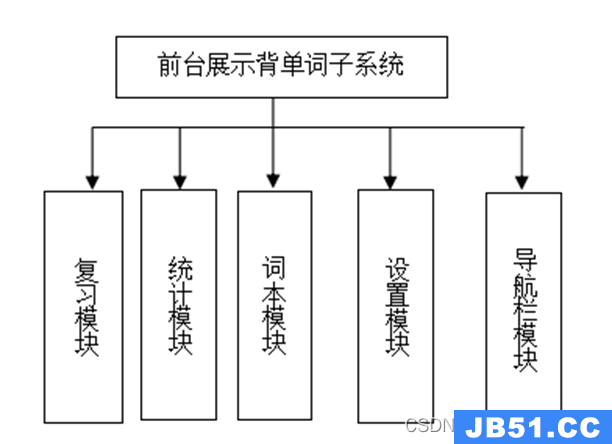
LevelDB Benchmarks
Google,July 2011
In order to test LevelDB's performance,we benchmark it against other well-established database implementations. We compare LevelDB (revision 39) against SQLite3 (version 3.7.6.3) and Kyoto Cabinet's (version 1.2.67) TreeDB (a B+Tree based key-value store). We would like to ackNowledge Scott Hess and Mikio Hirabayashi for their suggestions and contributions to the sqlite3 and Kyoto Cabinet benchmarks,respectively.
Benchmarks were all performed on a six-core Intel(R) Xeon(R) cpu X5650 @ 2.67GHz,with 12288 KB of total L3 cache and 12 GB of DDR3 RAM at 1333 MHz. (Note that LevelDB uses at most two cpus since the benchmarks are single threaded: one to run the benchmark,and one for background compactions.) We ran the benchmarks on two machines (with identical processors),one with an Ext3 file system and one with an Ext4 file system. The machine with the Ext3 file system has a SATA Hitachi HDS721050CLA362 hard drive. The machine with the Ext4 file system has a SATA Samsung HD502HJ hard drive. Both hard drives spin at 7200 RPM and have hard drive write-caching enabled (using `hdparm -W 1 [device]`). The numbers reported below are the median of three measurements.
Benchmark Source Code
We wrote benchmark tools for sqlite and Kyoto TreeDB based on LevelDB's db_bench. The code for each of the benchmarks resides here:
- LevelDB: db/db_bench.cc.
- sqlite: doc/bench/db_bench_sqlite3.cc.
- Kyoto TreeDB: doc/bench/db_bench_tree_db.cc.
Custom Build Specifications
- LevelDB: LevelDB was compiled with the tcmalloc library and the Snappy compression library (revision 33). Assertions were disabled.
- TreeDB: TreeDB was compiled using the LZO compression library (version 2.03). Furthermore,we enabled the TSMALL and TLINEAR options when opening the database in order to reduce the footprint of each record.
- sqlite: We tuned sqlite's performance,by setting its locking mode to exclusive. We also enabled sqlite's write-ahead logging.
1. Baseline Performance
This section gives the baseline performance of all the databases. Following sections show how performance changes as varIoUs parameters are varied. For the baseline:
- Each database is allowed 4 MB of cache memory.
- Databases are opened in asynchronous write mode. (LevelDB's sync option,TreeDB's OAUTOSYNC option,and sqlite3's synchronous options are all turned off). I.e.,every write is pushed to the operating system,but the benchmark does not wait for the write to reach the disk.
- Keys are 16 bytes each.
- Value are 100 bytes each (with enough redundancy so that a simple compressor shrinks them to 50% of their original size).
- Sequential reads/writes traverse the key space in increasing order.
- Random reads/writes traverse the key space in random order.
A. Sequential Reads
| LevelDB | 4,030,000 ops/sec |
|
| Kyoto TreeDB | 1,010,000 ops/sec |
|
| sqlite3 | 383,000 ops/sec |
|
B. Random Reads
| LevelDB | 129,000 ops/sec |
|
| Kyoto TreeDB | 151,000 ops/sec |
|
| sqlite3 | 134,000 ops/sec |
|
C. Sequential Writes
| LevelDB | 779,000 ops/sec |
|
| Kyoto TreeDB | 342,000 ops/sec |
|
| sqlite3 | 48,600 ops/sec |
|
D. Random Writes
| LevelDB | 164,000 ops/sec |
|
| Kyoto TreeDB | 88,500 ops/sec |
|
| sqlite3 | 9,860 ops/sec |
|
LevelDB outperforms both sqlite3 and TreeDB in sequential and random write operations and sequential read operations. Kyoto Cabinet has the fastest random read operations.
2. Write Performance under Different Configurations
A. Large Values
For this benchmark,we start with an empty database,and write 100,000 byte values (~50% compressible). To keep the benchmark running time reasonable,we stop after writing 1000 values.
Sequential Writes
| LevelDB | 1,100 ops/sec |
|
| Kyoto TreeDB | 1,000 ops/sec |
|
| sqlite3 | 1,600 ops/sec |
|
Random Writes
| LevelDB | 480 ops/sec |
|
| Kyoto TreeDB | 1,100 ops/sec |
|
| sqlite3 | 1,600 ops/sec |
|
LevelDB doesn't perform as well with large values of 100,000 bytes each. This is because LevelDB writes keys and values at least twice: first time to the transaction log,and second time (during a compaction) to a sorted file. With larger values,LevelDB's per-operation efficiency is swamped by the cost of extra copies of large values.
B. Batch Writes
A batch write is a set of writes that are applied atomically to the underlying database. A single batch of N writes may be significantly faster than N individual writes. The following benchmark writes one thousand batches where each batch contains one thousand 100-byte values. TreeDB does not support batch writes and is omitted from this benchmark.
Sequential Writes
| LevelDB | 840,000 entries/sec |
|
(1.08x baseline) |
| sqlite3 | 124,000 entries/sec |
|
(2.55x baseline) |
Random Writes
| LevelDB | 221,000 entries/sec |
|
(1.35x baseline) |
| sqlite3 | 22,000 entries/sec |
|
(2.23x baseline) |
Because of the way LevelDB persistent storage is organized,batches of random writes are not much slower (only a factor of 4x) than batches of sequential writes.
C. Synchronous Writes
In the following benchmark,we enable the synchronous writing modes of all of the databases. Since this change significantly slows down the benchmark,we stop after 10,000 writes. For synchronous write tests,we've disabled hard drive write-caching (using `hdparm -W 0 [device]`).
- For LevelDB,we set WriteOptions.sync = true.
- In TreeDB,we enabled TreeDB's OAUTOSYNC option.
- For sqlite3,we set "PRAGMA synchronous = FULL".
Sequential Writes
| LevelDB | 100 ops/sec |
|
(0.003x baseline) |
| Kyoto TreeDB | 7 ops/sec |
|
(0.0004x baseline) |
| sqlite3 | 88 ops/sec |
|
(0.002x baseline) |
Random Writes
| LevelDB | 100 ops/sec |
|
(0.015x baseline) |
| Kyoto TreeDB | 8 ops/sec |
|
(0.001x baseline) |
| sqlite3 | 88 ops/sec |
|
(0.009x baseline) |
Also see the ext4 performance numbers below since synchronous writes behave significantly differently on ext3 and ext4.
D. Turning Compression Off
In the baseline measurements,LevelDB and TreeDB were using light-weight compression (Snappy for LevelDB,and LZO for TreeDB). sqlite3,by default does not use compression. The experiments below show what happens when compression is disabled in all of the databases (the sqlite3 numbers are just a copy of its baseline measurements):
Sequential Writes
| LevelDB | 594,000 ops/sec |
|
(0.76x baseline) |
| Kyoto TreeDB | 485,000 ops/sec |
|
(1.42x baseline) |
| sqlite3 | 48,600 ops/sec |
|
(1.00x baseline) |
Random Writes
| LevelDB | 135,000 ops/sec |
|
(0.82x baseline) |
| Kyoto TreeDB | 159,000 ops/sec |
|
(1.80x baseline) |
| sqlite3 | 9,860 ops/sec |
|
(1.00x baseline) |
LevelDB's write performance is better with compression than without since compression decreases the amount of data that has to be written to disk. Therefore LevelDB users can leave compression enabled in most scenarios without having worry about a tradeoff between space usage and performance. TreeDB's performance on the other hand is better without compression than with compression. Presumably this is because TreeDB's compression library (LZO) is more expensive than LevelDB's compression library (Snappy).
E. Using More Memory
We increased the overall cache size for each database to 128 MB. For LevelDB,we partitioned 128 MB into a 120 MB write buffer and 8 MB of cache (up from 2 MB of write buffer and 2 MB of cache). For sqlite3,we kept the page size at 1024 bytes,but increased the number of pages to 131,072 (up from 4096). For TreeDB,we also kept the page size at 1024 bytes,but increased the cache size to 128 MB (up from 4 MB).
Sequential Writes
| LevelDB | 812,000 ops/sec |
|
(1.04x baseline) |
| Kyoto TreeDB | 321,000 ops/sec |
|
(0.94x baseline) |
| sqlite3 | 48,500 ops/sec |
|
(1.00x baseline) |
Random Writes
| LevelDB | 355,000 ops/sec |
|
(2.16x baseline) |
| Kyoto TreeDB | 284,000 ops/sec |
|
(3.21x baseline) |
| sqlite3 | 9,670 ops/sec |
|
(0.98x baseline) |
sqlite's performance does not change substantially when compared to the baseline,but the random write performance for both LevelDB and TreeDB increases significantly. LevelDB's performance improves because a larger write buffer reduces the need to merge sorted files (since it creates a smaller number of larger sorted files). TreeDB's performance goes up because the entire database is available in memory for fast in-place updates.
3. Read Performance under Different Configurations
A. Larger Caches
We increased the overall memory usage to 128 MB for each database. For LevelDB,we allocated 8 MB to LevelDB's write buffer and 120 MB to LevelDB's cache. The other databases don't differentiate between a write buffer and a cache,so we simply set their cache size to 128 MB.
Sequential Reads
| LevelDB | 5,210,000 ops/sec |
|
(1.29x baseline) |
| Kyoto TreeDB | 1,070,000 ops/sec |
|
(1.06x baseline) |
| sqlite3 | 609,000 ops/sec |
|
(1.59x baseline) |
Random Reads
| LevelDB | 190,000 ops/sec |
|
(1.47x baseline) |
| Kyoto TreeDB | 463,000 ops/sec |
|
(3.07x baseline) |
| sqlite3 | 186,000 ops/sec |
|
(1.39x baseline) |
As expected,the read performance of all of the databases increases when the caches are enlarged. In particular,TreeDB seems to make very effective use of a cache that is large enough to hold the entire database.
B. No Compression Reads
For this benchmark,we populated a database with 1 million entries consisting of 16 byte keys and 100 byte values. We compiled LevelDB and Kyoto Cabinet without compression support,so results that are read out from the database are already uncompressed. We've listed the sqlite3 baseline read performance as a point of comparison.
Sequential Reads
| LevelDB | 4,880,000 ops/sec |
|
(1.21x baseline) |
| Kyoto TreeDB | 1,230,000 ops/sec |
|
(3.60x baseline) |
| sqlite3 | 383,000 ops/sec |
|
(1.00x baseline) |
Random Reads
| LevelDB | 149,000 ops/sec |
|
(1.16x baseline) |
| Kyoto TreeDB | 175,000 ops/sec |
|
(1.16x baseline) |
| sqlite3 | 134,000 ops/sec |
|
(1.00x baseline) |
Performance of both LevelDB and TreeDB improves a small amount when compression is disabled. Note however that under different workloads,performance may very well be better with compression if it allows more of the working set to fit in memory.
Note about Ext4 Filesystems
The preceding numbers are for an ext3 file system. Synchronous writes are much slower under ext4 (LevelDB drops to ~31 writes / second and TreeDB drops to ~5 writes / second; sqlite3's synchronous writes do not noticeably drop) due to ext4's different handling of fsync / msync calls. Even LevelDB's asynchronous write performance drops somewhat since it spreads its storage across multiple files and issues fsync calls when switching to a new file.
AckNowledgements
Jeff Dean and Sanjay Ghemawat wrote LevelDB. Kevin Tseng wrote and compiled these benchmarks. Mikio Hirabayashi,Scott Hess,and Gabor Cselle provided help and advice.
sqlite写入还真是慢,唉。。。。
原文:http://leveldb.googlecode.com/svn/trunk/doc/benchmark.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。