


xcel等类库就方便多了,其中POI最为出色。
POI具有全面而细致的xls读写能力
POI可读写多种Excel文件格式,既支持古老的二进制格式(xls),也支持现代的OOXML格式(xlsx),既支持全内存一次性读写,也支持小内存流式读写。POI为大量Excel元素设计了相应的java类,包括workbook、printer、sheet、row、cell,其中,与cell相关的类包括单元格样式、字体、颜色、日期、对齐、边框等。仅单元格样式类,方法就超过了四十个,可进行最全面最细致的读写操作。
POI的读写功能很底层
POI的读写功能全面而细致,但细致也意味着过于底层,开发者必须从头写起,自己处理每一处细节,即使简单的操作也要编写大量代码。比如,读入首行为列名的行式xls:
FileInputStream fileInputStream = new FileInputStream("d:\\Orders.xls");
// get the excel book
Workbook workbook = new hssfWorkbook(fileInputStream);
if (workbook != null) {
// get the first sheet
Sheet sheet = workbook.getSheetAt(0);
if (sheet != null) {
//get the col name/first line
Row rowTitle = sheet.getRow(0); // first line
if (rowTitle != null) {
int cellTitles = rowTitle.getPhysicalNumberOfCells(); // get column number
for (int i = 0; i < cellTitles; i++) {
Cell cell = rowTitle.getCell(i); //the cell!
if (cell != null) {
System.out.print(cell.getStringCellValue() + " | ");
}
}
}
//get the value/other lines
int rows = sheet.getPhysicalNumberOfRows(); // get line number
for (int i = 1; i < rows; i++) {
Row row = sheet.getRow(i); // get row i
if (row != null) {
int cells = row.getPhysicalNumberOfCells(); // get column number
for (int j = 0; j < cells; j++) {
// line number and row number
System.out.print("[" + i + "-" + j + "]");
Cell cell = row.getCell(j); // the cell!
if (cell != null) {
int cellType = cell.getCellType();
Object value = "";
switch (cellType) {
case hssfCell.CELL_TYPE_STRING: // string
value = cell.getStringCellValue();
break;
case hssfCell.CELL_TYPE_BLANK: // 空
break;
case hssfCell.CELL_TYPE_BOOLEAN: // boolean
value = cell.getBooleanCellValue();
break;
case hssfCell.CELL_TYPE_NUMERIC: // number
if (hssfDateUtil.isCellDateFormatted(cell)) { // date number
Date date = cell.getDateCellValue();
value = new DateTime(date).toString("yyyy-MM-dd HH:mm:ss");
}else { // normal number
// change to string to avoid being too long
cell.setCellType(hssfCell.CELL_TYPE_STRING);
value = cell;
}
break;
case hssfCell.CELL_TYPE_ERROR:
throw new RuntimeException("data type mistaken");
}
System.out.println(value);
}
}
}
System.out.println("end of the "+i+" line");
}
System.out.println("end of the value lines=======================================");
}
}
行式xls是最常见的格式,但POI并没有为此提供方便的处理方法,只能按照workbook->sheet->line->cell的顺序进行循环解析,造成了如此繁琐的代码。
这还只是将数据简单读出来,如果下一步想再处理数据,还要事先转为结构化数据对象,比如ArrayList<实体类>或HashMap,代码就更繁琐了。
POI查询计算困难
解析Excel并不是目标,我们通常还要对这些文件进查询计算,但POI作为Excel的解析类,没有也不合适再提供相关的方法,只能用JAVA手工硬写。比如基础的分组汇总运算,JAVA代码大概这样:
Comparator<salesRecord> comparator = new Comparator<salesRecord>() {
public int compare(salesRecord s1,salesRecord s2) {
if (!s1.salesman.equals(s2.salesman)) {
return s1.salesman.compareto(s2.salesman);
} else {
return s1.ID.compareto(s2.ID);
}
}
};
Collections.sort(sales,comparator);
ArrayList<resultRecord> result=new ArrayList<resultRecord>();
salesRecord standard=sales.get(0);
float sumValue=standard.value;
for(int i = 1;i < sales.size(); i ++){
salesRecord rd=sales.get(i);
if(rd.salesman.equals(standard.salesman)){
sumValue=sumValue+rd.value;
}else{
result.add(new resultRecord(standard.salesman,sumValue));
standard=rd;
sumValue=standard.value;
}
}
result.add(new resultRecord(standard.salesman,sumValue));
Java编码实现计算不仅繁琐,而且存在架构性缺陷。代码很难复用,数据结构和计算代码通常会耦合在一起,如果数据结构发生变化,代码就要重写。查询计算的要求灵活多变,而Java作为编译型语言,每次修改代码都要重启应用,维护工作量大,系统稳定性差。
POI成熟稳定,但读写能力过于底层,且未提供查询计算能力,直接基于POI完成Excel文件的处理(特别是查询计算)的开发效率很低。如果针对POI进行封装,形成简单易用的高级读写函数,并额外提供查询计算能力,就能大幅度提高开发效率了。
esProc SPL就是其中的佼佼者。
SPL内置高级读写函数
SPL是JVM下开源的计算引擎,它对POI也进行了封装,内置简单易用的高级函数,可解析\生成各类格式规则或不规则的xls,并自动生成结构化数据对象。
解析格式规则的行式Excel,SPL提供了T函数。比如解析前面的xls文件,用封装前的POI要几十行,封装后只要一句:
=T(“d:\Orders.xls”)
解析行式Excel是很常见的任务,SPL用T函数封装了POI的功能,接口简单易用。无论xls还是xlsx,T函数都可以统一解析。可自动进行类型转换,开发者无须在细节浪费时间。T函数可自动区分首行的列名和其他行的数据,并根据列名创建序表(SPL的结构化数据对象)并填入数据:

读入并解析成序表后,就可以使用SPL提供的丰富的结构化数据处理方法了:
取第3条记录:A1(3)
取后3条记录:A1.m([-1,-2,-3])
取记录的字段值:A1(3).Amount*0.05
修改记录的字段值:A1(3).Amount = A1(3). Amount*1.05
取一列,返回集合:A1.(Amount)
取几列,返回集合的集合:A1.([CLIENT,AMOUNT])
追加记录:A1.insert(200,“APPL”,10,2400.4,date(“2010-10-10”))
先按字段取再按记录序号取:A1.(AMOUNT)(2);等价于先按记录序号取再按字段取:A1(2).AMOUNT
解析格式较不规则的行式xls,SPL提供了xlsimport函数,内置丰富而简洁的读取功能:
没有列名,首行直接是数据:file(“D:\Orders.xlsx”).xlsimport()
跳过前2行的标题区:file(“D:/Orders.xlsx”).xlsimport@t(;,3)
从第3行读到第10行:file(“D:/Orders.xlsx”).xlsimport@t(;,3:10)
只读取其中3个列:file(“D:/Orders.xlsx”).xlsimport@t(OrderID,Amount,OrderDate)
读取名为"sales"的特定sheet:file(“D:/Orders.xlsx”).xlsimport@t(;“sales”)
函数xlsimport还具有读取倒数N行、密码打开文件、读大文件等功能,这里不再详述。
解析格式很不规则的xls,SPL提供了xlscell函数,可以读写指定sheet里指定片区的数据,比如读取第1个sheet里的A2格:
=file(“d:/Orders.xlsx”).xlsopen().xlscell(“C2”)
配合SPL灵活的语法,就可以解析自由格式的xls,比如将下面的文件读为规范的二维表(序表):
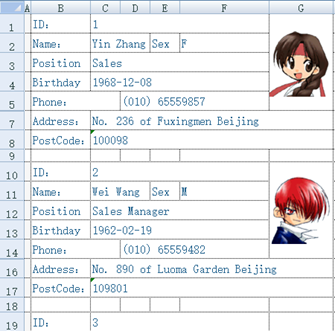
这个文件格式很不规则,直接基于POI写Java代码是个浩大的工程,而SPL代码就简短得多:
| A | B | C | |
| 1 | =create(ID,Name,Sex,Position,Birthday,Phone,Address,PostCode) | ||
| 2 | =file("e:/excel/employe.xlsx").xlsopen() | ||
| 3 | [C,C,F,D,C] | [1,2,3,4,5,7,8] | |
| 4 | for | =A3.(~/B3(#)).(A2.xlscell(~)) | |
| 5 | if len(B4(1))==0 | break | |
| 6 | >A1.record(B4) | ||
| 7 | >B3=B3.(~+9) | ||
生成规则的行式xls,SPL提供了xlsexport函数,用法也很简单。比如,上面例子的解析结果是个序表,存在SPL的A1格中,下面将A1写入新xls的第一个sheet,首行为列名,只要一句代码:=file(“e:/result.xlsx”).xlsexport@t(A1)
xlsexport函数的功能丰富多样,可以将序表写入指定sheet,或只写入序表的部分行,或只写入指定的列:=file(“e:/scores.xlsx”).xlsexport@t(A1,No,Class,Maths)
xlsexport函数还可以方便地追加数据,比如对于已经存在且有数据的xls,将序表A1追加到该文件末尾,外观风格与原文件末行保持一致:=file(“e:/scores.xlsx”).xlsexport@a(A1)
不规则片区写入数据,可以使用前面的xlscell函数。比如,xls中蓝色单元格是不规则的表头,需要在相应的白色单元格中填入数据,如下图:
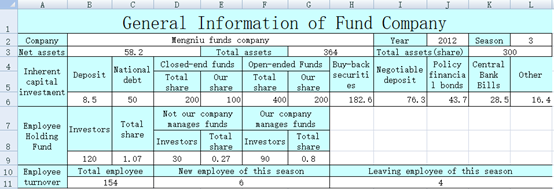
| A | B | C | D | E | F | |
| 1 | Mengniu Funds | 2017 | 3 | 58.2 | 364 | 300 |
| 2 | 8.5 | 50 | 200 | 100 | 400 | 200 |
| 3 | 182.6 | 76.3 | 43.7 | 28.5 | 16.4 | |
| 4 | 120 | 1.07 | 30 | 0.27 | 90 | 0.8 |
| 5 | 154 | 6 | 4 | |||
| 6 | =file("e:/result.xlsx") | =A6.xlsopen() | ||||
| 7 | =C6.xlscell("B2",1;A1) | =C6.xlscell("J2",1;B1) | =C6.xlscell("L2",1;C1) | |||
| 8 | =C6.xlscell("B3",1;D1) | =C6.xlscell("G3",1;E1) | =C6.xlscell("K3",1;F1) | |||
| 9 | =C6.xlscell("B6",1;[A2:F2].concat("\t")) | =C6.xlscell("H6",1;[A3:E3].concat("\t")) | ||||
| 10 | =C6.xlscell("B9",1;[A4:F4].concat("\t")) | =C6.xlscell("B11",1;[A5:C5].concat("\t")) | ||||
| 11 | =A6.xlswrite(B6) | |||||
注意,第6、9、11行有连续单元格,SPL可以简化代码一起填入,POI只能依次填入。
SPL提供足够的查询计算能力
查询计算是Excel处理任务的重点,SPL提供了丰富的计算函数、字符串函数、日期函数,以及标准sql语法,不仅支持日常的xls计算,也能计算内容不规则的xls和逻辑复杂的xls。
SPL提供了丰富的计算函数,可直接完成基础计算。比如前面的分组汇总,只要一句:
A1.groups(SellerId;sum(Amount))
更多计算:
条件查询:A1.select(Amount>1000 && Amount<=3000 && like(Client,“S”))
排序:A1.sort(Client,-Amount)"
去重:A1.id(Client)"
关联两个xlsx:join(T(“D:/Orders.xlsx”)
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

