

为什么要学习pandas?
那么问题来了:
numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
numpy能够帮我们处理处理数值型数据,但是这还不够, 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
所以,pandas出现了。
什么是Pandas?
Pandas的名称来自于面板数据(panel data)
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
官网:
http://pandas.pydata.org/
是数据清洗的重要过程,可以按索引对齐进行运算,如果没对齐的位置则补NaN,最后也可以填充NaN
Series的对齐运算
1. Series 按行、索引对齐
示例代码:
s1 = pd.Series(range(10, 20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
print('s1: ' )
print(s1)
print('')
print('s2: ')
print(s2)
运行结果:
s1:
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
s2:
0 20
1 21
2 22
3 23
4 24
dtype: int64
2. Series的对齐运算
示例代码:
# Series 对齐运算
s1 + s2
运行结果:
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
dtype: float64
DataFrame的对齐运算
1. DataFrame按行、列索引对齐
示例代码:
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])
df2 = pd.DataFrame(np.ones((3,3)), 'b', 'c'])
print('df1: ')
print(df1)
print('')
print('df2: ')
print(df2)
运行结果:
df1:
a b
0 1.0 1.0
1 1.0 1.0
df2:
a b c
0 1.0 1.0 1.0
1 1.0 1.0 1.0
2 1.0 1.0 1.0
2. DataFrame的对齐运算
示例代码:
# DataFrame对齐操作
df1 + df2
运行结果:
a b c
0 2.0 2.0 NaN
1 2.0 2.0 NaN
2 NaN NaN NaN
填充未对齐的数据进行运算
1. fill_value
使用add,sub,div,mul的同时,通过fill_value指定填充值,未对齐的数据将和填充值做运算
示例代码:
print(s1)
print(s2)
s1.add(s2, fill_value = -1)
print(df1)
print(df2)
df1.sub(df2, fill_value = 2.)
运行结果:
# print(s1)
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
# print(s2)
0 20
1 21
2 22
3 23
4 24
dtype: int64
# s1.add(s2, fill_value = -1)
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 14.0
6 15.0
7 16.0
8 17.0
9 18.0
dtype: float64
# print(df1)
a b
0 1.0 1.0
1 1.0 1.0
# print(df2)
a b c
0 1.0 1.0 1.0
1 1.0 1.0 1.0
2 1.0 1.0 1.0
# df1.sub(df2, fill_value = 2.)
a b c
0 0.0 0.0 1.0
1 0.0 0.0 1.0
2 1.0 1.0 1.0
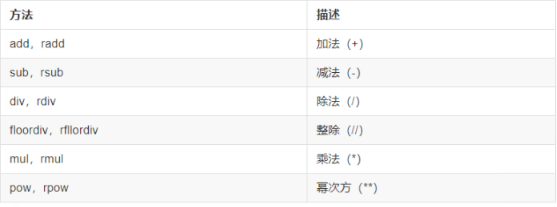
算术方法表:
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

