

robots.txt是搜索引擎收录网站的一个全球化的标准协议文件,我们可以通过robots.txt对搜索引擎的蜘蛛进行约束,允许它访问那些目录,不允许它访问那些目录文件等等。
robots.txt协议文件的作用
Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接。方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。
robots.txt必须存在吗?
如果你想搜索引擎收录你网站全部内容,你可以不写这个文件。如你网站不存在robots.txt,搜索引起会默认你允许索引网站全部内容。
如果你网站有相应的文件或者目录不想被搜索引擎索引,那么就建议创建robots.txt文件,并进行相关约束,具体robots.txt的使用方法请看下面介绍。
robots.txt文件的基本语法格式
User-agent: *
disallow:
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
robots.txt文件的使用范例介绍
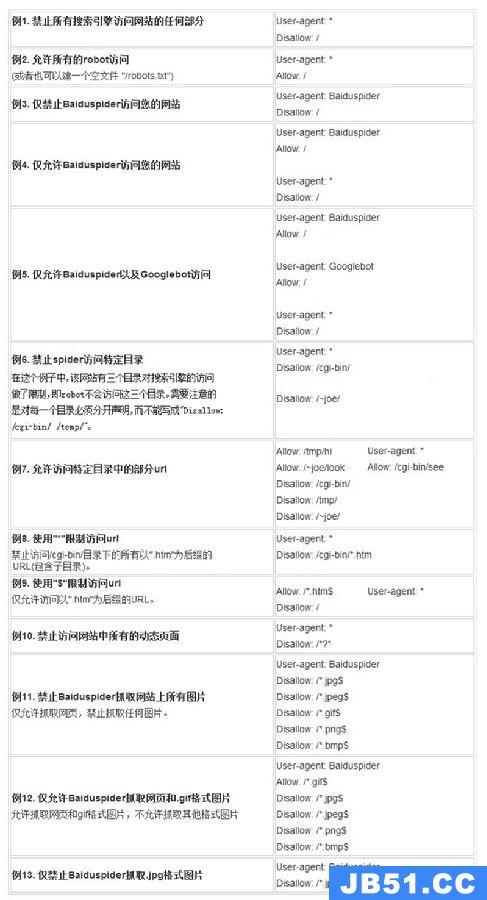
例1. 禁止所有搜索引擎访问网站的任何部分User-agent: *disallow: /例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file)User-agent: *Allow:/例3. 禁止某个搜索引擎的访问User-agent: BadBotdisallow: /例4. 允许某个搜索引擎的访问User-agent: Baiduspiderallow:/例5.禁止搜索引擎访问3个目录在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。需要注意的是对每一个目录必须分开声明,而不要写成 “disallow: /cgi-bin/ /tmp/”。User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“disallow: /tmp/*” or “disallow:*.gif”这样的记录出现。User-agent: *disallow: /cgi-bin/disallow: /tmp/disallow: /~joe/robots.txt百度官方语法大全
青岛星网robots.txt使用分析
青岛星网robots地址请点击:http://www.qdxw.net/robots.txt
User-agent: *
disallow:/public/down.asp
disallow:/search.asp
青岛星网禁止所有搜索引起访问 /public/目录下的down.asp文件,禁止所有搜索引起访问跟目录下的search.asp文件。
robots.txt的注意事项
robots.txt文件名必须是全小写
有多项设置的时候,必须分开写,一行一个设置
最好下载一份语法大全,对照着写,不然很容易出错,可能造成严峻的问题
最后如果你网站设置了robots.txt,可以登录百度站长工具,Robots文件检查,会自动检查你网站Robots文件,并给与正确错误提示哦。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

