大家好!我是陈国庆,今天是圣诞节,首先祝大家节日快乐。今天我主要讲两个方面的内容,一是Nosql的应用场景,另一个是Cassandra架构实现分析。作为一个Nosql非常接触的应用,我们分析它的架构,看看它怎么做的。看看它的可操作一致性等等的优点。
为了让大家很清楚的了解Nosql,我们先从sql开始。它就是我们说的关系数据库,优点非常明显,经过关系的直观表达,本身我们的现实世界里面就是一个关系世界,所以用关系世界表达我们这个逻辑,也比较容易理解。另外对这种关系数据库而言,发展的时间比较长,针对我们应用方而言有比较成熟的产品和工具,给了我们很大的便利。
关系数据库或者Nosql最核心是四个元素,就是我们经常听说的ACID。这个意思是很清楚,就是它的原则性、事务性、格力性还有自由性。其实对关系数据而言应该是强调它的一致性。
关系数据库我们都很清楚,如果我的数据量比较大,会怎么扩展呢?一般有三个阶段,第一个就是一个单Master数据库加一个备份就可以了。再进一步比如我的数据库比较大,一个数据库肯定搞不定的,我们可以做一个Master这个模式。比如说很多业务场景写的比较少,读的比较多,这样我把写做Master读的话Slave,这样达到最终的一致性。第三个如果我写的比较多,单纯的Master的模式是不能胜任的,可以进行系统性能、伸缩性,一般是垂直扩展,是通过内存、硬盘或者cpu垂直扩展。垂直扩展的好处也是非常清楚的,不影响你现在的应用。这个方向实际就是之前大家讨论的超级计算的方向,就是你的硬件再好可能跟不上你的数据库,所以我们还是从软件上考虑,就是我们说的水平扩展。水平扩展是Sharding,对这种水平扩展也是有比较老的技术了,很多年前已经有人用了,可以由三种模式,比如我可以基于我的功能,把单独的功能用一个数据库,不同的功能不同的数据库,eBay号称自己就是这样做的。这个功能是很清楚,一定程度上还可以包括你ACID的属性。这种也是有一定的业务场景,可能eBay这样的很适合,但其他的可能不是很适合,可能我的技术比较单一,这样就可以用Key的这种,这个模式也比较简单,比如我插入的时候就可以看这个应该插入哪一个数据库。这种场景用的比较多,不管是阿里巴巴还是淘宝还是别的公司都有这样的产品。第三个用的比较少,我分片的时候,可能会有一个服务器记录着,比如说这条记录是处在哪个数据库当中,这种做法很显然是一个单点的问题,实际用的比较少。但本身也是有优点的,数据量比较少的时候也是可以考虑的。其实我们讨论的这些每个都有优点缺点,不是哪个就一定好,哪个就一定差。
现在我们再讨论一下,现在的做法存在什么问题,因为有问题,我们就思考是不是有什么方式可以取代。这种Master/Slave模式的话,Master是一个单点,因为它跟Slave之间是一个单向,另外数据同步可能有时间的差距。水平扩展也是有一定的局限性的,无事务支持,sql访问的速度慢,然后他的一致性很强,可用性很差。每一个设备到点的话,可能就不可访问了。还有一个我们关系数据库可以解决一大部分问题,但有一些不是关系数据库,比如说一棵树,还有一个图,或者一个对象,这些都是非结构化的东西,不太会用这个关系深刻的反应出内在最本质的东西。
我们接下来请问Nosql是什么?这个业内比较认同的说法Nosql就是对sql的一个增强。Nosql是什么呢?是两件事情,首先是一个名字,这个名字本身是从09年开始火热,一直持续到现在。另外一个它本身是一种事情,一种做法,这个做法本身09年前已经开始了。这个名字的原因很多人认为Nosql就是为了做这种存储。后面我们也看到了,Nosql用处很多,有自己不同的应用场景,不是每个都适合的,大数据量、并发也不是每个都要那么大的伸缩性。
现在Nosql的产品已经太多了,随便找一下可能找到四五十个,上百个。我这边罗列了几个比较有代理行行业的领域。稍微简单的解释一下,CouchDB是俄文写的做稳当的数据,HBase是一个分布数据库。这个Tamio/Exist这是一个商业产品,做的非常悠久。Dynamo是亚马逊,他的作者就是从亚马逊出来的。MongoDB现在是比较热的,号称是Nosql里面排名第一位的,是一个文档数据。下面的Neo4j可以说是一个图形引擎,处理图形点对点非常复杂的关系。Objectivity/DB这个就是面向对象的数据库。这是其中很少的一部分,市场上可能有一百个,产品是非常多。面对这么多的产品,我们怎么去选呢?我们怎么结合我们使用哪一种产品呢?
其实万变不离其宗,我们不可能每个Nosql都试一边。所有的Nosql从理论上来讲都是基于一种CAP里面的,我们也说是分布式领域的奠基之作。其实你把握住大的使用场景,对你的抉择会起到非常大的帮助。我们有三个方面,一个是理论,还有Nosql本身的数据模型,还有你自己本身的业务场景。从这方面来让你自己感觉怎样选择。大家有什么问题可以提问一下。CAP理论,大家也比较清楚了,就是根据几十年前那些研究机构做分布式的时候,发现对一个分布式系统而言,比较重要的三点就是一致性、可用性还有它的分区容错性。所有的分布式而言,一致性是最根本的,只要分了区一致性就很难保证了。
但是返过来讲,如果有一个单点,所有的分布式就没了。如果有单点就形成一个单点可用性的问题了。根据CAP三者只有坚固其二,从这个图上我们可以看到三个会相交,但三个同有一个公共的区域。前面的Nosql都是做不同的抉择。CAP对它的选择是选择其二吗?肯定是一个两两的组合。如果选择了CA的话,你会放弃你的分区。强调一致性和分区容错性的话,就要放弃可用性。假如说网络断掉别的机房可能会继续服务,那时候就放弃可用性。AP是强调可用性跟分区容错性,放弃一致性,现在很多Nosql都是弱化了一致性。这种系统高可用,高容错,即使断掉起火也无所谓,单用户插入一个东西查不出来。但为了解决这个问题,最终一次性的解决方案,可能暂时性是不一致的,最后会通过一个方式达到这个系统最终的一致性。
如果我们通过CAP划分一下,就可以看到Nosql分成了三种,就是三个的两两组合。所以通过这个图就很清楚你的业务场景到底选择哪两样,可以再看哪些产品是你要推荐的。从CAP里面延伸出一个BASE,就是基本可用软状态的最终一致性。实际就是对CAP里面A跟P的延伸,就是对这两个进行了更加清楚的定义。我看到它的用处,多数用在异步处理上,通过异步处理来达到最终的一致。
比如说我们两个阶段的提交,其实是属于强一致性的。比如说之前的图,一个客户端可能访了两个数据库,通过两个阶段的提交,要保证这两个数据库都成功了之后。这样客户端的可用性依赖于两个DB同时成功,最后也是跟两个DB都有关的。如果BASE的话,我可以先DB1进行数据通信,DB1跟2通过协调的方式大同,这样可用性就上去了。就是只要DB1成功就成功了。
上面我们讲了CAP和BASE。接下来我们看一下每种Nosql有不同的数据模型,我们看一下这几个适用的场景。像Cassandra数据库是采取K-V的方式,适合什么呢?适合大数据量、密集写、高扩展性。CovchDB是稳当数据库,可以快速的数据福祉,更强调是移动里面的数据同步。MongoDB,它的更新速度是很慢的,可以快速度曲、支持产查询、索引,可替换sql。Tamino是XML的类型,它适合是企业内部、低访问量、灵活扩展的属性。Handlersql这个前面已经讲过了,它是K-V形式的写入,通过MysqL结构化的输出。下面那种对象存储,必须面向对象的语言,Neo4J的话就是大量复杂、互联节、低结构化的图数据。有了个模型之后再看业务场景,是需要哪种模型处理逻辑。
Nosql这个名字我们怎么觉得呢?最终还是你的业务场景,Nosql这个已经被用烂掉了,现在这个名字不要谈这个名字,要找出各个产品之间的差别,前段时间CouchDB说已经不叫Nosql了,因为这个名字掩盖了他这个本身的很多特点。以注重Web前端。你知道这一点之后对你还是很有帮助的。
另外很多Nosql产品以前很早就存在了,只是Nosql在2009年又活跃起来。现在Nosql的团购都在做,眉佳都在做着重复的工作,最后可能剩不了几家,但Nosql的话,最终的结果也会一样的。只有非常少数的,技术非常优秀的可以走到最后,其他的大多数都会淘汰。坚决不选择稳定性差,没有任何技术含量的产品。
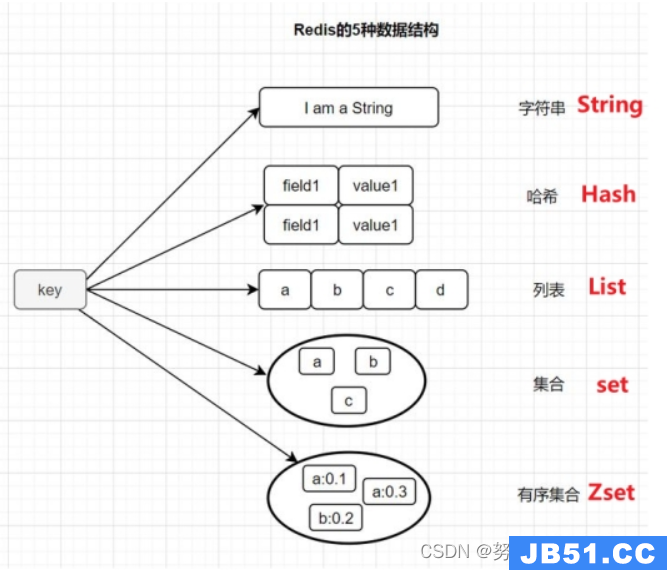
下面我们来分析Cassandra里面的一个代表,看看他是怎么做的。Cassandra一直强调自己有四个特性,分布式、趋中心化、弹性扩展、高可用性、容错、可调节的一致性。我们先说全球数据结构,有几个概念是列,行。说到行,很多人说Cassandra是基于列的存储,其实Cassandra做的本身与不同于这点,强调与是行存储。因为这里还是有行的概念,这个行没有具体的数据结构,只是列了一个集合可以定为一行。每一行的Key有主键。还有一个列主,还有一个Keyspace,这些概念大概是对应过去。
需要说明一点的是,这个行在存的时候,是已经排好序的。取的时候是有顺序的,这个取的性能是比较高的。因为Cassandra是适合高伸缩性的架构。一般来说几百台,随时一台可以崩掉,可以新增加一个进去。他是怎样把数据分布在整个集群上呢?就是他的节点的分布结构,它有一个节点环。
因为它的高伸缩性,也就是区中心化,我们这个节点频繁的加入和推出,这个非常像B2B里面,电脑下载东西的时候,其实构成一个虚拟的网,每个人都是一个节点,频繁在里面加入和退出。这个加入和退出的复杂度有一个衡量指标。比如我们的节点2跟节点4中间加入节点5,节点5做什么呢?就把以前节点2跟节点4上的数据重新分布,其他的数据节点数据都是不用动的。这就是一致性哈希。非一致性哈希就是加入这个节点以后所有的都变了。随着这个扩容做不断的重新哈希。通过这种一致性哈希也保证了它的去中心化,加入和退出都是一样的。
这里面就有一个比较重要的问题,这个环是都必须存在,节点之间需要某种技术来同步。接下来我们就介绍一种算法,Gossip,这个在英文里面就是一个神话。这个算法是基于这种场景,比如说我说办公室里面的闲言碎语,我说一下这个人怎样,他说一下,一会儿大家全知道了,很快。跟传染病疫情传播是一样的,一会儿大家都知道了。便是基于老外写的一篇论文,又称疫情传播算法。它的做法是每个阶段,有可能有新节点加入,他可以随即选择一个节点同步。在对数级别当中达到所有的节点一致。这个有三种类型,推、拉、结合。推的意思意思就是我把我本地所有的Key、版本号比较。拉的话就是为了节省带宽,因为一秒钟同步一次,对带宽要求还是很高的,这不是业务数据了是通信的数据。拉的意思就是在推的时候是推Key,A推给B,B收到之后他会发现我本地哪些Key你比推过来的新,对A来讲就是两个来回,回去又回来。这个结合的时候,A推给B,然后同时请求A把A的数据再给B。根据这个算法论文里面的介绍,推的速度没有拉的快,拉的速度没有推拉节省的速度快。所以就选择了第三个,一秒一个。它也是比较适合要求不是很强的场景。
它怎么来保证,比如说写结点的时候,可能会写几个,读的时候怎么能保证你最新写入的一次性的策略?大家也听说过NWR法则,亚马逊公司创造的。怎么说呢?比如说我写入一处,我希望数据复制三份,N就是我复制几个节点,W写入几个节点,R就是我读取节点数,这就是可条有理智性的,只要保证W+R>N,则提高强一执行,保证一定能读取到新写入的值通过异步复制到底最终一致性。一般N=3,W=2,R=2。
存储策略,怎么保证我的数据不丢呢?或者说为什么说自己是高写入的策略呢?它的几个概念,CommitLog,是数据优秀同步写如到CommitLog,可用来恢复数据,CommitLog只能追加,如果CommitLog位于单独的卷,则减少磁盘寻址时间,保证为顺序写入。在写入CommitLog之后会被写入内存。内存在一定的条件下,比如说大小,当内存开始忙的时候,会把数据批量刷新到sstable,就是一个硬盘的文件,这时候重新再开一个。第一个会批量刷新,所以把随即的IO,变位顺序的IO。一旦写入这个文件之后,sstable是不允许修改的,修改也作为追加写,所以他的写性是非常优秀。一个多个Memtable可以对应一个列组。同一Column Family可以形式很多的sstable。
那查询数据,你可以根据非常多的朝找你想要的key是不是有。这时候有一个Bloom Filter算法,这个算法就是比如我们通过5个哈希函数,映射到位数组里面去,就是计算机里面的一个位。另外一个key重新进行连续的映射,如果每位都为1则断言key属于这个集合,如果不是1的话也可能是,为什么呢?因为key之间存在着Hash碰撞,本来两个key哈希值是一样的。就是不同的key有一个相同的哈希值。这种算法是结果不要求很精确的场景。比如sstable搜索,它是一种非常快的节省空间的算法。
当我们这个sstable数据量比较大的时候,Cassandra会定期对sstable做合并操作。数据修复的问题,因为它的一致性可以调的,当你读两个节点数据的时候,你发现1上跟2上反应出来的板块是不一致的,一个是新,一个是旧,不说明,肯定是旧的没有获得最新的版本,这个是数据修复的问题。数据修复的话,面对这么多含量的数据不可能比对。所以我们就是要哈希数,我把所有的数据做一个叶子节点,上面负节点的值就是叶子,当我比较两个数据是不是一致的时候,就从底层比较这个哈希。就可以很快的比较出来到底是哪个数据不一致,就做成有针对性的。
这样我们在Cassandra比较短的时间里面不会让大家很清楚它的架构,就是一些大的设计上面,分析一下通过哪种手段保证它的目标。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。