

单行函数
格式
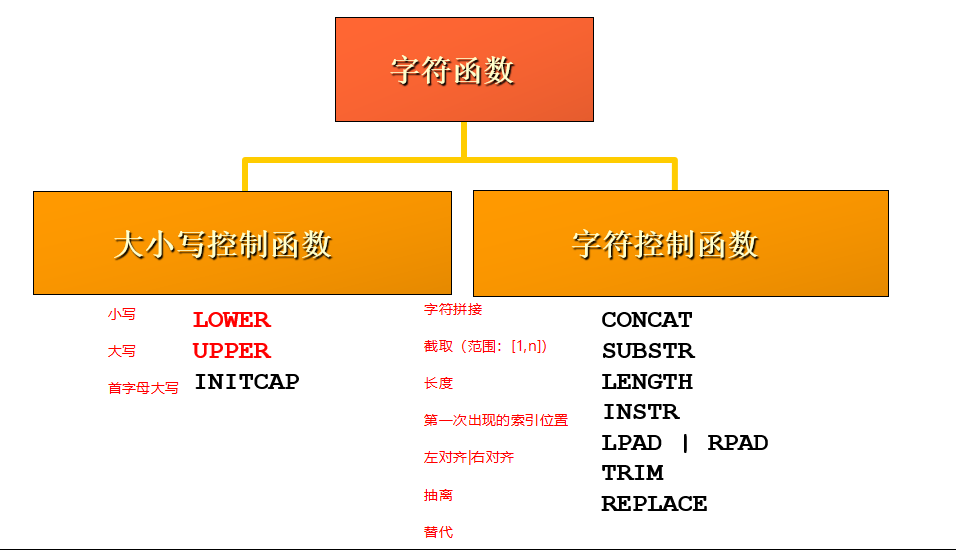
字符函数
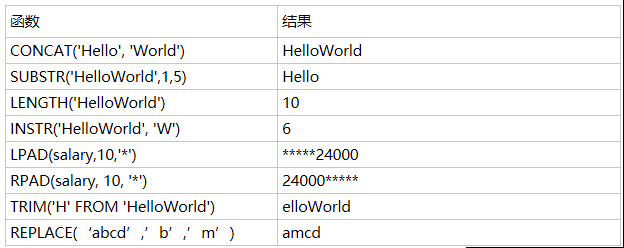
数字函数


Trunc: 截断
Trunc(45.926, 2) 45.92

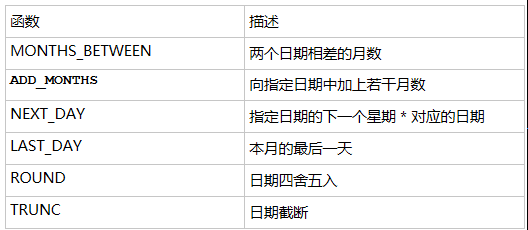
日期函数
Oracle 中的日期型数据实际含有两个值: 日期和时间
日期默认格式:DD-MON月-RR
• 在日期上加上或减去一个数字结果仍为日期。
• 两个日期相减返回日期之间相差的天数。
• 日期间不允许做加法运算,无意义
• 可以用数字除24来向日期中加上或减去天数


注意分钟是mi
显示转换函数

to_char
对金额


-- $000,123.14
SELECT TO_CHAR(123.14, '$000,000.99') from dual;
-- $123.14 select TO_CHAR(123.14,'$999,999.99') from dual; -- ¥000,123.14 SELECT TO_CHAR(123.14, 'L000,000.99') from dual;
对日期



-- 2022-08-21 05:13:36
SELECT TO_CHAR(sysdate,'yyyy-mm-dd hh:mi:ss') FROM dual;
-- 2022-08-21 17:15:59
SELECT TO_CHAR(sysdate,'yyyy-mm-dd hh24:mi:ss') FROM dual;
其他可参考:https://www.cnblogs.com/yuan88008/p/15597988.html
条件函数
NVL (expr1, expr2) 前面为空,用后面替代
NVL2 (expr1, expr2, expr3) expr1不为空,expr2,为空则exper3
NULLIF (expr1, expr2) 相等返回Null,不等返回expr1
COALESCE (expr1, expr2, ..., exprn) expr1为空则判断expr2,知道不为空就返回
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
含义:
IF 条件=值1 THEN
RETURN(翻译值1)
ELSIF 条件=值2 THEN
RETURN(翻译值2)
......
ELSIF 条件=值n THEN
RETURN(翻译值n)
ELSE
RETURN(缺省值)
END IF
行转列函数
pivot
语法
SELECT * FROM (数据查询集)
PIVOT
(
SUM(score/*行转列后 列的值*/) FOR
coursename/*需要行转列的列*/ IN (转为列的值[ as 列名])
)
eg:
sql> SELECT job 2 , deptno 3 , SUM(sal) AS sum_sal 4 FROM emp 5 GROUP BY 6 job 7 , deptno 8 ORDER BY 9 job 10 , deptno;
JOB DEPTNO SUM_SAL --------- ---------- ---------- ANALYST 20 6600 CLERK 10 1430 CLERK 20 2090 CLERK 30 1045 MANAGER 10 2695 MANAGER 20 3272.5 MANAGER 30 3135 PRESIDENT 10 5500 SALESMAN 30 6160
sql> WITH pivot_data AS ( 2 SELECT deptno, job, sal 3 FROM emp 4 ) 5 SELECT * 6 FROM pivot_data 7 PIVOT ( 8 SUM(sal) --<-- pivot_clause 9 FOR deptno --<-- pivot_for_clause 10 IN (10,20,30,40) --<-- pivot_in_clause 11 );
JOB 10 20 30 40 --------- ---------- ---------- ---------- ---------- CLERK 1430 2090 1045 SALESMAN 6160 PRESIDENT 5500 MANAGER 2695 3272.5 3135 ANALYST 6600 5 rows selected.
pivot_clause:定义要聚合的列(pivot 是聚合操作)
pivot_for_clause:定义要分组和旋转的列;
pivot_in_clause:为 pivot_for_clause 中的列定义过滤器(即限制结果的值范围)。 pivot_in_clause 中每个值的聚合将被转置到单独的列中(在适当的情况下)。
对pivot函数的理解:对于非pivot_for_clause列来说,按其所对应pivot_for_clause列的值pivot_in_clause来分组,计算后的值pivot_clause为 (pivot_in_clause值作为的)新列下的新值,
非pivot_for_clause列拥有所有这些(不同pivot_in_clause)作为的新列,即便有些新列下的值为空,因为非pivot_for_clause列对应的pivot_for_clause列下可能没有pivot_in_clause中的某些值
隐含分组-》按非pivot_for_clause列非pivot_clause列进行分组,再按pivot_in_clause值对pivot_clause进行分组聚合
分组函数
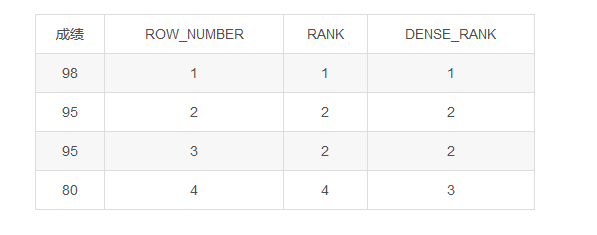
分组排序 :
ROW_NUMBER() OVER (PARTITION BY 字段1 ORDER BY 字段2 DESC) , 顺序: 1,2,3,4...n
RANK() OVER(PARTITION BY 字段1 ORDER BY 字段2 DESC), 相同的为同一序次,且下一个依旧按照总的顺序,即序号不连续,会发生跳跃 :1,2,3,3,3,6,7...n
DENSE_RANK() OVER(PARTITION BY 字段1 ORDER BY 字段2 DESC),区别于rank是序号始终连续,不会发生跳跃 : 1,2,2,2,3,4....n
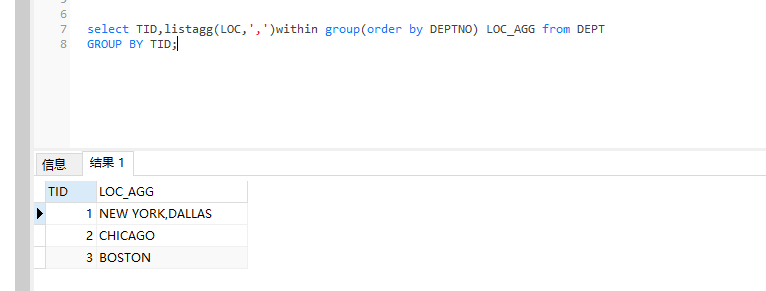
分组聚合拼接某列值
LISTAGG函数可以指定具有相同属性的数据进行拼接 行转列
listagg(要行转列聚合的列的列名,‘分隔符’)within group(order by 按照该列排序的列名) , 配合group by使用=》分组聚合行转列

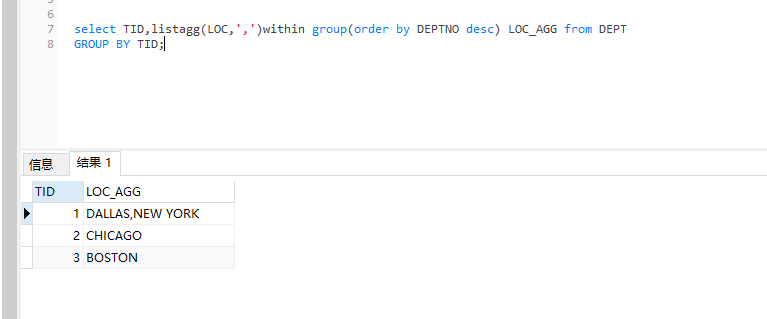
select TID,listagg(LOC,',')within group(order by DEPTNO) LOC_AGG from DEPT
GROUP BY TID;
order by 倒序
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

