

Base64 是一种常见数据编码方式,常用于数据传输。对于移动开发者来讲,网络请求中会经常使用到。对 JSON 熟悉的同学都知道,JSON 的序列化工具都不支持将 byte 数组直接放入 JSON 数据中,针对这种二进制数据,在处理的时候,都需要进行 Base64 编码,然后将编码后的字符串放入到 JSON 中。 从刚入行到现在,Base64 是一个非常常用的功能,从网上“搬运” Base64 编解码工具到使用 Android SDK 中内置的 Base64。虽熟练使用,但终未深入了解 Base64 的底层机制。
巧的是,近期工作中,又遇到了 Base64 的相关事情,于是去相对深入了解了 Base64 的相关内容。以下仅作为自身学习记录。
1. Base64 定义
Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法,用人话讲叫可以把二进制数据打印在控制台上,可以很好的拷贝以及传输。
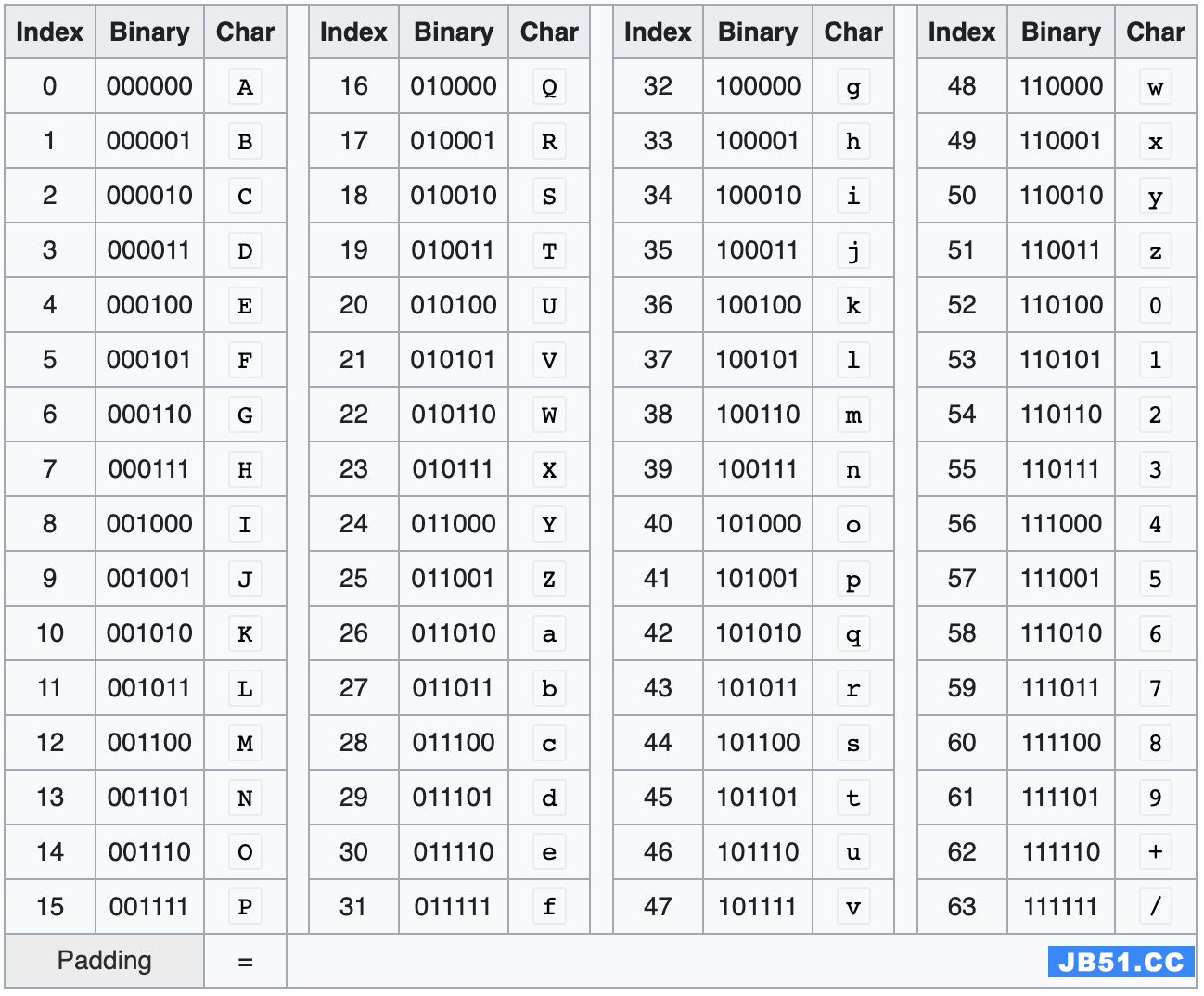
在编码中使用的 64 个可打印字符只需要 6 个 Bit 位就可以表示: 2 6 = 64 2^6 = 64 26=64
在计算机世界中,3 个 Byte 的二进制数据相当于 24 个 Bit , 因此在编码时需要对应 4 个 Base64 的字符来表示。
Base64 的可打印字符集包含了字母 A-Z、a-Z、数字 0-9, 这样就有了 62 个字符,另外两个在不同的系统中可能会不同,我们一般使用的为 + 、 /,在 URL Safe 的模式下为 -、_
Base64 码表:
2. Base64 转换
我们将 byte 数组中的每一个 byte 都转换成 8 位 bit, 组成一串二进制数据,然后按 6 位进行分割,再将每 6 位转换成一个 bit ,将转换后的 bit 作为 index ,去码表中查找对应显示的字符。
编码示例如下:
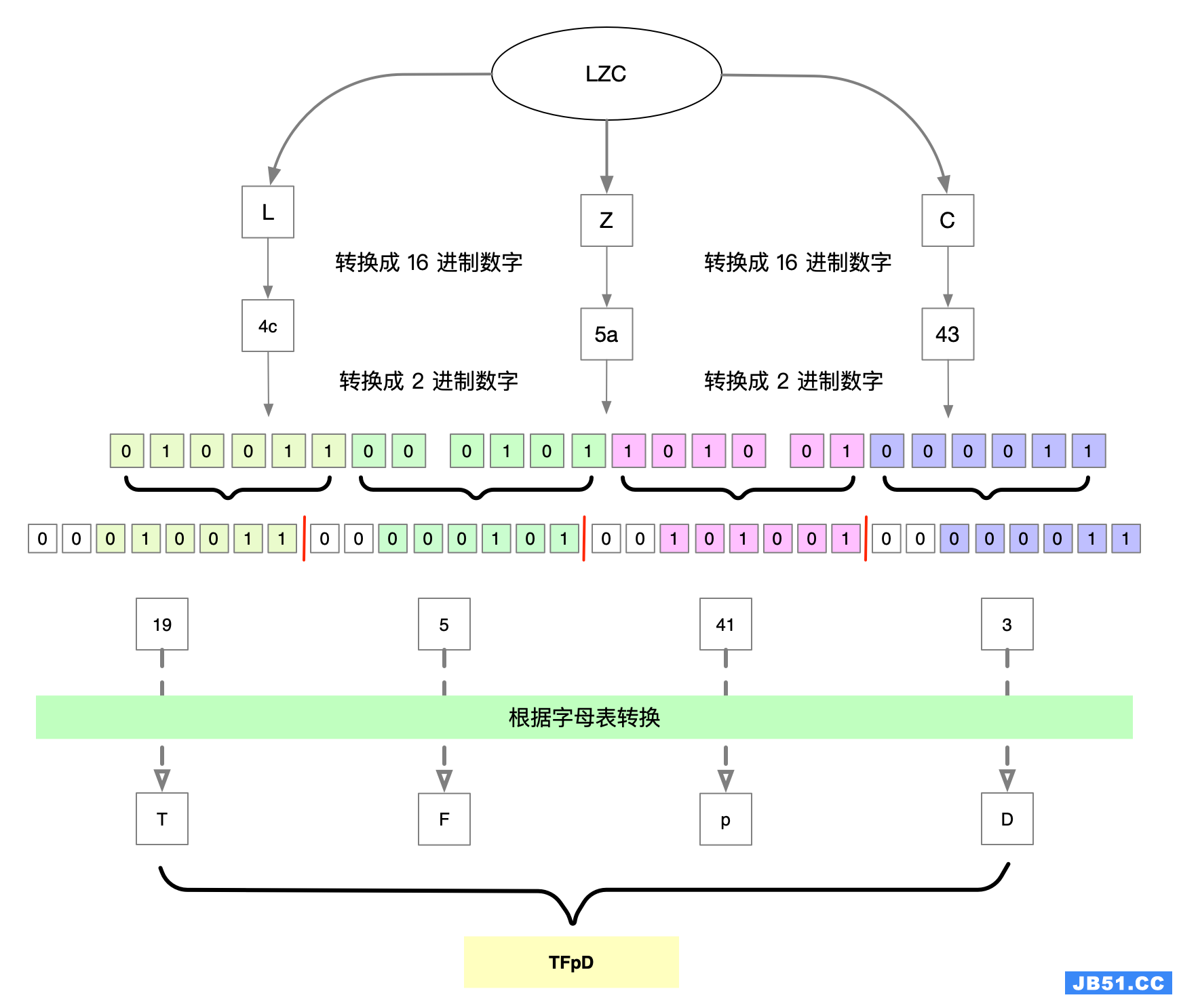
如上图所示,将 LZC 转换成 Base64 编码的可打印的字符串为 TFpD。 从这个示例可以看出来,刚好可以将 3 个 byte 转成 4 个 byte。
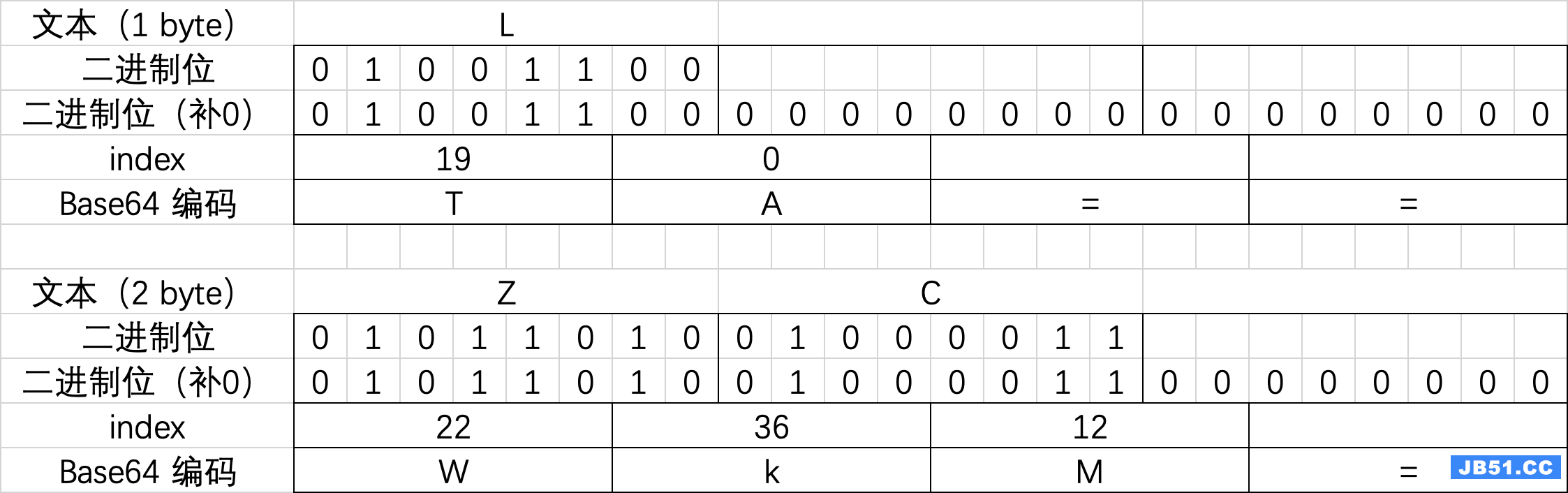
聪明的你可能已经发现存在的问题,如果要编码的原始 byte[] 的长度不能被三整除应该怎么处理呢?
在码表中,除了编码中用到的 64 个字符,在末尾还有一个填充字符: = ,用来填充不足的位数。
举例说明:
3. Base64 encode 代码实现(Java 版)
- 将现有的 3 个 byte
a,b,c编码成 Base64 的串
final char[] base64 = {
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/'
};
byte a = 'L';
byte b = 'Z';
byte c = 'C';
int index1 = (a >> 2) & 0b00111111;
int index2 = ((a << 4) & 0b00110000) | ((b >> 4) & 0b00001111);
int index3 = ((b << 2) & 0b00111100) | ((c >> 6) & 0b00000011);
int index4 = c & 0b00111111;
byte[] result = new byte[]{
(byte) base64[index1], (byte) base64[index2], (byte) base64[index3], (byte) base64[index4]
};
System.out.println(new String(result));
// TFpD
- 将现有的 2 个 byte
a,b编码成 Base64 的串
byte a = 'Z';
byte b = 'C';
int index1 = (a >> 2) & 0b00111111;
int index2 = ((a << 4) & 0b00110000) | ((b >> 4) & 0b00001111);
int index3 = ((b << 2) & 0b00111111);
byte[] result = new byte[]{
(byte) base64[index1], '='
};
System.out.println(new String(result));
// WkM=
- 将现有的 1 个 byte
a编码成 Base64 的串
byte a = 'L';
int index1 = (a >> 2) & 0b00111111;
int index2 = ((a << 4) & 0b00111111);
byte[] result = new byte[]{
(byte) base64[index1], '=', '='
};
System.out.println(new String(result));
// TA==
从代码中,可以看到前文所述的转换步骤。 但在计算 index2 以及 index3 的时候,还是有点绕,有没有更好的计算方式呢?
在 JDK 的 Base64 的实现中,看到了一种新的实现方式。 在 Java 中,一个 int 型的数占 4 个 byte ,因此可以将要转换的 3 位 byte 放在一个 int 数据中。
如下图所示,将 LZC 三个 byte 放入一个 int 型变量中去:

代码实现:
byte a = 'L';
byte b = 'Z';
byte c = 'C';
int bits = (a & 0xFF) << 16 | (b & 0xFF) << 8 | (c & 0xFF);
// 10011000101101001000011
拿到 bits 后,就可以直接进行位运算,取出对应的 4 个 6 位二进制数。 代码实现如下:
// 0x3f == 0b00111111
int index1 = (bits >> 18) & 0x3F;
int index2 = (bits >> 12) & 0x3F;
int index3 = (bits >> 6) & 0x3F;
int index4 = bits & 0x3F;
byte[] result = new byte[]{
(byte) base64[index1], (byte) base64[index4]
};
System.out.println(new String(result));
4. 思考一:Base64 编码一定要添加填充(Padding)吗?
在前文中,对于不足 3 个 byte 的数据转换过程中,需要在编码后的串中加入填充字符 = ,让最后输出的 Base64 的串正好是 4 的整数倍。那么问题来了,为什么要使用 = 号进行填充?不填充可以吗?
在 android.utils.Base64 的实现中,有一个叫 NO_PADDING 的 flag。如果在使用的过程中,传入了这个 flag,最后的输出结果就是没有埋充 = 的结果。 因此,在进行编码的时候,对于不足 3 个 byte 的数据处理时,也可以不进行填充。
当然,如果进行填充,在解码的时候,能够更加简单的去处理,直接将编码的串,4 个字符一组进行处理,而不用判断字符数量,走不同的解码逻辑。当然,Padding 还可以用来标识编码结束,来防止多个 Base64 拼接到一起后,解码失败。
5. 思考二:Base64 是否可以认为是一种加密方式呢?
Base64 是一种编码方式,将原始数据转换成了一种可打印的字符串。 在工作中,也经常会有人称之为 Base64 加密 ,按照 加密 的定义:
以某种特殊的算法改变原有的信息数据,使得未授权的用户即使获得了已加密的信息,但因不知解密的方法,仍然无法了解信息的内容。
对于 Base64 来讲,在使用的过程中,早已经遵从了常用的编码标准: RFC 4648 以及 RFC 2045,使用标准的码表来进行处理,并不能算得上是“加密”,但如果,在进行编解码的过程中,使用特殊的码表,可以让编码的内容不容易被解码出来,也可以实现对原始内容的“加密”功能。
6. 最后
在文中,有关 Base64 的编码过程中的原理以及代码实现都已经存在,如果有兴趣,可以尝试一下去实现解码的代码编写,可以更好的理解其中的原理。 知其然,知其所以然,写代码犹如神助。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

