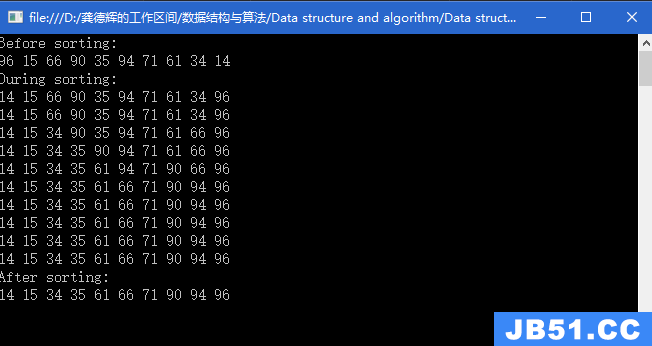
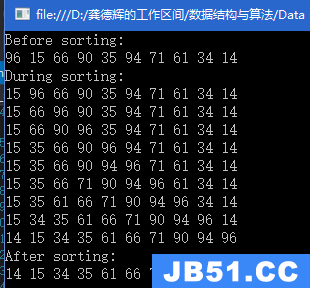
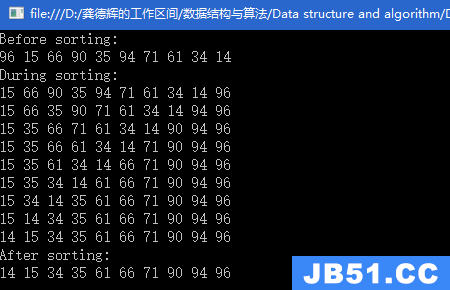
直接插入排序:
在序列中,假设升序排序
1)从0处开始。
1)若走到begin =3处,将begin处元素保存给tmp,比较tmp处的元素与begin--处元素大小关系,若begin处<begin-1处,将begin-1处元素移动到begin;若大于,则不变化。再用tmp去和begin--处的元素用同样的方法去作比较,直至begin此时减少到数组起始坐标0之前结束。
3)以此类推,依次走完序列。
时间复杂度:O()
代码如下:
//Sequenceinascendingorder
voidInsertSort(int*a,intsize)
{
assert(a);
for(intbegin=0;begin<size;begin++)
{
inttmp=a[begin];
intend=begin-1;
while(end>=0&&tmp<a[end])
{
a[end+1]=a[end];
a[end]=tmp;
end--;
}
}
}
2.希尔排序
希尔排序实际上是直接插入排序的优化和变形。假设升序排序
1)我们先去取一个增量值gap,将序列分为几组。
F{7V~}UGRXH.png")
2)然后我们分组去排序。当每个分组排序排好后,相当于整个序列的顺序就排列好了。
3)比较a[i],a[i+gap]大小关系,若a[i]>a[i+gap],则交换。否则不处理。往后走,继续该步骤……
代码如下:
//Sequenceinascendingorder
voidShellSort(int*a,intsize)
{
assert(a);
intgap=size;
while(gap>1)
{
gap=gap/3+1;
for(inti=0;i<size-gap;i++)
{
intend=i;
inttmp=a[end+gap];
while(end>=0&&a[end]>a[end+gap])
{
a[end+gap]=a[end];
a[end]=tmp;
end-=gap;
}
}
}
}
3.选择排序
假设升序排序
1)第1次遍历整个数组,找出最小(大)的元素,将这个元素放于序列为0(size-1)处。此时,未排序的序列不包括0(size-1)处.第2次,同样的方法找到找到剩下的未排序的序列中的最小的元素,放于序列为1处。
2)重复,直至排到序列结尾处,这个序列就排序好了。
时间复杂度:O(N^2)。
代码如下:
//Sequenceinascendingorder
voidSelectSort(int*a,intsize)
{
assert(a);
for(inti=0;i<size;i++)
{
intminnum=i;
for(intj=i+1;j<size;j++)
{
if(a[minnum]>a[j])
{
minnum=j;
}
}
if(i!=minnum)
{
swap(a[i],a[minnum]);
}
}
}
4.堆排序
假设升序排序
我们先要思考升序序列,我们需要建一个最大堆还是最小堆?
如果最小堆,那么每个根节点的元素大于它的子女节点的元素。但是,此时却不能保证她的左右节点一定哪个大于哪一个,且不能保证不同一层的左右子树的节点元素大小。
所以,要设计升序排序,我们需要建一个最大堆。
1)建一个最大堆。
2)第1次,将根节点的元素与堆的最后一个节点元素交换,这样肯定保证最大元素在堆的最后一个节点处,然后此时的根节点并不一定满足大于左右子女节点,因此将其向下调整,至合适位置处。第2次,将根节点的元素与堆的倒数第2个节点元素交换,向下调整交换后的根节点至合适位置……
代码如下:
void_AdjustDown(intparent,int*a,intsize)
{
intchild=2*parent+1;
while(child<size)
{
if(child+1<size&&a[child+1]>a[child])
{
child++;
}
if(a[child]>a[parent])
{
swap(a[child],a[parent]);
parent=child;
child=2*parent+1;
}
else
{
break;
}
}
}
//Sequenceinascendingorder
voidHeapSort(int*a,intsize)
{
assert(a);
for(inti=(size-2)/2;i>=0;i--)
{
_AdjustDown(i,a,size);
}
for(inti=0;i<size-1;i++)
{
swap(a[0],a[size-i-1]);
_AdjustDown(0,size-i-1);
}
}
5.冒泡排序
假设升序排序
冒泡,顾名思义,像泡一样慢慢地沉。
1)第一次,比较a[0],a[1]大小,若a[0]>a[1],则交换它们。再比较a[1],a[2],若a[1]>a[2],则交换……这样一直到比较a[size-1],a[size]结束,此时已经将一个最大的元素沉到序列的最尾端size-1处了。
2)第二次,重复上述操作,可将次最大的元素沉到size-2处。
3)重复,完成排序。
比较:
冒泡排序是两两比较,每次将最大的元素往后沉。而选择排序不同的是,每次遍历选择出最大元素放到最后。
代码如下:
//Sequenceinascendingorder
voidBubbleSort(int*a,intsize)
{
assert(a);
for(inti=0;i<size;i++)
{
for(intj=0;j<size-i-1;j++)
{
if(a[j]>a[j+1])
{
swap(a[j],a[j+1]);
}
}
}
}
6.快速排序
快速排序,顾名思义,排序算法很快,它是最快的排序。时间复杂度为:O(n*lgn).适合于比较乱的 序列。假设升序排序
对于序列:{ 5,1,8,12,19,3,7,2,4 ,11}
1)我们取序列的第一个数据当做比较的基准,并且设定序号为0的位置为低位置low,序号为size-1的位置为高位置high。
2)取出序列的基准元素key,此刻的5.
在high位置从右往左找直到找到比基准值5小的元素,即此刻的元素4处停止。
然后,在low位置从左往右找直到找到比基准值5大的元素,即此刻的元素8停止。
由于此时的基准元素key被取出,存放它的位置就空下来了。将找到的元素4赋值给此刻的这个位置.
3)此时元素4存放的位置空下来了,将找到的低位置的8放到这个位置去。
4)重复这样的动作,2放到基准位置,12放到原来2的位置……
5)直到low>=high时停止。
以上是一次快速排序,在经过一次快速排序后,high与low相遇左右各形成有序序列。再将这个相遇位置左右各当成一个序列,继续进行快速排序,最终可以将序列排序好。
代码如下:
voidQuickSort(int*a,intleft,intright)
{
assert(a);
intlow=left;
inthigh=right;
intkey=a[low];
while(low<high)
{
while(low<high&&key<=a[high])
{
high--;
}
a[low]=a[high];
while(low<high&&key>=a[low])
{
low++;
}
a[high]=a[low];
}
a[low]=key;
if(left<=high)
{
QuickSort(a,left,low-1);
QuickSort(a,low+1,right);
}
}版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。