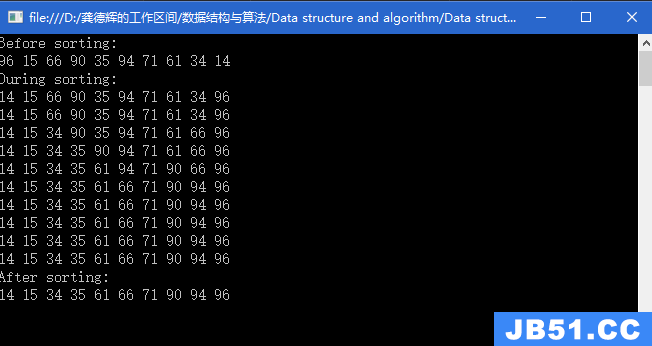
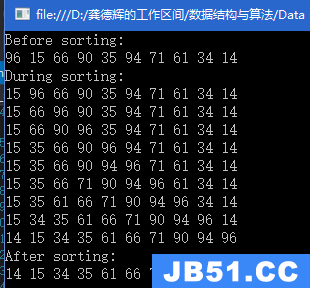
我们举例,假若从10000万个数里选出前100个最大的数据。
首先我们先分析:既然要选出前100个最大的数据,我们就建立一个大小为100的堆(建堆时就按找最大堆的规则建立,即每一个根节点都大于它的子女节点),然后再将后面的剩余数据若符合要求就插入堆中,不符合就直接丢弃该数据。
那我们现在考虑:确定是该选择最大堆的数据结构还是最小堆的数据结构呢。
分析一下:
若选用最大堆的话,堆顶是堆的最大值,我们考虑既然要选出从10000万个数里选出前100个最大的数据,我们在建堆的时候,已经考虑了最大堆的特性,那这样的话最大的数据必然在它顶端。假若真不巧,我开始的前100个数据中已经有这10000个数据中的最大值了,那对于我后面剩余的10000-100的元素再想入堆是不是入不进去了!!!所以,选用最大堆从10000万个数里选出前100个最大的数据只能找出一个,而不是100个。
那如果选用最小堆的数据结构来解决,最顶端是最小值,再次遇到比它大的值,就可以入堆,入堆后重新调整堆,将小的值pass掉。这样我们就可以选出最大的前K个数据了。
代码实现:
#define_CRT_SECURE_NO_WARNINGS1
#include<iostream>
usingnamespacestd;
#include<assert.h>
voidAdjustDown(int*a,intparent,intsize)
{
intchild=2*parent+1;
while(child<size)
{
if(child+1<size&&a[child]>a[child+1])
{
child++;
}
if(a[parent]>a[child])
{
swap(a[parent],a[child]);
parent=child;
child=2*parent+1;
}
else
{
break;
}
}
}
voidPrint(int*a,intsize)
{
cout<<"前k个最大的数据:"<<endl;
for(inti=0;i<size;i++)
{
cout<<a[i]<<"";
}
cout<<endl;
}
voidHeapSet(int*a,intN,intK)
{
assert(a);
assert(K>0);
int*arr=newint[K];
//将前K个数据保存
for(inti=0;i<K;i++)
{
arr[i]=a[i];
}
//建堆
for(inti=0;i<(K-2)/2;i++)
{
AdjustDown(arr,i,K);
}
//对剩余的N-K个元素比较大小
for(inti=K;i<N;i++)
{
if(arr[0]<a[i])
{
arr[0]=a[i];
AdjustDown(arr,K);
}
}
Print(arr,K);
delete[]arr;
}
voidtest()
{
intarr[]={12,2,10,4,6,8,54,67,25,178};
intk=5;
HeapSet(arr,sizeof(arr)/sizeof(arr[0]),k);
}
intmain()
{
test();
system("pause");
return0;
}
由此可以看出,时间复杂度为:K+(K-2)/2*lgn+(N-K)*lgn --> O(N)
空间复杂度为:K-->O(1)。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。