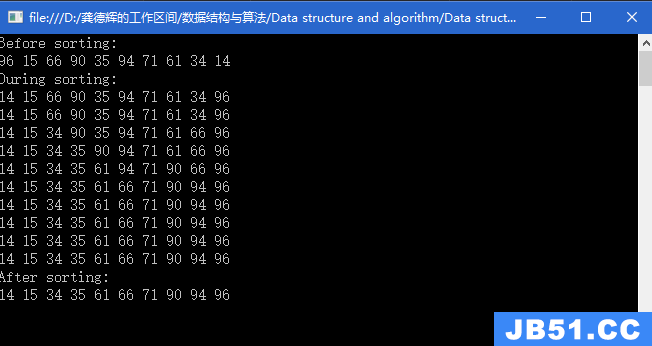
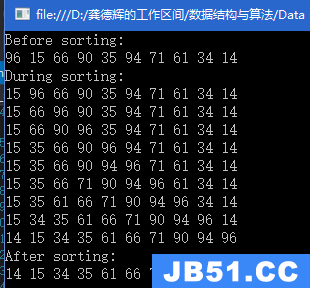
建堆
#pragma once
#include <vector>
#include<assert.h>
using namespace std;
// 小堆
template<class T>
struct Less
{
bool operator() (const T& l,const T& r)
{
return l < r;
}
};
//大堆
template<class T>
struct Greater
{
bool operator() (const T& l,const T& r)
{
return l > r;
}
};
template<class T,class Compare = Less<T>>
class Heap
{
public:
Heap()
{}
Heap(const T* a,size_t size)
{
for (size_t i = 0; i < size; ++i)
{
_infosays.push_back(a[i]);
}
// 建堆
for (int i = (_infosays.size() - 2) / 2; i >= 0; --i)
{
AdjustDown(i);
}
}
void Push(const T& x)
{
_infosays.push_back(x);
AdjustUp(_infosays.size() - 1);
}
void Pop()
{
assert(_infosays.size() > 0);
swap(_infosays[0],_infosays[_infosays.size() - 1]);
_infosays.pop_back();
AdjustDown(0);
}
const T& Top()
{
//assert(_infosays.size() > 0);
if (!Empty())
{
return _infosays[0];
}
}
bool Empty()
{
return _infosays.empty();
}
int Size()
{
return _infosays.size();
}
void AdjustDown(int root)
{
size_t child = root * 2 + 1;
Compare com;
while (child < _infosays.size())
{
if (child + 1<_infosays.size() &&
com(_infosays[child + 1],_infosays[child]))
{
++child;
}
if (com(_infosays[child],_infosays[root]))
{
swap(_infosays[child],_infosays[root]);
root = child;
child = 2 * root + 1;
}
else
{
break;
}
}
}
void AdjustUp(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (Compare()(_infosays[child],_infosays[parent]))
{
swap(_infosays[parent],_infosays[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void Print()
{
for (size_t i = 0; i < _infosays.size(); ++i)
{
cout << _infosays[i] << " ";
}
cout << endl;
}
public:
vector<T> _infosays;
};
哈弗曼树
#pragma once
#include "Heap.h"
#include<assert.h>
using namespace std;
template<class T>
struct HuffmanTreeNode
{
HuffmanTreeNode<T>* _left;
HuffmanTreeNode<T>* _right;
HuffmanTreeNode<T>* _parent;
T _weight;
HuffmanTreeNode(const T& x)
:_weight(x),_left(NULL),_right(NULL),_parent(NULL)
{}
};
template<class T>
class HuffmanTree
{
typedef HuffmanTreeNode<T> Node;
public:
HuffmanTree()
:_root(NULL)
{}
~HuffmanTree()
{
Destory(_root);
}
template <class T>
struct NodeCompare
{
bool operator()(Node *l,Node *r)
{
return l->_weight < r->_weight;
}
};
void CreatTree(const T* a,size_t size,const T& invalid)
{
assert(a);
Heap<Node*,NodeCompare<T>> minHeap;
for (size_t i = 0; i < size; ++i)
{
if (a[i] != invalid)
{
Node* node = new Node(a[i]);
minHeap.Push(node);
}
}
while (minHeap.Size() > 1)
{
Node* left = minHeap.Top();
minHeap.Pop();
Node* right = minHeap.Top();
minHeap.Pop();
Node* parent = new Node(left->_weight + right->_weight);
parent->_left = left;
parent->_right = right;
left->_parent = parent;
right->_parent = parent;
minHeap.Push(parent);
}
_root = minHeap.Top();
}
Node* GetRootNode()
{
return _root;
}
//void Destory(Node* root)
//{
// if (root)
// {
// Destory(root->_left);
// Destory(root->_right);
// delete root;
// root = NULL;
// }
//}
void Destory(Node* root)
{
if (root==NULL)
{
return ;
}
if(root->_left==NULL&&root->_right==NULL)
{
delete root;
root=NULL;
}
else
{
Destory(root->_left);
Destory(root->_right);
}
}
private:
HuffmanTreeNode<T>* _root;
};版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。