
2、锻炼分析问题、解决问题并动手实践的能力。
实 验 环 境:
Anaconda
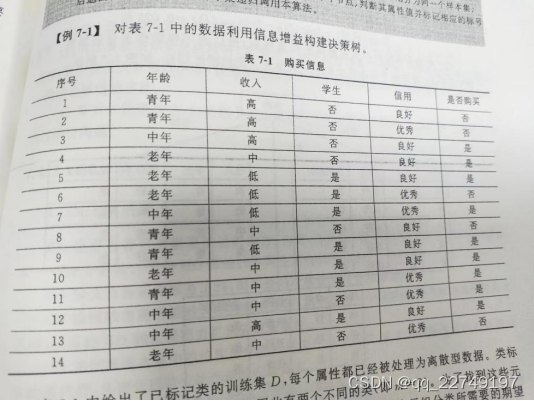
代码实现如下:

年龄:0代表青年,1代表中年,2代表老年;
收入:0代表低,1代表中;2代表高
是否是学生:0代表否,1代表是;
信用情况:0代表良好,1代表优秀;
是否购买:no代表否,yes代表是。
2.1 ID3算法概述
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。
具体方法是:从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。
2.2 递归终止条:
(2)使用完所有即当前属性集为空,仍不能将数据集划分成仅包含唯一类别的分组,则挑选出现次数最多的类别作为返回值。
代码实习如下:

其中涉及到信息熵的计算:信息熵函数calcShannonEnt(),定义如图1,建树过程中的需按照给定特征划分数据集,定义函数如图2,在计算信息熵后我们也许建立信息增益最大的(最优)特征的索引值,定义函数如图3,同时我们也需统计classList中出现此处最多的元素(类标签)。如图4。



图3
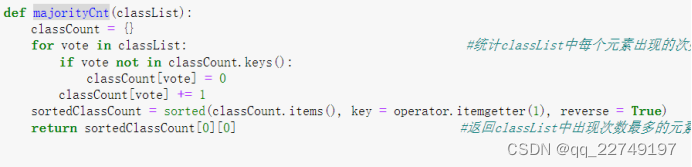
图4
3、决策树的分类:
利用已经生成的决策树、存储选择的最优特征标签和测试数据列表,顺序对应最优特征标签得出分类结果。
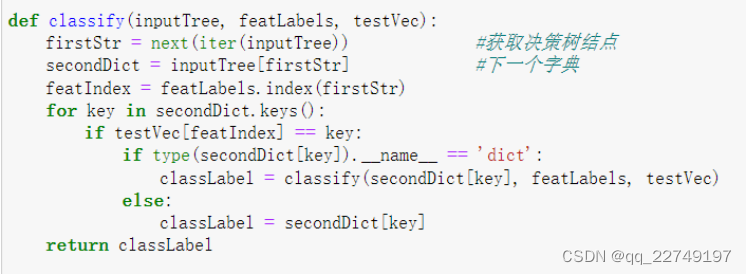
4、可视化显示
①获取决策树叶子结点的数目(图5)
②获取决策树的层数(图6)
③绘制结点(图7)
④标注有向边属性值(图8)
⑤绘制决策树(图9)
⑥创建绘制面板(图10)

图5

图6

图7

图8
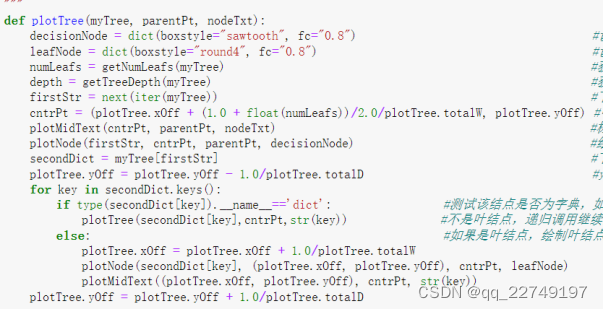

图10
结果展示:

实 验 心 得:
本次实验中采用的是ID3决策算法,基本搞懂了本例中的决策树算法原理,其实构建决策树的核心问题是在每一步如何选择恰当的属性对样本进行差分,我们这个算法中就利用信息熵的最大来进行属性选择度量。在网上对决策树的进一步学习中,我发现决策树的缺点竟然是容易过拟合,而剪枝可以解决这个问题。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。