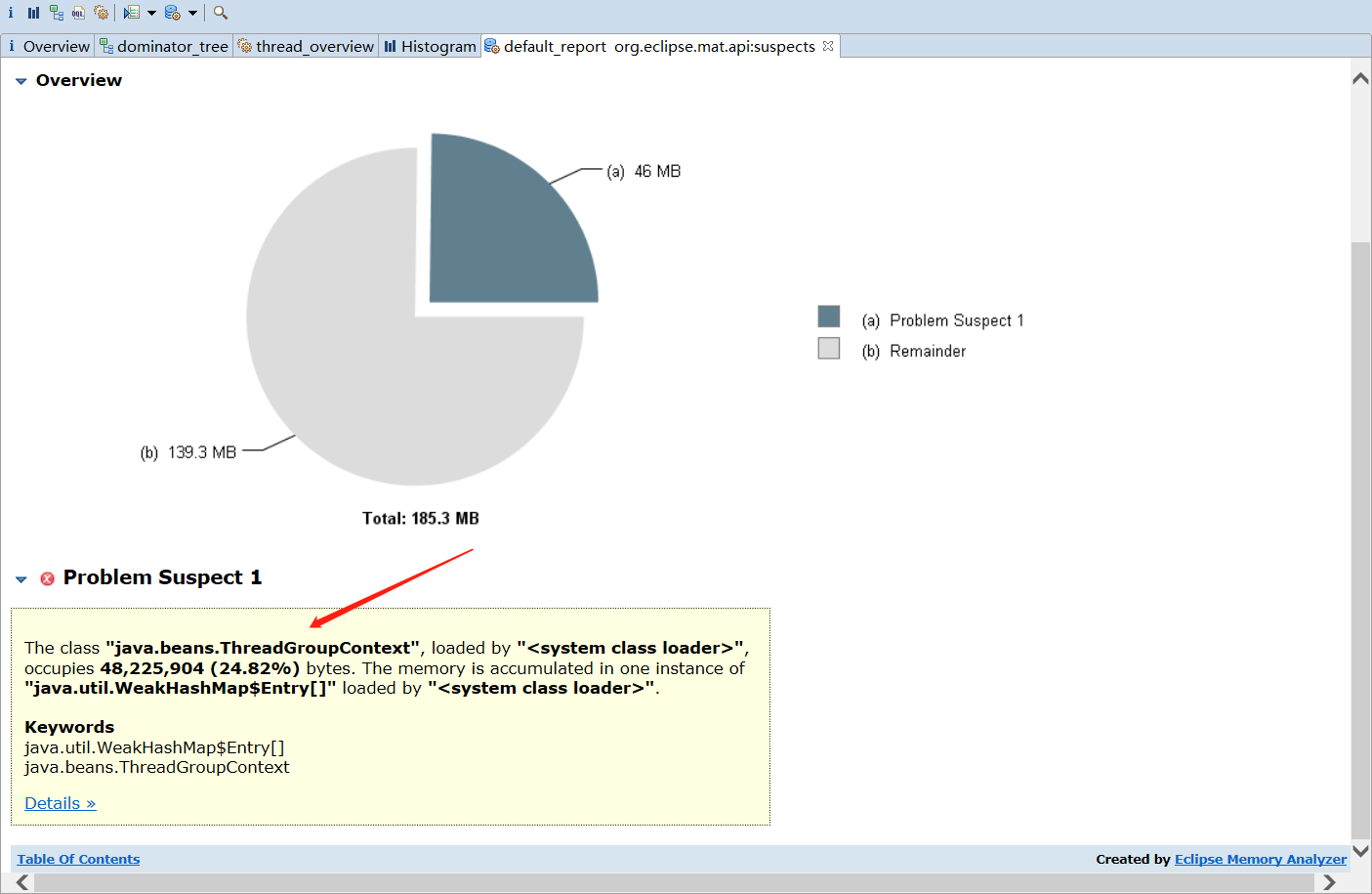
Groovy探索之Expando类
Expando类是Groovy语言中的一个相当有趣的类,它的作用类似于GroovyBean类,但比GroovyBean类更加灵活;同时,它还更类似于Map类,但也比Map类更加灵活。
我们先来看一个简单的例子:
def e = new Expando()
e.name = 'aa'
println e.name
e.age = 123
println e.age
运行结果为:
aa
123
可以看到,e对象就像一个Map对象一样,可以任意的增加键值对,然后存储起来。也像一个动态的GroovyBean对象,它可以不用预先设定任何的属性,一切都可以在使用的时候增加。
它与Map对象的最大不同在于Expando对象除了可以在运行期增加属性以外,还可以动态的增加方法。如:
def person = new Expando()
person.name = 'Alice'
person.age = 18
person.description = {
println """
----------description---------
name: ${person.name}
age: ${person.age}
------------------------------
"""
}
person.description()
在上面的代码中,我们先给Expando类的对象person增加了两个属性“name”和“age”,接着又给person对象增加了一个方法“description”,最后,代码执行了该方法。运行结果为:
----------description---------
name: Alice
age: 18
------------------------------
可以毫不夸张的说,如果没有可以给Expando对象在运行期内动态增加方法的特点,Expando对象将和Map对象的作用一模一样,当然也就没有使用它的必要。正是有了可以动态增加方法的特点,使得Expando对象使用起来比Map对象更加方便。我们可以在很多地方使用到它。
当然,在一般情况下,你完全可以使用Expando对象来代替Map对象使用。而我们下面要说的,却是Expando类比Map类更好用的地方。
在一个项目中,“增删改查”是一个项目的基本功能,其中的查询我们的一般的处理方法是将从数据库获取的数据放在一个JavaBean对象里,然后,再将JavaBean对象的数据显示在页面上。
当然,上面的情况如果在Groovy项目中,则由JavaBean对象变成了GroovyBean对象。
我们假设有如下的一个GroovyBean类:
class Person
{
String name
int age
}
我们使用下面的赋值语句来模拟从数据库获取数据:
person.name = 'Tommy'
person.age = 10
同时,我们也使用下面的语句来模拟将数据显示在页面上:
println "name: ${person.name} age: ${person.age}"
在绝大多数的情况下,使用JavaBean或者GroovyBean对象来存储数据的解决方案是最直接、最简单的方案。但使用JavaBean或者GroovyBean对象来存储数据有一个基本的要求,即从数据库查询出来的数据有固定的字段个数。恰恰在有一些情况下,从数据库查询出来的数据没有固定的字段个数,可能这次查询出来有三个字段,而下次查询出来就有五个字段。在Java项目中,遇到这种情况,我们一般都用Map对象来代替JavaBean对象。现模拟如下:
Map map = new HashMap()
map.name = 'Tommy'
map.age = '10'
map.each{
print "${it.key}: ${it.value} "
}
println()
因为Map对象可以增加任意多的键值对,原则上可以解决上面的动态字段问题。但是上面的Map对象解决方案存在一个问题,即显示数据的顺序问题:很多情况下,我们是要求按从数据库取得数据的顺序来显示数据。如上面的例子中,从数据库中取得的数据的顺序是先是“name”后是“age”,所以要求在显示的时候也是这样的顺序。可以看到,上面的代码是不能解决顺序的问题。
基于上面的原因,我们在Java项目提出来一个妥协的解决方案,即从数据库查询出来的字段以“f1”、“f2”……的形式表示。这样,我们可以给出如下的解决方法:
Map map = new HashMap()
map.f1 = 'Tommy'
map.f2 = '10'
(1..map.size()).each{
print "f${it}: ${map."f${it}"} "
}
println()
可以看到,这个妥协的解决方案勉强解决了顺序的问题,但需要从存储过程或sql语句到Java代码的一系列改动才能达到的。
现在,在Groovy语言中,我们有了Expando类,就再也不需要这样的妥协解决方案了:
def person = new Expando()
person.fields = []
person.addField = {
name ->
person.fields << name
}
person.name = 'Tom'
person.addField('name')
person.sex = 'male'
person.addField('sex')
person.age = 12
person.addField('age')
person.fields.each{
println " ${it}: ${person."${it}"}"
}
前面我们说过,Expando类可以让我们在运行期内增加方法。在上面的代码中,我们增加了一个名为“addField”的方法,用来存储字段的顺序。
在接下来的赋值语句中,我们首先把字段存储在“person”对象中,接着存储该字段的顺序,即:
person.name = 'Tom'
person.addField('name')
在显示数据的时候,我们先从“person”对象的“fields”属性中取出字段的顺序,然后按照这个顺序依次取值。这样就顺序的解决了动态字段显示的所有问题。
上面代码的运行结果为:
name: Tom
sex: male
age: 12
与赋值时候的顺序一样,达到了我们的目的。
通过了上面的一个简单的例子,我们看到Expando类在解决动态性问题上的灵活性。基于它的灵活性,我们可以在很多地方使用到它。如我们可以使用Expando类来做mock测试,限于篇幅,我们就不再做阐述了。
我们只需要知道Expando类的实例可以在运行期内动态的增加属性和方法,就可以在项目中使用到它。如果我们需要一个对象来动态增加属性,那么我们可以使用Map对象或者Expando对象;如果我们需要一个对象,除了能动态的增加属性,还能动态的增加方法,那么我们必须使用Expando对象。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。