

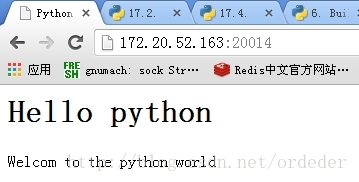
1.浏览器中输入网站地址:172.20.52.163:20014
2.server接到浏览器的请求后,读取本地的index.html文件的内容,回发给浏览器
代码实现
server.py
#!/usr/bin/python import socket import signal import errno from time import sleep def HttpResponse(header,whtml): f = file(whtml) contxtlist = f.readlines() context = ''.join(contxtlist) response = "%s %d\n\n%s\n\n" % (header,len(context),context) return response def sigIntHander(signo,frame): print 'get signo# ',signo global runflag runflag = False global lisfd lisfd.shutdown(socket.SHUT_RD) strHost = "172.20.52.163" HOST = strHost #socket.inet_pton(socket.AF_INET,strHost) PORT = 20014 httpheader = '''''\ HTTP/1.1 200 OK Context-Type: text/html Server: Python-slp version 1.0 Context-Length: ''' lisfd = socket.socket(socket.AF_INET,socket.soCK_STREAM) lisfd.bind((HOST,PORT)) lisfd.listen(2) signal.signal(signal.SIGINT,sigIntHander) runflag = True while runflag: try: confd,addr = lisfd.accept() except socket.error as e: if e.errno == errno.EINTR: print 'get a except EINTR' else: raise continue if runflag == False: break; print "connect by ",addr data = confd.recv(1024) if not data: break print data confd.send(HttpResponse(httpheader,'index.html')) confd.close() else: print 'runflag#',runflag print 'Done'
index.html
<html> <head> <title>Python Server</title> </head> <body> <h1>Hello python</h1> <p>Welcom to the python world</br> </body> </html>
测试
测试结果:
root@cloud2:~/slp/pythonLearning/socket# ./server_v1.py
connect by ('172.20.52.110',6096)
GET / HTTP/1.1
Host: 172.20.52.163:20014
Connection: keep-alive
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/33.0.1750.154 Safari/537.36
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
浏览器
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持编程小技巧。
您可能感兴趣的文章:
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

