本节研究堆heap、Trie树、位图Bitmap的实现;
堆
说明几点
(1)堆分为大根堆和小根堆;大根堆的根为最大值,每一个节点的值都不小于其孩子的值;
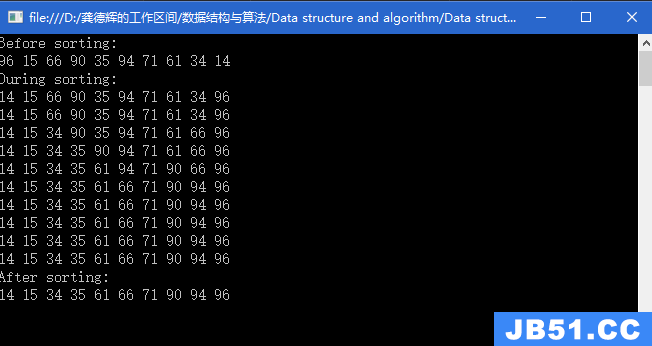
(2)可以利用大根堆实现升序排序;主要是利用大根堆的头和需要排序的最后一个数字交换的思想;
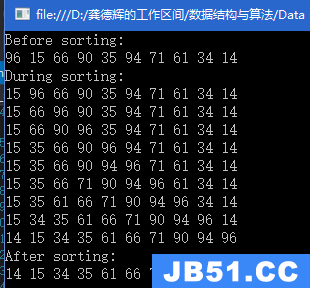
(3)使用大根堆实现最大优先级队列,类似stl中queue的操作,只是对于元素在队列中的元素优先级是不一样的,在最大优先级中,队列头为值最大元素;可利用大根堆来维护一个最大优先级队列;向优先级队列中push元素,类似像堆的末尾添加一个元素,然后使用_makeHeapUp寻找该元素的存放位置,进而维护大根堆;当向优先级队列中pop元素,将首元素和最后一个元素对换,然后使用_makeHeapDown来从首元素向下维护大根堆,类似堆排序,最后再将尾部元素pop_back;
(4)stl中使用sort_heap对容器进行堆排序,注意该容器需保证已经符合堆的特性;
(5)stl中使用make_heap对对一个容器中的值进行建堆;pop_heap,push_heap分别对队进行出堆(出堆之后,出堆值保存在容器的尾部)和入堆(入堆之前,入堆值已经保存在容器的尾部);
堆排序
inline int left(int parent)
{
return parent*2 + 1;
}
inline int right(int parent)
{
return parent*2 + 2;
}
inline int parent(int child)
{
return (child-1) / 2;
}
void _makeHeapDown(vector<int>& array,int top,int end)
{
while (left(top) < end)
{
int leftChild = left(top);
int rightChild = right(top);
int min = top;
if (array[top] < array[leftChild])
min = leftChild;
if (rightChild < end && array[min] < array[rightChild])
min = rightChild;
if (top == min)
break;
swap(array[min],array[top]);
top = min;
}
}
void heapSort(vector<int>& array)
{
for (int i = array.size() / 2; i >= 0; --i)
_makeHeapDown(array,i,array.size());
for (int i = array.size()-1; i >= 1; --i)
{
swap(array[i],array[0]);
_makeHeapDown(array,i);
}
}
说明几点:
(1)在堆排序中,仅仅使用了向下维护堆特性,但是优先级队列中使用了向上和向下维护堆特性;
优先级队列
inline int left(int parent)
{
return parent*2 + 1;
}
inline int right(int parent)
{
return parent*2 + 2;
}
inline int parent(int child)
{
return (child-1) / 2;
}
void _makeHeapDown(vector<int>& array,array[top]);
top = min;
}
}
void _makeHeapUp(vector<int>& array,int last)
{
if (last < 0)
return;
int value = array[last];
while (last > 0)
{
int parentIndex = parent(last);
if (array[parentIndex] < value)
{
array[last] = array[parentIndex];
last = parentIndex;
}
else
{
break;
}
}
array[last] = value;
}
class PriorityQueue
{
public:
int size() const
{
return _seq.size();
}
bool empty() const
{
return _seq.empty();
}
void push(int x)
{
_seq.push_back(x);
_makeHeapUp(_seq,_seq.size()-1);
}
int top()
{
if (_seq.empty())
return -1;
return _seq[0];
}
void pop()
{
if (_seq.empty())
return;
swap(_seq[0],_seq[_seq.size()-1]);
_makeHeapDown(_seq,_seq.size()-1);
_seq.pop_back();
}
private:
vector<int> _seq;
};
Trie树
基本知识
(1)Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的;
(2)根节点不包含字符,除根节点外每一个节点都只包含一个字符,节点保存对应的字符值;
(3)从根节点到某一节点,路径上经过的字符(节点)连接起来,为该节点对应的字符串;
(4)每个节点的所有子节点包含的字符都不相同;
(5)由于某些单词是其他单词的前缀,因此每一个节点增加是否为单词的标识;
(6)Trie树,即字典树,是一种树形结构,最大限度地减少无谓的字符串比较;典型应用是用于统计和排序大量的字符串(但不仅限于字符串);
基本实现
struct TrieNode
{
char value;
vector<TrieNode*> children;
bool word;
};
class Trie
{
public:
Trie()
{
root = new TrieNode();
root->word = false;
}
~Trie()
{
_deleteTrieNode(root);
}
void insert(string s)
{
TrieNode* node = root;
for (int i=0; i < s.size(); ++i)
{
if (!isalpha(s[i]))
return;
vector<TrieNode*>& children = node->children;
if (children.empty())
children.assign(26,NULL);
int index = tolower(s[i]) - 'a';
if (children[index])
{
node = children[index];
if (i == s.size()-1)
node->word = true;
}
else
{
TrieNode* child = new TrieNode();
child->value = s[i];
if (i < s.size()-1)
{
child->word = false;
}
else
{
child->word = true;
}
children[index] = child;
node = child;
}
}
}
bool search(string key)
{
TrieNode* node = root;
int i = 0;
bool flag = false;
for (i=0; i < key.size(); ++i)
{
if (!isalpha(key[i]))
return false;
vector<TrieNode*>& children = node->children;
if (children.empty())
return false;
int index = tolower(key[i]) - 'a';
TrieNode* child = children[index];
if (child)
{
node = child;
flag = child->word;
}
else
{
return false;
}
}
return flag;
}
bool startsWith(string prefix)
{
TrieNode* node = root;
for (int i=0; i < prefix.size(); ++i)
{
if (!isalpha(prefix[i]))
return false;
vector<TrieNode*>& children = node->children;
if (children.empty())
return false;
int index = tolower(prefix[i]) - 'a';
TrieNode* child = children[index];
if (child)
{
node = child;
}
else
{
return false;
}
}
return true;
}
private:
void _deleteTrieNode(TrieNode* node)
{
for (int i=0; node && i < node->children.size(); ++i)
_deleteTrieNode(node->children[i]);
if (node)
delete node;
}
TrieNode* root;
};
说明几点
(1)本程序的Trie树的建立,仅仅建立对应的小写字符的字典树,对于大写字符将转换为小写字符;遇到非单词字符将会提前返回;
(2)在TrieNode中word标识该节点是否为一个单词;
基本应用
描述:给你100000个长度不超过10的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,求第一次出现在第几个位置。
解决办法:
(1)由于单词长度不超过10,建立Trie树也是可以忍受的,空间的花费不会超过(单词数*单词长度)个TrieNode;还且可以在边查询时边建立Trie树;
(2)若单词第一次出现,查询时建立Trie树,在最后一个节点标识该单词第一次出现的位置,可以修改TrieNode的word标识类型为int(默认值为-1),存放第一次出现的位置;
(3)若单词不是第一次出现,那么在查询到该单词最后一个字符时,该字符的word标识不为-1,说明已经该单词已经出现,word的值为该单词第一次出现的位置;
位图Bitmap
基本知识
(1)在C++中,我们可以直接使用bitset来进行位图相关的操作;
(2)位图可以使用在海量数据相关处理中,比如一个文件中含有1000亿个32位整数,请找出文件中未出现的整数;此时我们就可以使用位图,所有的32位数有2^32,即4G个数,那么4G个数可以使用4Gbit,即512MB内存来存放,然后遍历文件中的每一个数,对位图中相应的位置进行置位,最后找出位图中未置位的数就可以了;
基本实现
template <unsigned N>
class Bitmap final
{
public:
explicit Bitmap(unsigned val = 0):
_size((N-1)/32 + 1),_bits(_size,0)
{
_init(val);
}
bool any() const
{
for (int i = 0; i < _bits.size(); ++i)
{
if (_bits[i] > 0)
return true;
}
return false;
}
bool none() const
{
return !any();
}
void reset()
{
for (int i = 0; i < _bits.size(); ++i)
_bits[i] = 0;
}
bool test(int pos) const
{
if (pos < 0)
return false;
int m = pos / 32;
int n = pos % 32;
return (_bits[m] & (1 << n)) > 0;
}
void set(int pos,bool flag)
{
if (pos < 0)
return;
int m = pos / 32;
int n = pos % 32;
if (flag) {
_bits[m] |= 1 << n;
} else {
_bits[m] &= ~(1 << n);
}
}
void reset(int pos)
{
if (pos < 0)
return;
int m = pos / 32;
int n = pos % 32;
_bits[m] &= ~(1 << n);
}
size_t size() const
{
return N;
}
void print() const
{
for(int i = _bits.size()-1; i >= 0; --i)
{
cout << hex << _bits[i] << " ";
}
cout << endl;
}
private:
void _init(unsigned val)
{
int i = 0;
while (val > 0)
{
if (val & 0x01)
{
int m = i / 32;
int n = i % 32;
_bits[m] |= 1 << n;
}
val >>= 1;
++i;
}
}
int _size;
vector<int> _bits;
};
int main(void)
{
Bitmap<132> bits;
bits.print();
cout << bits.test(0) << endl;
cout << bits.test(15) << endl;
cout << bits.test(16) << endl;
bits.set(117,true);
bits.print();
cout << bits.test(16) << endl;
cout << bits.test(117) << endl;
bits.reset(1);
bits.print();
cout << dec << bits.size() << endl;
cout << dec << bits.any() << endl;
return 0;
}说明几点:
(1)该位图仅仅实现相关的基本操作,底层使用vector<int>来进行实现;
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。