

配套资料,免费下载
链接:https://pan.baidu.com/s/1la_3-HW-UvliDRJzfBcP_w
提取码:lxfx
复制这段内容后打开百度网盘手机App,操作更方便哦
第一章 Stream介绍
1.1、什么是Stream
Spring Cloud Stream用官方的话来说就是:他是一个构建消息驱动微服务的框架,他能为一些消息中间件供应商的产品提供了个性化的自动化配置实现,引用了发布/订阅、消费组、分区这三个核心概念,目前支持的产品主要是:RabbitMQ和Kafka。
Spring Cloud Stream用一句话来概括就是:屏蔽消息中间件底层的差异,用于统一消息的编程模型,降低切换消息中间件的成本。
官方文档手册:https://docs.spring.io/spring-cloud-stream/docs/3.0.10.RELEASE/reference/html/
1.2、为啥用Stream
在微服务的开发过程中,可能会经常用到消息中间件,通过消息中间件在服务与服务之间传递消息,不管你使用的是哪款消息中间件,比如RabbitMQ还是Kafka,那么消息中间件和服务之间都有一点耦合性,这个耦合性就是指,如果我原来使用的RabbitMQ,现在要替换为Kafka,那么我们的微服务都需要修改,变动会比较大,因为这两款消息中间件有一些区别,如果我们使用Spring Cloud Stream来整合我们的消息中间件,那么这样就可以降低微服务和消息中间件的耦合性,做到轻松在不同消息中间件间切换,当然目前Spring Cloud Stream只支持RabbitMQ和Kafka。
按照官方的定义,Spring Cloud Stream 是一个构建消息驱动微服务的框架。Spring Cloud Stream解决了开发人员无感知的使用消息中间件的问题,因为Spring Cloud Stream对消息中间件的进一步封装,可以做到代码层面对消息中间件的无感知,甚至于动态的切换中间件(RabbitMQ切换为Kafka),使得微服务开发的高度解耦,服务可以关注更多自己的业务流程。
第二章 Stream重要概念
2.1、基本流程
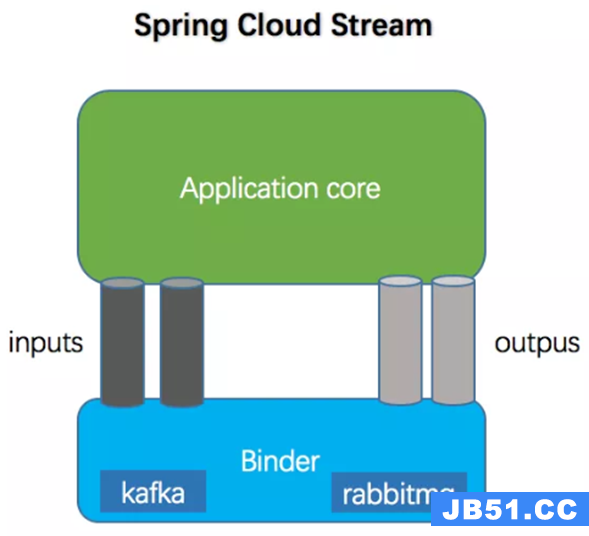
应用程序通过input(相当于消费者consumer)、output(相当于生产者producer/提供者provider)来与Spring Cloud Stream中Binder交互,而Binder负责与消息中间件交互,因此,我们只需关注如何与Binder交互即可,而无需关注与具体消息中间件的交互。

Binder
Binder是应用与消息中间件之间的封装,目前实现了Kafka和RabbitMQ的Binder,通过Binder可以很方便的连接中间件,可以动态的改变消息类型(对应于Kafka的topic,RabbitMQ的exchange),这些都可以通过配置文件来实现。
Channel
通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过对Channel对队列进行配置。
Source
Source用于实现了消息发布,由服务内的Spring完成。
Sink
Sink用于监听进入Channel的消息并将其反序列化。
2.2、常用注解
| 注解 | 说明 |
|---|---|
| @Input | 该注解标识输入通道,通过该输入通道接收消息进入应用程序 |
| @Output | 该注解标识输出通道,发布的消息将通过该通道离开应用程序 |
| @StreamListener | 监听队列,用于消费者的队列的消息接收 |
| @EnableBinding | 将信道 channel 和 exchange 绑定在一起 |
2.3、其他术语
发布/订阅
简单的讲就是一种生产者,消费者模式。发布者是生产,将输出发布到数据中心,订阅者是消费者,订阅自己感兴趣的数据。当有数据到达数据中心时,就把数据发送给对应的订阅者。
消费组
直观的理解就是一群消费者一起处理消息,需要注意的是:每个发送到消费组的数据,仅由消费组中的一个消费者处理。而不同消费组可以处理相同的数据。
分区
类比于消费组,分区是将数据分区。举例:某应用有多个实例,都绑定到同一个数据中心,也就是不同实例都将数据发布到同一个数据中心。分区就是将数据中心的数据再细分成不同的区。为什么需要分区?因为即使是同一个应用,不同实例发布的数据类型可能不同,也希望这些数据由不同的消费者处理。这就需要消费者可以仅订阅一个数据中心的部分数据,这就需要分区了。
第三章 Stream入门案例
3.1、项目准备与启动
我们接下来的所有操作均是在Sleuth+Zipkin最后完成的工程上进行操作,相关代码请到配套资料中寻找。

注意:这一章节我们需要使用RabbitMQ,而RabbitMQ的学习与搭建与启动,请参考:https://caochenlei.blog.csdn.net/article/details/112549952
我们需要启动注册中心,启动顺序如下:
- eureka-server7001
- eureka-server7002

我们接下来还需要启动RabbitMQ,并进入控制台进行相应的查看,查看地址:http://localhost:15672,登录账户:guest,登录密码:guest


3.2、创建消息生产者
(1)在父项目spring-cloud-study下创建一个子项目stream-rabbitmq-provider2001
(2)在子项目stream-rabbitmq-provider2001的pom.xml中导入如下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
(3)在子项目stream-rabbitmq-provider2001中新建配置文件application.yaml并写入如下配置:
server:
port: 2001
eureka:
instance:
#是否使用 ip 地址注册
prefer-ip-address: true
#该实例注册到服务中心的唯一ID
instance-id: ${spring.cloud.client.ip-address}:${server.port}
client:
#是否将自己注册到注册中心,默认为 true
register-with-eureka: true
#表示 Eureka Client 间隔多久去服务器拉取注册信息,默认为 30 秒
registry-fetch-interval-seconds: 10
#设置服务注册中心地址
service-url:
defaultZone: http://root:123456@eureka-server7001.com:7001/eureka/,http://root:123456@eureka-server7002.com:7002/eureka/
spring:
application:
name: stream-rabbitmq-provider2001
#Stream核心配置如下:
cloud:
stream:
binders:
rabbit: #绑定消息中间件的名称,自定义
type: rabbit #绑定消息中间件的类型,固定值
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings:
#消息生产者的设置选项
output:
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要传送的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
(4)在子项目stream-rabbitmq-provider2001中新建启动类com.caochenlei.StreamRabbitmqProvider2001Application并写入如下代码:
@SpringBootApplication
public class StreamRabbitmqProvider2001Application {
public static void main(String[] args) {
SpringApplication.run(StreamRabbitmqProvider2001Application.class, args);
}
}
(5)创建消息生产者com.caochenlei.message.ProviderSender
@EnableBinding(Source.class)
public class ProviderSender {
@Autowired//定义消息发送管道,名字只能叫output
private MessageChannel output;
public void send() {
String uuid = UUID.randomUUID().toString();
//核心代码:构建一个消息类型,然后使用发送管道发送出去
output.send(MessageBuilder.withPayload(uuid).build());
System.out.println("send:" + uuid);
}
}
(6)创建一个控制器com.caochenlei.controller.ProviderController
@RestController
public class ProviderController {
@Autowired
private ProviderSender sender;
@RequestMapping("/send")
public void send() {
sender.send();
}
}
(7)启动stream-rabbitmq-provider2001,然后打开eureka注册中心查看注册,查看地址:http://localhost:7001,登录账号:root,登录密码:123456

(8)我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send

(9)我们查看一下RabbitMQ的控制台,请在浏览器地址输入:http://localhost:15672/#/exchanges,登录账号:guest,登录密码:guest

3.3、创建消息消费者
(1)在父项目spring-cloud-study下创建一个子项目stream-rabbitmq-consumer2002
(2)在子项目stream-rabbitmq-consumer2002的pom.xml中导入如下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
(3)在子项目stream-rabbitmq-consumer2002中新建配置文件application.yaml并写入如下配置:
server:
port: 2002
eureka:
instance:
#是否使用 ip 地址注册
prefer-ip-address: true
#该实例注册到服务中心的唯一ID
instance-id: ${spring.cloud.client.ip-address}:${server.port}
client:
#是否将自己注册到注册中心,默认为 true
register-with-eureka: true
#表示 Eureka Client 间隔多久去服务器拉取注册信息,默认为 30 秒
registry-fetch-interval-seconds: 10
#设置服务注册中心地址
service-url:
defaultZone: http://root:123456@eureka-server7001.com:7001/eureka/,http://root:123456@eureka-server7002.com:7002/eureka/
spring:
application:
#集群环境下名称应该保持一致,这样才能使用Eureka的负载均衡
name: stream-rabbitmq-consumer
#Stream核心配置如下:
cloud:
stream:
binders:
rabbit: #绑定消息中间件的名称,自定义
type: rabbit #绑定消息中间件的类型,固定值
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings:
#消息消费者的设置选项
input:
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要接收的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
(4)在子项目stream-rabbitmq-consumer2002中新建启动类com.caochenlei.StreamRabbitmqConsumer2002Application并写入如下代码:
@SpringBootApplication
public class StreamRabbitmqConsumer2002Application {
public static void main(String[] args) {
SpringApplication.run(StreamRabbitmqConsumer2002Application.class, args);
}
}
(5)创建消息消费者com.caochenlei.message.ConsumerReceiver
@EnableBinding(Sink.class)
public class ConsumerReceiver {
@Value("${server.port}")
private String serverPort;
@StreamListener(Sink.INPUT)
public void receive(Message message) {
System.out.println(serverPort + " receive:" + message.getPayload());
}
}
(6)启动stream-rabbitmq-consumer2002,然后打开eureka注册中心查看注册,查看地址:http://localhost:7001,登录账号:root,登录密码:123456
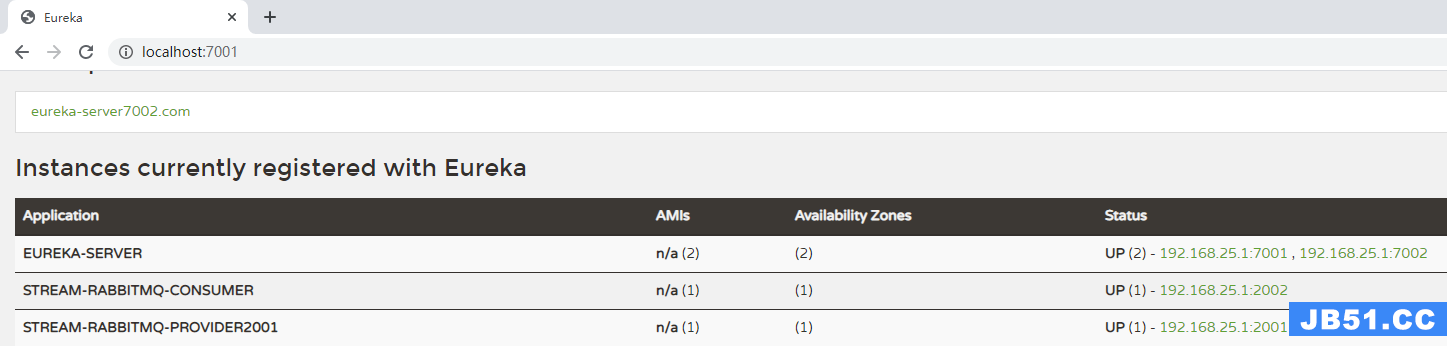
(7)我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send,然后查看stream-rabbitmq-consumer2002控制台

第四章 Stream自定义管道名
4.1、分析stream源码
在前面的案例中,我们已经实现了一个基础的Spring Cloud Stream消息传递处理操作,但在操作之中使用的是系统提供的 Source (output)、Sink(input),接下来我们来看一下自定义管道名称是怎么实现的,在此之前,我们需要先分析源码。
Source.class
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
从这里我们不难看出,默认的发送管道名就是output,因此我们在使用发送管道发送消息时,名称必须叫output
@Autowired//定义消息发送管道,名字只能叫output
private MessageChannel output;
Sink.class
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}
从这里我们不难看出,默认的接收管道名就是input,因此我们在使用接收管道接收消息时,名称必须叫input
@StreamListener(Sink.INPUT)
public void receive(Message message) {
System.out.println(serverPort + " receive:" + message.getPayload());
}
我们要是想要实现自己定义的管道名,我们可以照猫画虎,分别写两个接口,就照抄源码,改改默认名称,然后在使用的时候换上咱们自己的就行了。
4.2、修改消息生产者
(1)自定义一个Source(com.caochenlei.message.MySource)
public interface MySource {
String OUTPUT = "myOutput";
@Output("myOutput")
MessageChannel output();
}
@EnableBinding(MySource.class)
public class ProviderSender {
@Autowired//使用自定义的管道名myOutput
private MessageChannel myOutput;
public void send() {
String uuid = UUID.randomUUID().toString();
//核心代码:构建一个消息类型,然后使用发送管道发送出去
myOutput.send(MessageBuilder.withPayload(uuid).build());
System.out.println("send:" + uuid);
}
}
(3)修改配置文件application.yaml绑定管道的名称
#局部配置,请对应修改,其他地方保持不变
bindings:
#消息生产者的设置选项
myOutput: #修改管道的名称,不是output了
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要传送的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
(4)重新启动stream-rabbitmq-provider2001
4.3、修改消息消费者
(1)自定义一个Sink(com.caochenlei.message.MySink)
public interface MySink {
String INPUT = "myInput";
@Input("myInput")
SubscribableChannel input();
}
@EnableBinding(MySink.class)
public class ConsumerReceiver {
@Value("${server.port}")
private String serverPort;
@StreamListener(MySink.INPUT)
public void receive(Message message) {
System.out.println(serverPort + " receive:" + message.getPayload());
}
}
(3)修改配置文件application.yaml绑定管道的名称
#局部配置,请对应修改,其他地方保持不变
bindings:
#消息消费者的设置选项
myInput: #修改管道的名称,不是input了
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要接收的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
(4)重新启动stream-rabbitmq-consumer2002
(5)我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send,然后查看stream-rabbitmq-consumer2002控制台
StreamRabbitmqProvider2001Application :2001

StreamRabbitmqConsumer2002Application :2002

第五章 Stream分组与持久化
5.1、创建消息消费者
根据stream-rabbitmq-consumer2002重新创建一份除端口号和启动类名上的端口号不一样其余均一样的stream-rabbitmq-consumer2003工程,然后启动。

5.2、奇怪问题的演示
我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send,然后查看控制台
StreamRabbitmqProvider2001Application :2001

StreamRabbitmqConsumer2002Application :2002

StreamRabbitmqConsumer2003Application :2003

我们发现这两个消费者都执行了,那可能有人会说,这有啥问题,是消费者就应该执行啊,场景不一样,这个问题的严重程度就不一样。
比如:你现在开发了一套电商系统,有一套商品详情页需要生成静态商品详情页,这个生成静态页面的服务部署了很多机器,当这个商品发布的时候,你就应该让每一台机器上都生成一份该商品的商品详情页,这么一看确实没问题。
但是你再想啊,如果你现在有一套订单系统,也是部署了很多机器,当用户一下单支付的时候,所有部署了订单的机器都跑了一遍,那这个用户得多支付多少钱啊,这个时候,问题就严重了,那我们怎么能够无论有多少个消费者,只能让其中的一个执行呢?
5.3、如何解决这问题
这个问题,Stream也帮我们想到了,因此,他就引用了一种分组机制,分组后会拥有以下的特性:
- 同一个组中,无论有多少消费者,最终都只会有一个消费者执行。
- 有分组就表示该消息可以进行持久化,不分组的话,消费者要先启动起来,然后再用生产者发送消息,这样才可以接收到消息,否则发送的消息就丢失了,生产者先发了消息,消费者后面才启动的话是接收不到消息的;分组后,如果消费端的微服务宕机或重启,该队列信息依然会被保留在RabbitMQ中,后续依然可以进行消费。
默认的情况下,Stream就已经为每一个消息消费者都分配了一个组,这个组名是随机匿名的,查看地址:http://localhost:15672/#/queues

那么,问题有随之而来了,如何修改默认分组,怎么修改,请往下学习。
5.4、消息分组后演示
(1)修改stream-rabbitmq-consumer2002的application.yaml,只需要加入一句,修改完毕,然后重启
#局部配置,请对应修改,其他地方保持不变
bindings:
#消息消费者的设置选项
myInput: #修改管道的名称,不是input了
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要接收的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
group: orderGroup #表示自定义分组,同一组内的所有消费者有竞争关系,且具备消息持久化
(2)修改stream-rabbitmq-consumer2003的application.yaml,只需要加入一句,修改完毕,然后重启
#局部配置,请对应修改,其他地方保持不变
bindings:
#消息消费者的设置选项
myInput: #修改管道的名称,不是input了
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要接收的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
group: orderGroup #表示自定义分组,同一组内的所有消费者有竞争关系,且具备消息持久化
(3)我们看看是不是真的分组了,浏览器地址输入:http://localhost:15672/#/queues

(4)我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send,然后查看控制台
StreamRabbitmqProvider2001Application :2001

StreamRabbitmqConsumer2002Application :2002

StreamRabbitmqConsumer2003Application :2003

这样问题就得到了解决。
5.5、消息持久化演示
(1)关闭stream-rabbitmq-consumer2002和stream-rabbitmq-consumer2003
(2)我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send
(3)随便启动一个消息消费者,这里启动stream-rabbitmq-consumer2003,然后查看控制台

持久化也得到了保证。
第六章 Stream消息分区处理
6.1、修改消息生产者
(1)修改stream-rabbitmq-provider2001的com.caochenlei.message.ProviderSender
@EnableBinding(MySource.class)
public class ProviderSender {
@Autowired//使用自定义的管道名myOutput
private MessageChannel myOutput;
// public void send() {
// String uuid = UUID.randomUUID().toString();
// //核心代码:构建一个消息类型,然后使用发送管道发送出去
// myOutput.send(MessageBuilder.withPayload(uuid).build());
// System.out.println("send:" + uuid);
// }
public void send() {
String uuid = UUID.randomUUID().toString();
for (int i = 1; i < 8; i++) {
//核心代码:构建一个消息类型,然后使用发送管道发送出去
Map<String, Object> payload = new HashMap<>();
payload.put("orderId", uuid);
payload.put("data", i);
myOutput.send(MessageBuilder.withPayload(payload).build());
System.out.println("send:" + uuid + ",data:" + i);
}
}
}
(2)重启stream-rabbitmq-provider2001和stream-rabbitmq-consumer2002

6.2、奇怪问题的演示
我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send,然后查看控制台
StreamRabbitmqProvider2001Application :2001

StreamRabbitmqConsumer2002Application :2002

StreamRabbitmqConsumer2003Application :2003

我们通过观察,发现上边运行的很正常,因为是随机竞争,只有一个消费者进行消费,因此就会产生上边这种情况。
假设,我现在一个用户购买了800件商品,发送一个订单,数据量很大,每次都会导致发送超时,因此,我们就想了一个办法,将一个数据量很大的订单,进行拆分,比如,100件为1组,我们通过循环,发送8次,这样,每一次发送的数据量就大大减少,这样就保证了成功率,到消费端再根据订单的id来对订单进行重新组装,保证订单的一致,但是由此会产生另外一个问题,什么问题呢,就是每发送一次都会有一个消费者来消费,一个完整的订单的分组就会被多个消费者消费,使得这一个订单分布到了不同的消费者上,这样我就没有办法通过订单id拿到所有的数据进行重新组装了。
我现在就想解决这个问题,消费的时候,你当前这个组竞争,随便谁都可以,但是,只要你抢到了我这个订单的消费权,这个订单的数据全部交给你来处理,其他人就不能消费了,这样就保证了在竞争的情况下,一组数据经过多次发送,消费端保证只有一个消费者对该数据进行消费。
6.3、如何解决这问题
针对上述的问题,Stream又提供了分区的功能,使用分区功能就能解决。
(1)修改stream-rabbitmq-provider2001的application.yaml,修改完成,重新启动stream-rabbitmq-provider2001
#局部配置,请对应修改,其他地方保持不变
bindings:
#消息生产者的设置选项
myOutput: #修改管道的名称,不是output了
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要传送的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
#消息生产者分区设置
producer:
partitionCount: 2 #指定参与消息分区的消费端节点数量为2个
partitionKeyExpression: payload.orderId #通过该参数指定了分区键的表达式规则
(2)修改stream-rabbitmq-consumer2002的application.yaml,修改完成,重新启动stream-rabbitmq-consumer2002
#局部配置,请对应修改,其他地方保持不变
bindings:
#消息消费者的设置选项
myInput: #修改管道的名称,不是input了
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要接收的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
group: orderGroup #表示自定义分组,同一组内的所有消费者有竞争关系,且具备消息持久化
#消息消费者分区设置
consumer:
partitioned: true #开启消费者分区功能
#spring.cloud.stream.instanceCount,指定了当前消费者的总实例数量
instance-count: 2
#spring.cloud.stream.instanceIndex,设置当前实例的索引号为0索引
instance-index: 0
(3)修改stream-rabbitmq-consumer2003的application.yaml,修改完成,重新启动stream-rabbitmq-consumer2003
#局部配置,请对应修改,其他地方保持不变
bindings:
#消息消费者的设置选项
myInput: #修改管道的名称,不是input了
destination: springCloudStream #表示要使用的exchange名称定义
content-type: application/json #表示要接收的消息类型,文本则设置"text/plain"
binder: rabbit #表示要绑定到哪一个消息中间件上,看binders配置
group: orderGroup #表示自定义分组,同一组内的所有消费者有竞争关系,且具备消息持久化
#消息消费者分区设置
consumer:
partitioned: true #开启消费者分区功能
#spring.cloud.stream.instanceCount,指定了当前消费者的总实例数量
instance-count: 2
#spring.cloud.stream.instanceIndex,设置当前实例的索引号为1索引
instance-index: 1
(4)我们可以看看他是怎么给你区别不同的分区的,浏览器地址输入:http://localhost:15672/#/queues

6.4、消息分区后演示
我们发送一个消息试试,请在浏览器地址输入:http://localhost:2001/send,然后查看控制台
StreamRabbitmqProvider2001Application :2001

StreamRabbitmqConsumer2002Application :2002

StreamRabbitmqConsumer2003Application :2003

好了,问题解决了,总结一下,消息分区就是保证当生产者将消息数据发送给多个消费者实例时,保证同一消息数据始终是由同一个消费者实例接收和处理。
至于分区的选择,则是基于以下公式:key.hashCode() % partitionCount,我们上边的key是payload.orderId。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

