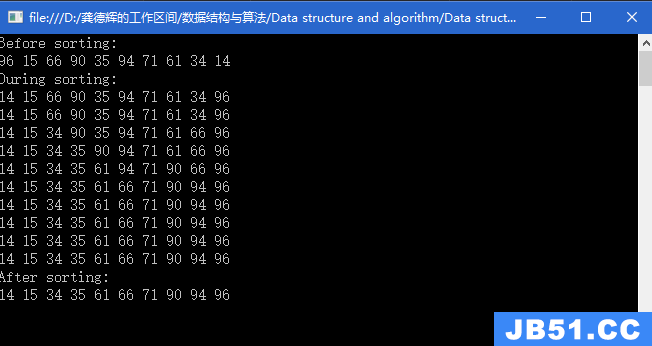
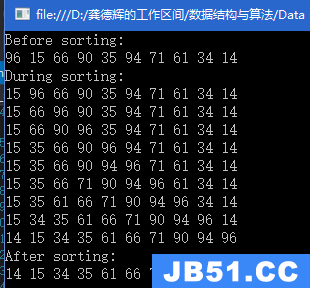
说实话,之前看数据结构的时候,并没有更多的关注到堆,直到现在......
堆数据结构是一种数组现象,可以看成是一种完全二叉树。
堆的分类;
最大堆:每个父节点都大于其孩子结点。
最小堆:每个父节点都小于其孩子结点。
注意注意:区分与二叉排序树的区别!!!
堆也有很多应用,比如优先级队列,堆排序等等。再多的应用,都是先需要有堆。
堆的底层是一个数组,了解STL之后可以将底层写成vector,可以动态增容。
堆的创建:将一个数组中的元素进行向下调整,调整成大堆或者小堆。
向下调整算法:
void _HeapDown(size_t index)
{
size_t parent = index;
size_t child = 0;
while (child < _heap.size())
{
child = parent * 2 +1 ;
if (child + 1 < _heap.size() && _heap[child] < _heap[child + 1])
++child;
if (child < _heap.size()&&_heap[parent] < _heap[child])
{
swap(_heap[parent],_heap[child]);
parent = child;
}
else
break;
}
}
只要一个结点有左右孩子,就得去比较,看是否需要交换。只能从倒数第一个非叶子结点开始。
堆也有自己的Push和Pop操作。Push操作就和栈,队列的Push一样,只是Push了之后需要调整成一个堆。Pop操作,不
Pop:将最后一个元素和0号下标的元素交换,删除最后一个元素,然后采用向下调整的算法进行调整。
Push:在数组的最后插入一个新的元素,采用向上调整的算法进行调整。
向上调整算法:
void _HeapUp(size_t child)
{
assert(_heap.size()>0);
size_t parent = 0;
Compare com;
while (child > 0)
{
parent = (child - 1) / 2;
if (_heap[parent] < _heap[child])
{
swap(_heap[parent],_heap[child]);
child = parent;
}
else
break;
}
}
这个比起向下调整就比较简单了。从给定结点开始,只需比较他和他的parent的大小关系(大堆时,parent下标的
值小于child下标的值就进行交换,并记住child值的变动,小堆同理)。
有时候,我们既需要大堆,也需要小堆,当然可以实现两个类,大堆类和小堆类。然而我们又发现大堆和小堆最大的
区别就在于个结点与孩子结点的大小关系,其他的思路什么的都是一样的,两个类就达不到代码的复用性。
下边给出代码:
template<typename T>
struct Less
{
bool operator()(const T& l,const T& r)
{
return l < r;
}
};
template<typename T>
struct Greater
{
bool operator()(const T& l,const T& r)
{
return l > r;
}
};
template<typename T,typename Compare = Greater<T>>
class Heap
{
public:
Heap(T* _a = NULL,size_t size = 0)
{
for (size_t i = 0; i < size; ++i)
{
_heap.push_back(_a[i]);
}
for (int i = (size-2) / 2; i >= 0; --i)
{
_HeapDown(i);//向下调整
}
}
void Show()
{
if (_heap.size())
{
for (size_t i = 0; i < _heap.size();++i)
cout << _heap[i] << " ";
cout << endl;
}
}
void Push(const T& x)
{
_heap.push_back(x);
_HeapUp(_heap.size()-1);
}
void Pop()//删除堆顶的元素
{
assert(_heap.size()>0);
swap(_heap[0],_heap[_heap.size()-1]);
_heap.pop_back();
_HeapDown(0);
}
size_t Size()
{
return _heap.size();
}
const T& Top()
{
return _heap[0];
}
protected:
void _HeapDown(size_t index)
{
size_t parent = index;
size_t child = 0;
Compare com;
while (child < _heap.size())
{
child = parent * 2 +1 ;
//if (child + 1 < _heap.size() && _heap[child] < _heap[child + 1])
if (child + 1 < _heap.size() && com(_heap[child+1],_heap[child]))
++child;
//if (child < _heap.size()&&_heap[parent] < _heap[child])
if (child < _heap.size() && com(_heap[child],_heap[parent]))
{
swap(_heap[parent],_heap[child]);
parent = child;
}
else
break;
}
}
void _HeapUp(size_t child)
{
assert(_heap.size()>0);
size_t parent = 0;
Compare com;
while (child > 0)
{
parent = (child - 1) / 2;
//if (_heap[parent] < _heap[child])
if(com(_heap[child],_heap[child]);
child = parent;
}
else
break;
}
}
private:
vector<T> _heap;
};
void testHeap()
{
int a[] = { 3,4,5,1,2,6,7 };
//测试大堆
Heap<int> h1(a,7);
h1.Show();
h1.Push(10);
h1.Show();
h1.Pop();
h1.Show();
//测试小堆
Heap<int,Less<int>> h2(a,7);
h2.Show();
h2.Push(0);
h2.Show();
h2.Pop();
h2.Show();
}
这里就可以实现大小堆。
时间复杂度:
建堆:O(N*lgN)
插入:0(lgN)
删除:O(lgN)
优先级队列:
我们知道,队列是一种先进先出的数据结构,然而有时候先进先出并不能满足于我们。我们需要优先级最高的元素先
出队列,下边给出两种方法:
Push:插入的时候就将插入的元素按照优先级放在合适的位置。时间复杂度O(N)
Pop:直接从队头删除。时间复杂度O(1)
Push:直接插在队尾。时间复杂度O(1)
Pop:找出优先级最高的元素进行删除。时间复杂度O(N)
第一种方法比第二种更高效。
而这里,堆是实现优先级队列的一种更加高效的方法;
下边给出代码:
template<typename T,typename Compare = Greater<T>>
class PriorityQueue
{
public:
PriorityQueue(T* a,size_t size)
:_q(a,size)
{}
void Pop()
{
_q.Pop();
}
void Push(const T& x)
{
_q.Push(x);
}
const T& Top()
{
return _q.Top();
}
void Show()
{
_q.Show();
}
private:
Heap<T,Compare> _q;
};
void testQueue()
{
int a[] = { 3,7 };
//测试小堆
PriorityQueue<int,Less<int>> q1(a,7);
q1.Show();
q1.Push(0);
q1.Show();
q1.Pop();
q1.Show();
//测试大堆
PriorityQueue<int> q2(a,7);
q2.Show();
q2.Push(10);
q2.Show();
q2.Pop();
q2.Show();
}
这里就可以高效的实现优先级队列。需要注意的是,构造函数中那个成员,必须用初始化列表完成。这里就涉及到必
须使用初始化列表的几种情况~~~~
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。