

作者:程序员阿sir 来源:程序员阿sir

上一篇文章介绍了网络问题。这一篇文章将进一步介绍另一个难题:时2. 时钟问题
1. 时钟问题
时钟对应用而言是非常重要的,很多指标可以通过时钟来衡量。比如每秒的请求数量、平均请求时间等等,这些数据是由时间间隔 (Duration) 来表示的。另一类比如文章发表时间、缓存什么时候过期等等,这些是由时间点 (Points in Time) 来表示的。在分布式系统中,由于请求都是有网络延迟的,我们也不知道网络延迟有多久,所以在涉及到多个机器,每个机器记了一件事情的发生时间,我们可能不能确定事情的发生顺序,因为网络延迟是不确定的,如果是时间非常相近的事件可能还遇到了时钟问题。
另外由于每个机器都有自己的时钟,这个机器时钟由硬件决定,因此可能存在一定的差别。可以通过网络时间协议 (Network Time Protocal) 来缓解时钟不同步的问题,或通过GPS等服务来获取精确的网络时间。
1.1. 单调时钟和墙上时钟 (Monotonic Versus Time-of-Day Clocks)
现代计算机至少包含两种时钟:墙上时钟 (Wall-clock Time)(就是一般的钟表对应的时钟)、单调时钟。本质上他们都表示时间,但是目的不同。
墙上时钟 (Wall-clock Time)
墙上时钟根据日历返回当前的日期和时间,与我们日常理解的时钟概念一致。比如Java中的System.currentTimeMillis()表示从1970年1月1日以来的毫秒数。
墙上时钟通常使用NTP来进行时钟同步,但是如果本地时钟远远快于NTP服务器可能会跳到不正确的时间点。加上墙上时钟忽略了闰秒,导致它不太适合被用于计算时间间隔 (Elapsed Time)。
单调时钟 (Monotonic Clocks)
单调时钟更适合计算时间间隔 (Duration, Time Interval),比如超时时间或者服务器响应时间。比如Java中的System.nanoTime()返回的就是单调时钟。单调时钟保证时间数字总是变大。
如果NTP检测到本地石英比时间服务器上更快或更慢,NTP会调整本地石英的振动频率。默认情况下,NTP允许改变频率的最大幅度是。但是NTP不会直接调整单调时钟的值。单调时钟的精度很高,通常可以测量微秒级别的时间间隔。
注意单调时钟的值没有意义,比较不同节点上的单调时钟的值也没有意义,因为它们表示的含义和基准可能都不相同。一般情况下单调始终用于测量一段任务的持续时间。
1.2. 时钟同步和准确性 (Clock Synchronization and Accuracy)
单调时钟不需要同步,但是墙上时钟需要根据NTP服务器做出调整。但是墙上时钟和NTP也很可能无法对准,比如由于石英钟本身的震荡漂移 (Drifts)或者NTP同步时的网络延迟等等。数据表明,当通过网络进行时间同步时,误差至少达到35毫秒,最差时的误差甚至超过1秒。另外某些用户可能故意调整本地时钟,设置为错误的日期(比如为了规避游戏的时间检查等等)。因此墙上时钟可能是非常不准确的。
如果一个问题是依赖于时钟同步的,那我们需要考虑如果不同步会对应用带来哪些问题。
比如一个常见的问题是:跨节点的事件排序。如果它高度依赖于时钟同步,就可能导致问题。比如下面的例子:
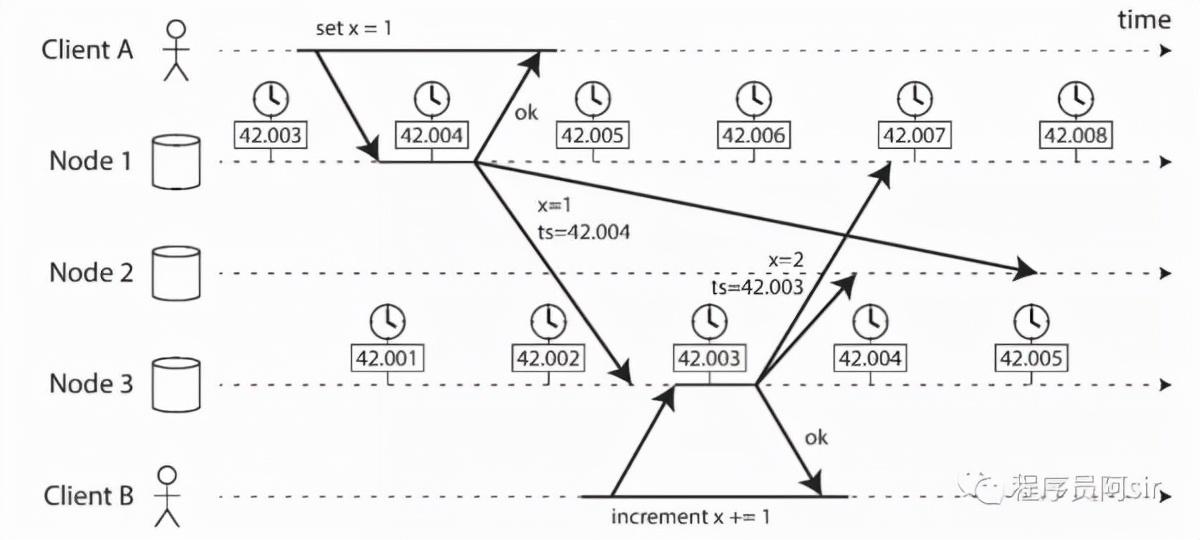

另一个使用时钟可能导致问题的例子是:假设数据库每个分区只有一个主节点,只有主节点可以接受写入。那么其他节点该如何确信当前主节点还是主节点呢?一种思路是主节点从其他节点获取一个租约 (Lease),当租约没有超时的时候,则当前节点可以处理请求,否则不可以。伪代码如下:
while (true) {
request = getIncomingRequest();
// Ensure that the lease always has at least 10 seconds remaining
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000) {
lease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
} 如果当前租约还是有效的,离结束还有13秒,而 lease.isValid()消耗了15秒,这样当 process(request) 开始执行时,租约已经过期了,可能其他节点成为了主节点。这样就导致当前节点不是主节点,但是依然执行了处理写入请求的操作。这就导致了问题。
而这种情况可能是由于进程暂停 (Process Pause)导致的。可能由于很多原因导致进程暂停,比如垃圾回收 (GC)。
总结
分布式系统可能遇到网络问题、时钟问题等。而且分布式系统的关键特点就是部分失效。所以在分布式环境下,我们的目标就是建立一个能够容忍部分失败的软件系统。为了做到这一点,首先要先能检测错误,这个也不简单,因此分布式算法大多依赖超时来确定服务是否正常。但是超时无法区分是网络问题还是节点故障。如果因为临时的网络原因被误认为是发生了节点故障,就导致这个节点被“冤枉”了,可能造成服务不稳定。
检测到错误之后,系统如何能容忍错误也是一个难题。在分布式环境里,各个节点之间都是通过网络来进行通信的,而网络本身就不可靠。因此单个节点可能不能做出正确的决策,需要多个节点共同投票来进行决策。
参考文献
[1] Kleppmann, Martin. Designing data-intensive applications: The big ideas behind reliable, scalable, and maintainable systems. " O'Reilly Media, Inc.", 2017.
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

