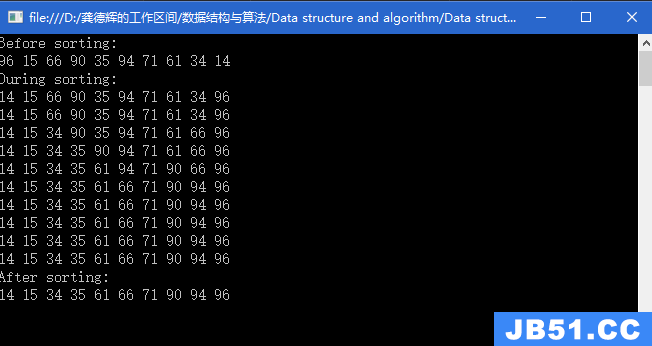
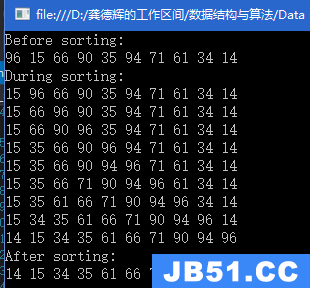
接下来我们讨论下链表的一些高级操作
逆置(循环写法):
public Node reverse(Node head) {
Node reverseHead = null;
Node runner = head;
while (runner != null) {
Node next = runner.next;
runner.next = reverseHead;
reverseHead = runner;
runner = next;
}
return reverseHead;
}
逆置(递归写法):
public static Node reverseRec(Node head) {
if(head==null)
return head;
return reverseRec(head,head.next);
}
public static Node reverseRec(Node prev,Node curr) {
if(curr==null)
return prev;
Node reverseHead = reverseRec(prev.next,curr.next);
curr.next=prev;
prev.next=null;
return reverseHead;
}
合并:
public static void merge(Node head1,Node head2) {
while (head1 != null && head2 != null) {
if (head1.next == null) {
head1.next = head2;
return;
}
Node next = head2.next;
head2.next = head1.next;
head1.next = head2;
head1 = head2.next;
head2 = next;
}
}
删除:
public void deleteNode(Node Delete) {
if (Delete == null || Delete.next == null)
return;
Delete.item = Delete.next.item;
Delete.next = Delete.next.next;
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。