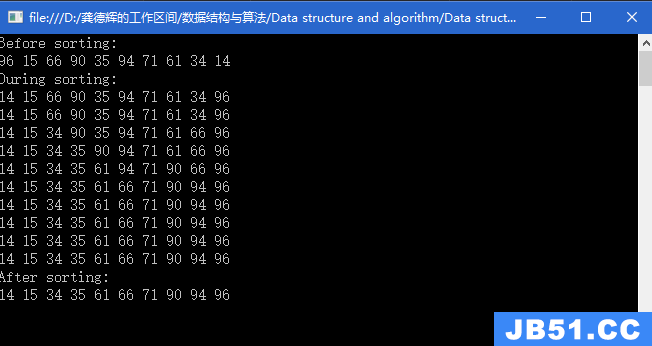
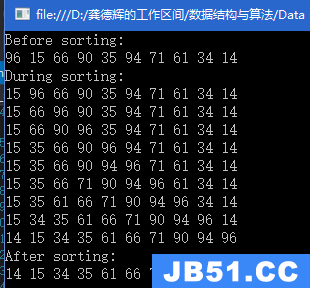
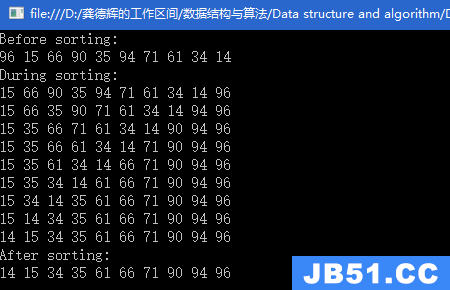
1.优先队列有两项基本操作:插入(insert)和删除最小项(deleteMin),后者的工作是找出、返回和删除优先队列中最小的元素。而insert操作则等价于enqueue(入队),deleteMin则等价于dequeue(出队)。补充:C++提供2个版本的deleteMin,一个删除最小项,另一个在删除最小项的同时在通过引用传递的对象中存储所删除的值。
2.优先队列的类接口
template <typename Comparable>
class BinaryHeap
{
public:
explicit BinaryHeap(int capacity=100);
explicit BinaryHeap(const vector<Comparable> & items);
bool isEmpty() const;
const Comparable & findMin() const;
void insert(const Comparable & x);
void deleleMin();
void deleteMin(Comparable & minItem);
void makeEmpty();
private:
int currentSize;
vector<Comparable> array;
void buildHeap();
void percolateDown(int hole);
};
3.插入到一个二叉堆
void insert(const Comparable & x)
{
if(currentSize==array.size()-1)
array.resize(array.size()*2);
int hole=++currentSize;
for(;hole>1&&x<array[hole/2];hole/=2)
array[hole] =array[hole/2];
array[hole]=x;
}
4.在二叉堆中执行deleteMin
void deleteMin()
{
if(isEmpty())
throw UnderflowException();
array[1]=array[currentSize--];
percolateDown(1);
}
void deleteMin(Comparable & minItem)
{
if(isEmpty())
throw UnderflowException();
minItem=array[1];
arrary[1]=array[currentSize--];
percolateDown(1);
}
void percolateDown(int hole)
{
int child;
Comparable tmp=array[hole];
for(;hole*2<=currentSize;hole=child)
{
child=hole*2;
if(child!=currentSize&&array[child+1]<array[child])
child++;
if(array[child]<tmp)
array[hole]=array[child];
else
break;
}
array[hole]=tmp;
}
5.左式堆(leftist heap)像二叉堆那样既有结构性质,又有堆序性质。左序堆也是二叉树,它和二叉树的唯一区别是:左式堆不是理想平衡的(perfectly balanced),而且事实上是趋于非常不平衡的。左式堆的性质:对于堆中的每一个结点X,左儿子的零路径至少于右儿子的零路径长一样大。由于左式堆是趋向于加深左路径,因此右路径应该很短,沿左式堆右侧的右路径确实是该堆中最短的路径。否则就会存在一条路径通过某个结点X并取得左儿子,此时X就破坏了左式堆的性质。
6.对左式堆的基本操作是合并(插入只是合并的特殊情形)。左式堆类型声明:
template <typename Comparable>
class LeftistHeap { public: LeftistHeap(); LeftistHeap(const LeftistHeap & rhs); ~LeftistHeap(); bool isEmpty() const; const Comparable & findMin() const; void insert(const Comparable & x); void deleteMin(); void deleteMin(Comparable & minItem); void makeEmpty(); void merge(LeftistHeap & rhs); const LeftistHeap & operator=(const LeftistHeap & rhs); private: struct LeftistNode { Comparable element; LeftistNode *left; LeftistNode *right; int npl; LeftistNode(const Comparable & theElement,LeftistNode * lt=NULL,LeftistNode * rt=NULL,int np=0) :element(theElement),left(lt),right(rt),npl(np){} }; LeftistNode *root; LeftistNode *merge (LeftistNode *h1,LeftistNode *h2); LeftistNode *merge1(LeftistNode *h1,LeftistNode *h2); void swapChildren(LeftistNode *t); void reclainMemory(LeftistNode *t); LeftistNode *clone(LeftistNode *t) const; };
7.合并左式堆的驱动程序和实际程序
void merge(LeftistHeap & rhs)
{
if(this==&rhs)
return;
root=merge(root,rhs.root);
rhs.root=NULL;
}
LeftistNode * merge(LeftistNode *h1,LeftistNode *h2)
{
if(h1==NULL)
return h2;
if(h2==NULL)
return h1;
if(h1->element<h2->element)
return merge1(h1,h2);
else
return merge1(h2,h1);
}
LeftistNode *merge1(LeftistNode *h1,LeftistNode *h2)
{
if(h1->left==NULL)
h1->left=h2;
else
{
h1->right=merge(h1->right,h2);
if(h1->left->npl<h1->right-np1)
swapChildren(h1);
h1->npl=h1->right->npl+1;
}
return h1;
}
8.左式堆的insert程序和deleteMin程序
void insert(const Comparable & x) { root=merge(new LeftistNode(x).root);
}
void deleteMin()
{
if(isEmpty())
throw UnderflowException();
LeftistNode *oldRoot=root;
root=merge(root->left,root->right);
delete oldRoot;
}
void delteMin(Comparable & minItem)
{
minItem=findMin();
deleteMin();
}
9.二项队列不是一棵堆序的树,而是堆序的集合,称为森林(forest)。
10.二项队列类构架及结点定义:
template <typename Comparable>
class BinomialQueue
{
public:
BinomialQueue();
BinomialQueue(const Comparable & item);
BinomialQueue(const BinomialQueue & rhs);
~BinomialQueue();
bool isEmpty() const;
const Comparable & findMin() const;
void insert(const Comparable & x);
void deleteMin();
void deleteMin(Comparable & minItem);
void makeEmpty();
void merge(BinomialQueue & rhs);
const BinomialQueue & operator = (const BinomialQueue & rhs);
private:
struct BinomialNode
{
Comparable element;
BinomialNode *leftChild;
BinomialNode *nextSibling;
BinomialNode(const Comparable & theElement,BinomialNode *lt,BinomialNode *rt)
:element(theElement).leftchild(lt).nextSiblig(rt){}
};
enum {DEFAULT_TREES=1};
int currentSize;
vector<BinomialNode*> theTrees;
int findMinIndex() const;
int capacity() const;
BinomialNode * combineTrees(BinomialNode *t1,BinomialNode *t2);
void makeEmpty(BinomialNode * & t);
BinomialNode * clone(BinomialNode * t) const;
};
11.在STL中,二叉堆是通过称为priority_queue的类模板实现的,该类模板可以在标准头文件queue中找到。STL 实现了一个最大堆而不是最小堆,因此所访问的项就是最大的项而不是最小的项。其键成员函数如下:
void push(const Object & x);
const Object & top() const;
void pop();
bool empty();
void clear();
感谢您的访问,希望对您有所帮助。
欢迎大家关注或收藏、评论或点赞。
为使本文得到斧正和提问,转载请注明出处:
http://blog.csdn.net/nomasp
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。