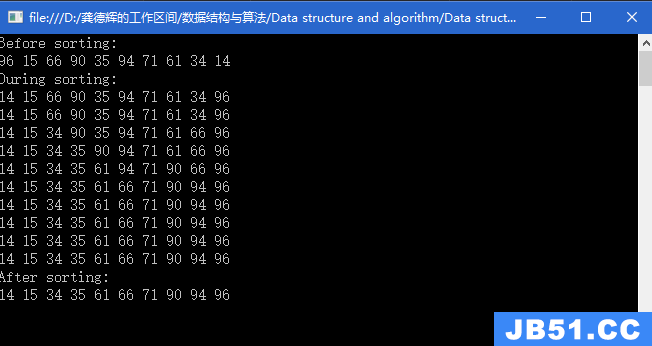
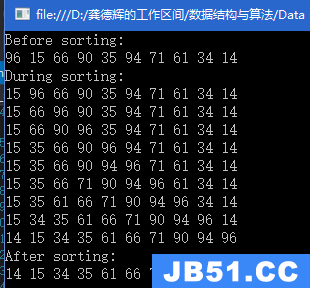
单链表是一种非常适合插入和删除的数据结构,但是查找和修改时间复杂度为O(N)
节点部分:
首先定义一个value来存放值,再定义一个指针来指向下一个节点
int val; Node next;
然后定义构造函数并初始化节点的值
Node(int val) {
this.val = val;
this.next = null;
}
链表部分:
首先定义头指针和尾指针
Node head; Node tail;
然后是基本操作:增删查
头插:
public void insertBefore(Node newNode) {
newNode.next = head;
head = newNode;
}
尾插:
public void insertAfter(Node newNode) {
if (head == null)
head = tail = newNode;
else {
tail.next = newNode;
tail = newNode;
}
}
为什么尾插需要判空而头插不需要?
因为如果tail为空,tail.next必定出现空指针错误。而头插法没有出现head.xxx这样的情况
头删:
public void deleteBefore() {
if (head == null) {
System.out.println("linkedlist is empty");
return;
}
else
head = head.next;
}
尾删:
public void deleteAfter() {
if (head == null) {
System.out.println("linkedlist is empty");
return;
}
if (head.next == null)
head = null;
else {
Node runner = head;
while (runner.next.next != null)
runner = runner.next;
runner.next = runner.next.next;
}
}
我们可以看出,尾删的时间复杂度是最高的,因为要一个while循环来找最后一个元素,所以尽量避免用尾删,后面的栈和队列操作我们会更深入的理解。
public int searchIndex(int value) {
int counter = 1;
Node runner = head;
while (runner != null) {
if (runner.val == value)
return counter;
else {
runner = runner.next;
counter++;
}
}
return -1;
}
根据“节点位置”查找值:
public String searchValue(int index) {
int counter = 1;
Node runner = head;
while (runner != null) {
if (index == counter)
return runner.item;
else {
runner = runner.next;
counter++;
}
}
return "out of index!";
}版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。