


现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
对这道题我们进行初步的分析:
编写代码:
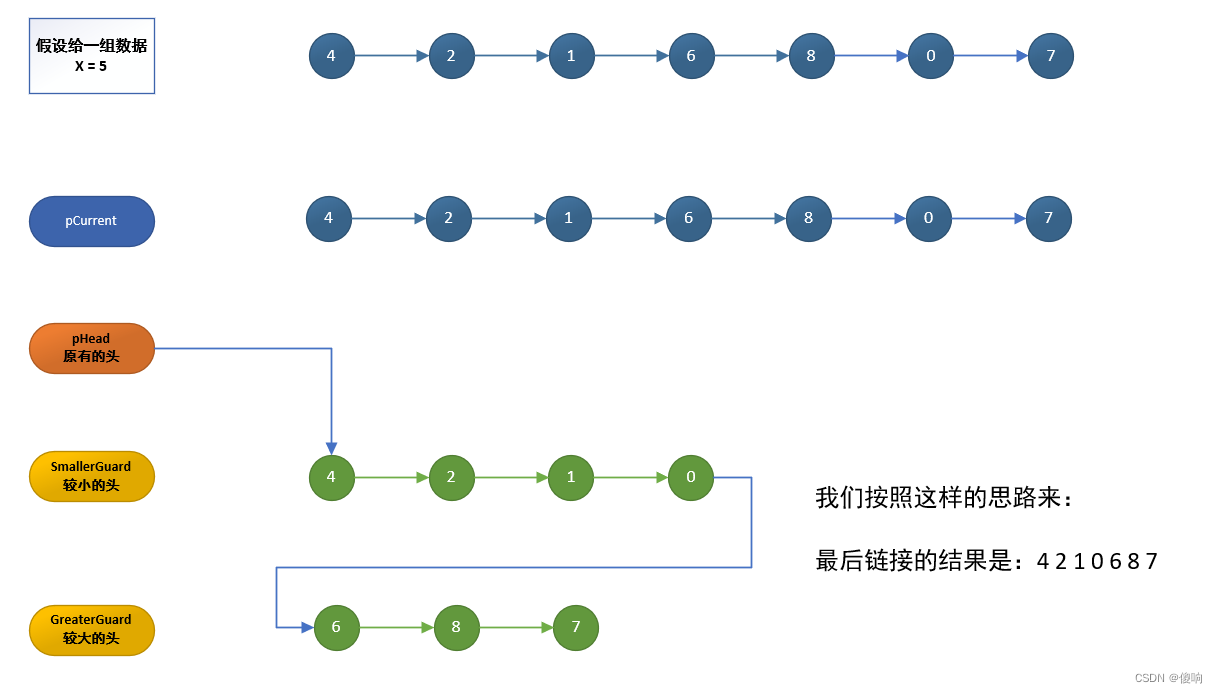
代码写完了:我们发现有问题:
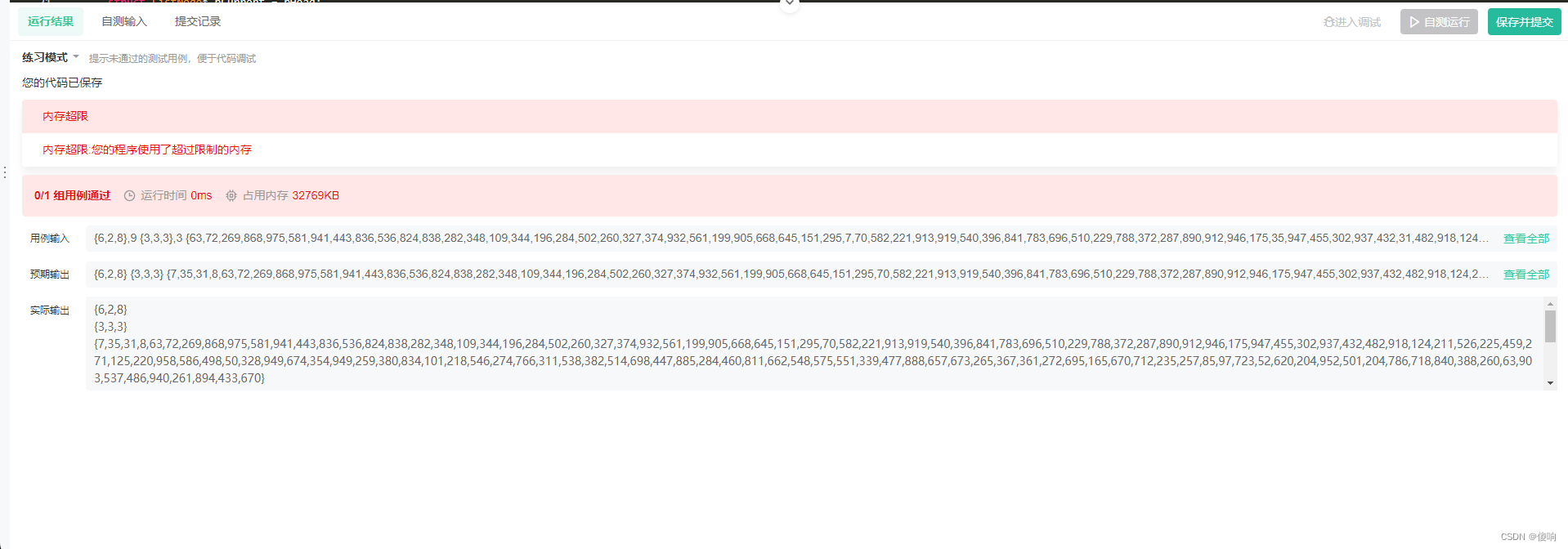
我们拿出自己逻辑上的值试一下:好像没啥问题哎~

这个逻辑感觉是对的,但是我们要分析一下极端的问题:
1:所有的值都比x大、
2:所有的值都比x小、
3:空链表。
1:所有的值都比x大->没有问题
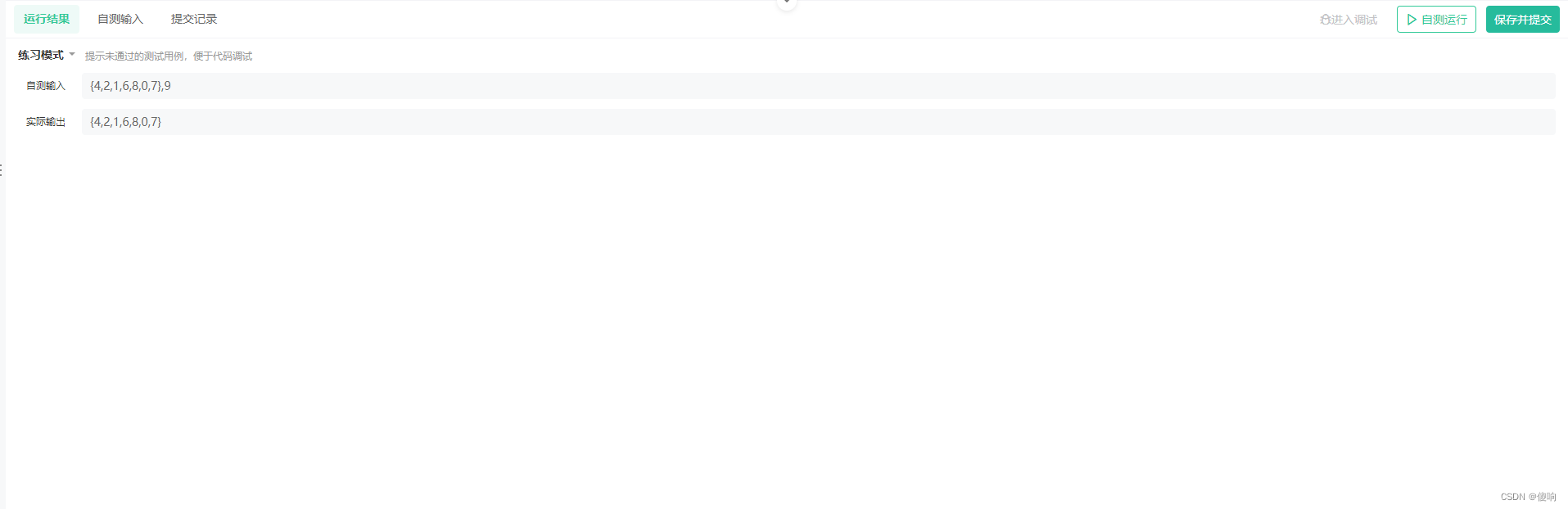
2:所有的值都比x小 ->没有问题
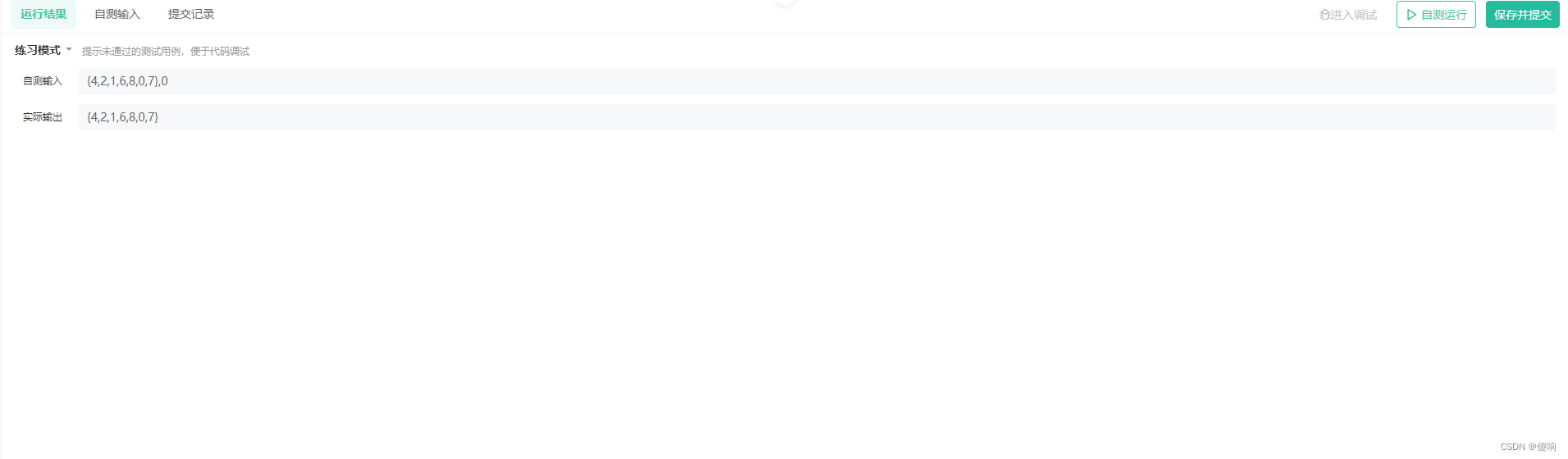
3:空链表->出现问题了
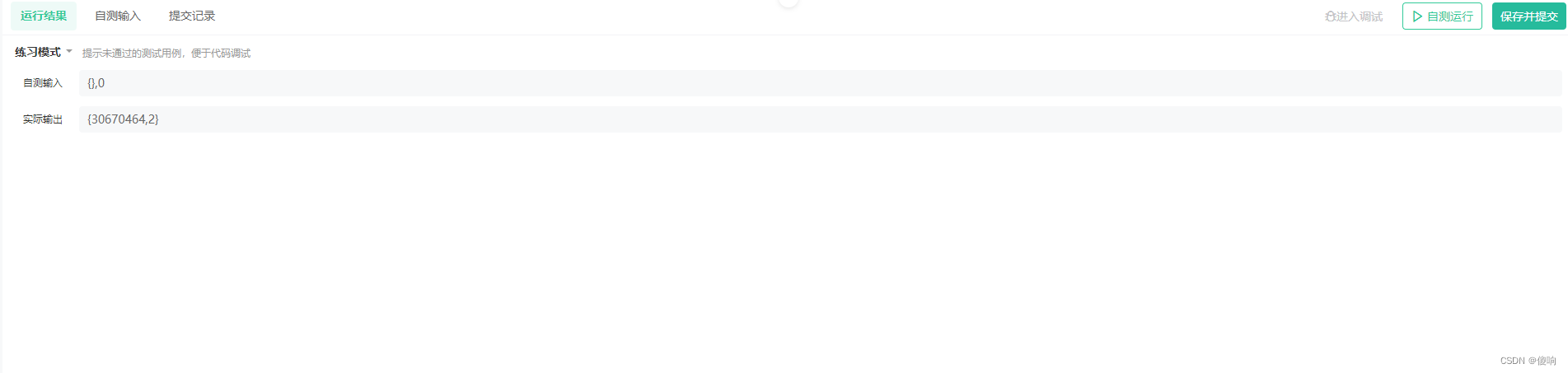
原因:使用了空指针。
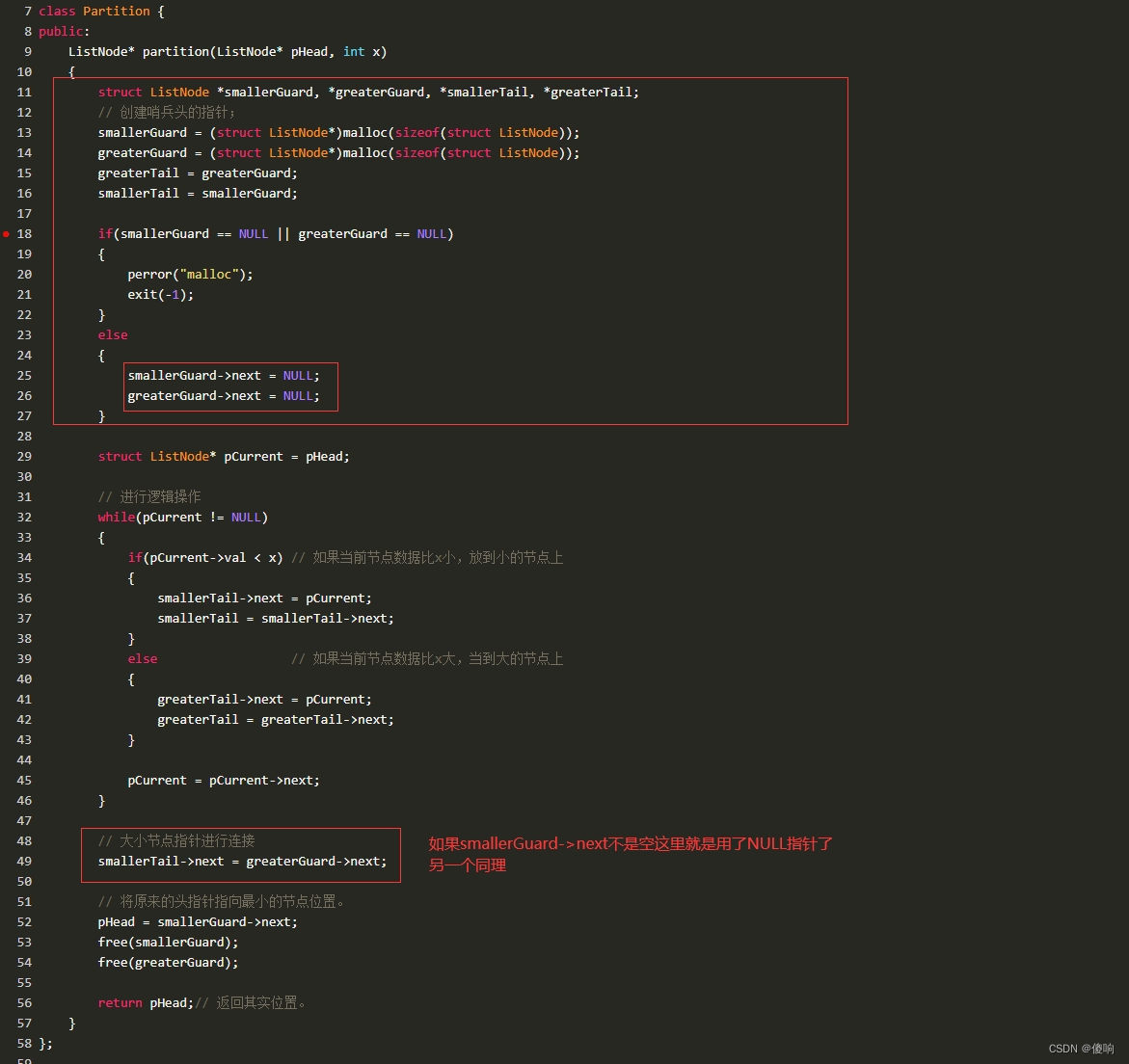

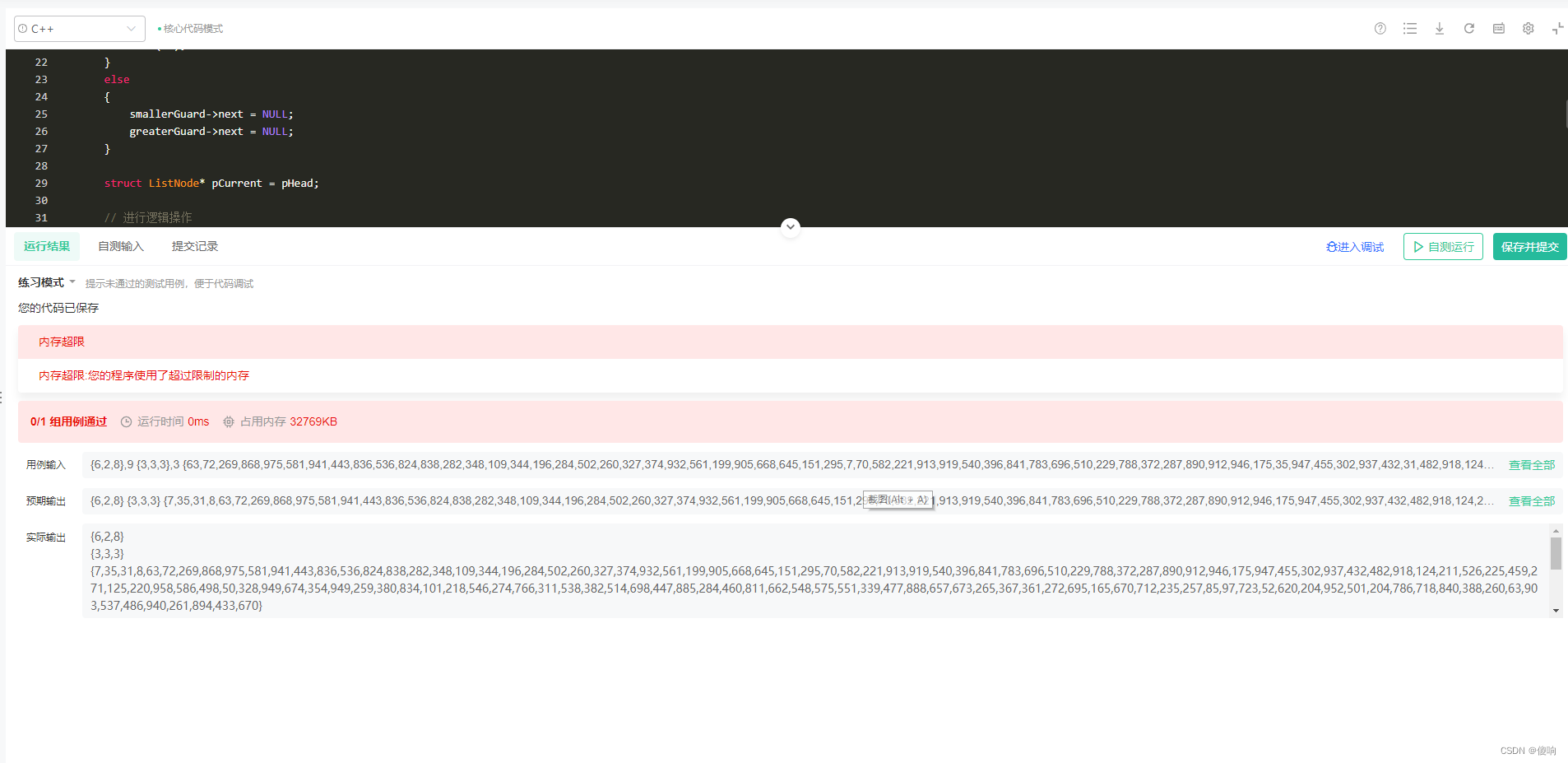
那我们分析一下数据边界问题->比如说我们现在换一组数据:

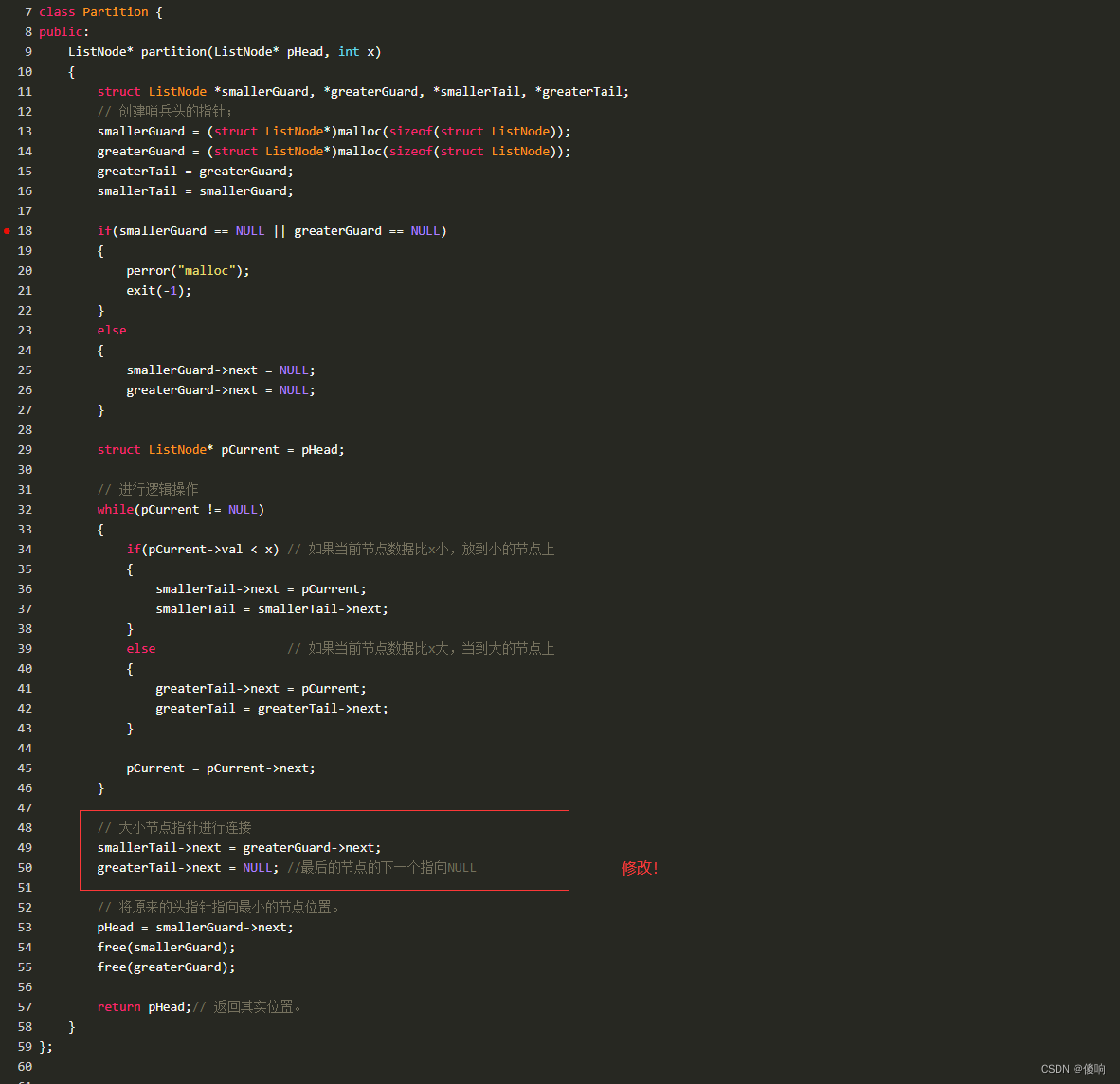
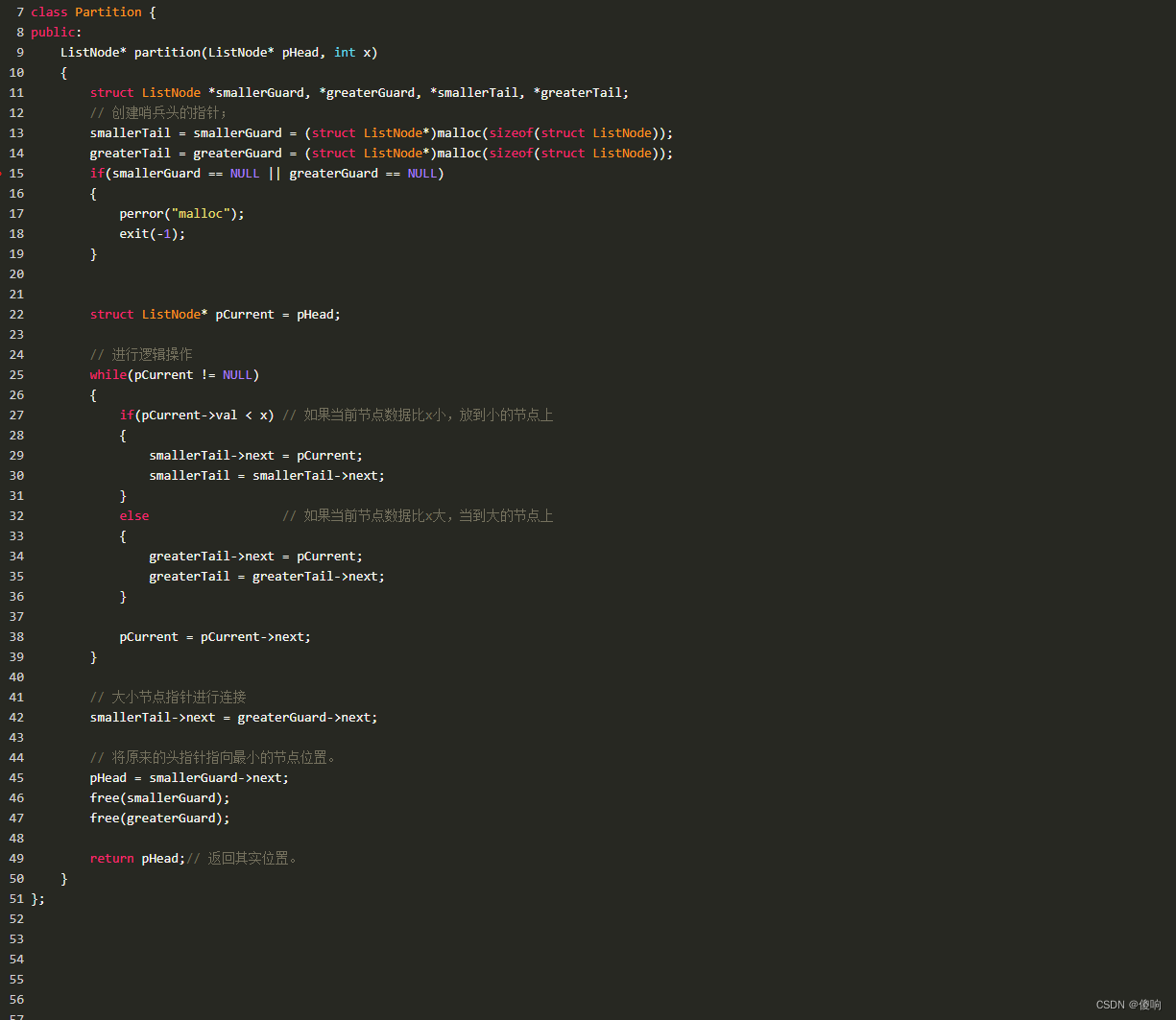
源代码:
class Partition {
public:
ListNode* partition(ListNode* pHead, int x)
{
struct ListNode *smallerGuard, *greaterGuard, *smallerTail, *greaterTail;
// 创建哨兵头的指针;
smallerGuard = (struct ListNode*)malloc(sizeof(struct ListNode));
greaterGuard = (struct ListNode*)malloc(sizeof(struct ListNode));
greaterTail = greaterGuard;
smallerTail = smallerGuard;
if(smallerGuard == NULL || greaterGuard == NULL)
{
perror("malloc");
exit(-1);
}
else
{
smallerGuard->next = NULL;
greaterGuard->next = NULL;
}
struct ListNode* pCurrent = pHead;
// 进行逻辑操作
while(pCurrent != NULL)
{
if(pCurrent->val < x) // 如果当前节点数据比x小,放到小的节点上
{
smallerTail->next = pCurrent;
smallerTail = smallerTail->next;
}
else // 如果当前节点数据比x大,当到大的节点上
{
greaterTail->next = pCurrent;
greaterTail = greaterTail->next;
}
pCurrent = pCurrent->next;
}
// 大小节点指针进行连接
smallerTail->next = greaterGuard->next;
greaterTail->next = NULL; //最后的节点的下一个指向NULL
// 将原来的头指针指向最小的节点位置。
pHead = smallerGuard->next;
free(smallerGuard);
free(greaterGuard);
return pHead;// 返回其实位置。
}
};题目链接:链表分割_牛客题霸_牛客网 (nowcoder.com)
原文地址:https://www.jb51.cc/wenti/3279779.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

