黑苹果OpenCore (OC)升级教程 (最新版)
系统:Macos 12.x
准备工具:
- Hackintool (v3.4.4) (https://github.com/headkaze/Hackintool/releases)
- OpenCore Configurator (2.60.0.1) (下载)
- 最新版OpenCore 0.8.0 (https://github.com/acidanthera/OpenCorePkg/releases)
- Meld (3.21.0.osx3) (http://meldmerge.org/)
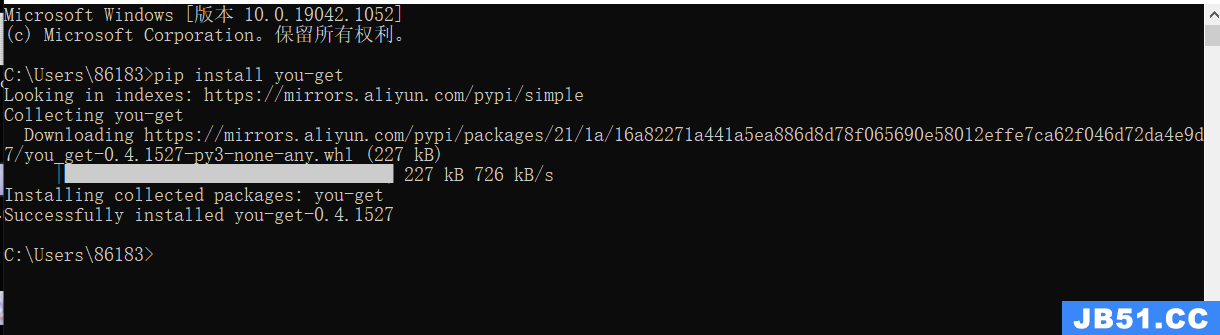
一、 查看oc版本
可以使用hackintool查看(下图是已经升级好了的,未升级前是低于这个版本的):

(如果版本不一致,opencore configurator也会提示)。
二、挂载EFI分区
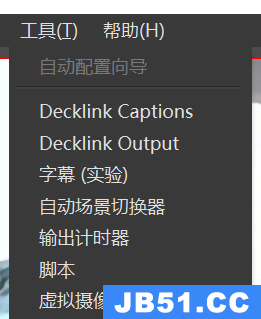
使用opencore configurator挂载EFI分区,打开opencore configurator,左上角菜单栏工具下拉菜单,第一项挂载EFI,如图:
然后点选“挂载分区”-“打开分区”,这时候EFI分区文件夹就弹出来了。

把EFI拷贝到桌面,或者复制,在桌面建立一个副本。同时解压下载的最新版OC包也放在桌面。
三、更改sample.plist (很重要)
打开刚备份的EFI文件夹,在OC目录下,找到config.plist;同时打开OpenCore包的Doc文件夹,找到sample.plist。
之后安装Meld程序,然后打开这两个文件进行代码比对。一个在左边,一个在右边,如图:


可以看到中间有向右和向左的黑色箭头。左边的是正常启动系统的文件,右边是最新的示例引导文件,需要让右边的sample.plist和左边的config.plist保持一致。蓝色部分是两个文件不一样的部分,点选左边的箭头,让右边的内容和左边保持一致,点选之后,蓝色自动消失变成白色。从上到下,依次点击左边的箭头。
若遇到左边部分有绿色块代码,说明左边代码是多出来的,也需要移到右边,保持一致,依然选择左边箭头。反过来,如果右边有绿色代码,那就不要动,不要修改。

改完之后,右边文件代码不再有蓝色部分,然后保存即可。

四、替换config.plist文件。
删除或者备份config.plist,然后把刚修改的sample.plist放到备份的EFI文件夹OC目录下,并修改文件名,改回config.plist。
五、替换启动文件。

打开左边备份的EFI文件夹下的BOOT文件夹,同时依次打开右边OC新包的X64/EFI/BOOT文件夹,把右边的BOOTX64文件替换或者覆盖左边的相同文件。
然后替换OC目录下的efi文件,新包x64/EFI/OC目录下的OpenCore.efi替换覆盖掉左边OC目录下的相同文件。
用右边新包x64/EFI/OC/Drivers目录下的OpenRuntime.efi换覆盖掉左边OC/Driver目录下的OpenRuntime.efi。
需要更换的四个efi文件,如下:
EFI/BOOT/BOOTx64.efi
EFI/OC/OpenCore.efi //决定版本升级是否成功
EFI/OC/Drivers/OpenCanopy.efi //系统启动菜单GUI界面必需,需要和Opencore.efi版本对应。
EFI/OC/Drivers/OpenRuntime.efi
六、 升级驱动。
打开hackintool,切换到内核扩展选项,绿色部分即是系统已经安装的扩展。数字栏是对应的版本,右键Open Url可以打开对应的驱动链接,检查是否是最新版。如果不是最新版,就下载最新的安装包(Release版)。下载之后解压打开,打开刚备份的EFI/OC/Kexts,把需要更换的新的驱动替换掉旧版本的驱动。
至此,启动文件和驱动都升级完毕。
七、整体替换EFI
重新使用OpenCore Configurator打开EFI文件夹,删掉EFI文件夹,把刚备份修改的EFI文件夹拖过去。关闭文件夹窗口,卸载分区,退出Opencore Configurator。


八、重启即可生效。
重启后,打开Hackintool,切换到引导选项卡就可以看到版本变化了,同时OpenCore Cofigurator的版本不匹配提示就没有了,OC升级完成。
原文地址:https://blog.csdn.net/CWH4567
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。