

目 录
三、文本表示
1. One-hot
One-hot(独热)编码是一种最简单的文本表示方式。如果有一个大小为V的词表,对于第i个词 w i w_i wi,可以用一个长度为V的向量来表示,其中第i个元素为1,其它为0.例如:
减肥:[1, 0, 0, 0, 0]
瘦身:[0, 1, 0, 0, 0]
增重:[0, 0, 1, 0, 0]
One-hot词向量构建简单,但也存在明显的弱点:
2. 词袋模型
词袋模型(Bag-of-words model,BOW),BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。例如:
我把他揍了一顿,揍得鼻青眼肿
他把我揍了一顿,揍得鼻青眼肿
构建一个词典:
{"我":0, "把":1, "他":2, "揍":3, "了":4 "一顿":5, "鼻青眼肿":6, "得":7}
再将句子向量化,维数和字典大小一致,第i维上的数值代表ID为i的词在句子里出现的频次,两个句子可以表示为:
[1, 1, 1, 2, 1, 1, 1, 1]
[1, 1, 1, 2, 1, 1, 1, 1]
词袋模型表示简单,但也存在较为明显的缺点:
- 丢失了顺序和语义。顺序是极其重要的语义信息,词袋模型只统计词语出现的频率,忽略了词语的顺序。例如上述两个句子意思相反,但词袋模型表示却完全一致;
- 高维度和稀疏性。当语料增加时,词袋模型维度也会增加,需要更长的向量来表示。但大多数词语不会出现在一个文本中,所以导致矩阵稀疏。
3. TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种基于传统的统计计算方法,常用于评估一个文档集中一个词对某份文档的重要程度。其基本思想是:一个词语在文档中出现的次数越多、出现的文档越少,语义贡献度越大(对文档区分能力越强)。其表达式为:
T
F
−
I
D
F
=
T
F
i
j
×
I
D
F
i
=
n
j
i
∑
k
n
k
j
×
l
o
g
(
∣
D
∣
∣
D
i
∣
+
1
)
TF-IDF = TF_{ij} \times IDF_i =\frac{n_{ji}}{\sum_k n_{kj}} \times log(\frac{|D|}{|D_i| + 1})
TF−IDF=TFij×IDFi=∑knkjnji×log(∣Di∣+1∣D∣)
该指标依然无法保留词语在文本中的位置关系。该指标前面有过详细讨论,此处不再赘述。
4. 共现矩阵
共现(co-occurrence)矩阵指通过统计一个事先指定大小的窗口内的词语共现次数,以词语周边的共现词的次数做为当前词语的向量。具体来说,我们通过从大量的语料文本中构建一个共现矩阵来表示词语。例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
则共现矩阵表示为:
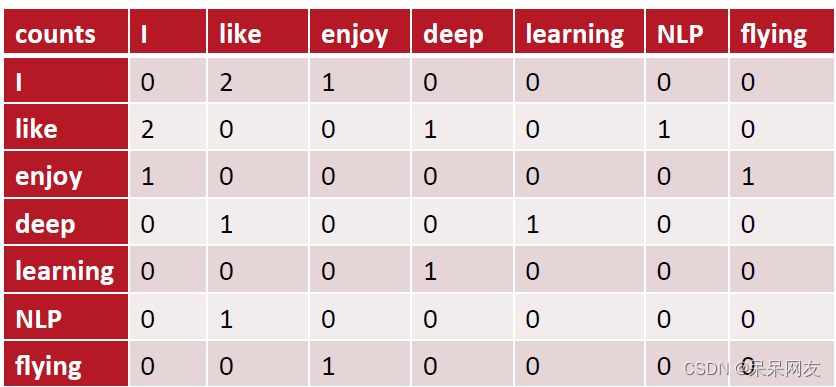
矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
5. N-Gram表示
N-Gram模型是一种基于统计语言模型,语言模型是一个基于概率的判别模型,它的输入是个句子(由词构成的顺序序列),输出是这句话的概率,即这些单词的联合概率。
N-Gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有Bi-gram(N=2)和Tri-gram(N=3)。例如:
句子:L love deep learning
Bi-gram: {I, love}, {love, deep}, {deep, learning}
Tri-gram: {I, love, deep}, {love deep learning}
N-Gram基本思想是将文本里面的内容按照字节进行大小为n的滑动窗口操作,形成了长度是n的字节片段序列。每一个字节片段称为一个gram,对所有gram的出现频度进行统计,并按照事先设置好的频度阈值进行过滤,形成关键gram列表,也就是这个文本向量的特征空间,列表中的每一种gram就是一个特征向量维度。
6. 词嵌入
1)什么是词嵌入
词嵌入(word embedding)是一种词的向量化表示方式,该方法将词语映射为一个实数向量,同时保留词语之间语义的相似性和相关性。例如:
| Man | Women | King | Queen | Apple | Orange | |
|---|---|---|---|---|---|---|
| Gender | -1 | 1 | -0.95 | 0.97 | 0.00 | 0.01 |
| Royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 | 0.00 |
| Age | 0.03 | 0.02 | 0.70 | 0.69 | 0.03 | -0.02 |
| Food | 0.09 | 0.01 | 0.02 | 0.01 | 0.95 | 0.97 |
我们用一个四维向量来表示man,Women,King,Queen,Apple,Orange等词语(在实际中使用更高维度的表示,例如100~300维),这些向量能进行语义的表示和计算。例如,用Man的向量减去Woman的向量值:
e
m
a
n
−
e
w
o
m
a
n
=
[
−
1
0.01
0.03
0.09
]
−
[
1
0.02
0.02
0.01
]
=
[
−
2
−
0.01
0.01
0.08
]
≈
[
−
2
0
0
0
]
e_{man} - e_{woman} = \left[ \begin{matrix} -1 \\ 0.01 \\ 0.03 \\ 0.09 \\ \end{matrix} \right] -\left[ \begin{matrix} 1 \\ 0.02 \\ 0.02 \\ 0.01 \\ \end{matrix} \right] = \left[ \begin{matrix} -2 \\ -0.01 \\ 0.01 \\ 0.08 \\ \end{matrix} \right] \approx \left[ \begin{matrix} -2 \\ 0 \\ 0 \\ 0 \\ \end{matrix} \right]
eman−ewoman=⎣
⎡−10.010.030.09⎦
⎤−⎣
⎡10.020.020.01⎦
⎤=⎣
⎡−2−0.010.010.08⎦
⎤≈⎣
⎡−2000⎦
⎤
类似地,如果用King的向量减去Queen的向量,得到相似的结果:
e
k
i
n
g
−
e
q
u
e
e
n
=
[
−
0.95
0.93
0.70
0.02
]
−
[
0.97
0.85
0.69
0.01
]
=
[
−
1.92
−
0.02
0.01
0.01
]
≈
[
−
2
0
0
0
]
e_{king} - e_{queen} = \left[ \begin{matrix} -0.95 \\ 0.93 \\ 0.70 \\ 0.02 \\ \end{matrix} \right] -\left[ \begin{matrix} 0.97 \\ 0.85 \\ 0.69 \\ 0.01 \\ \end{matrix} \right] = \left[ \begin{matrix} -1.92 \\ -0.02 \\ 0.01 \\ 0.01 \\ \end{matrix} \right] \approx \left[ \begin{matrix} -2 \\ 0 \\ 0 \\ 0 \\ \end{matrix} \right]
eking−equeen=⎣
⎡−0.950.930.700.02⎦
⎤−⎣
⎡0.970.850.690.01⎦
⎤=⎣
⎡−1.92−0.020.010.01⎦
⎤≈⎣
⎡−2000⎦
⎤
我们可以通过某种降维算法,将向量映射到低纬度空间中,相似的词语位置较近,不相似的词语位置较远,这样能帮助我们更直观理解词嵌入对语义的表示。如下图所示:
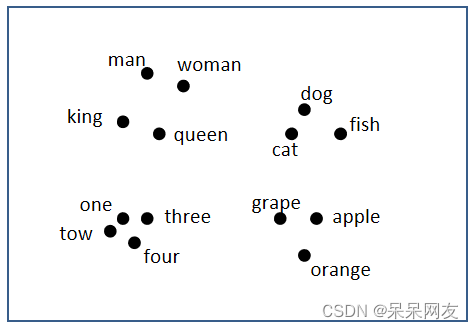
实际任务中,词汇量较大,表示维度较高,因此,我们不能手动为大型文本语料库开发词向量,而需要设计一种方法来使用一些机器学习算法(例如,神经网络)自动找到好的词嵌入,以便有效地执行这项繁重的任务。
2)词嵌入的优点
四、语言模型
1. 什么是语言模型
语言模型在文本处理、信息检索、机器翻译、语音识别中承担这重要的任务。从通俗角度来说,语言模型就是通过给定的一个词语序列,预测下一个最可能的词语是什么。传统语言模型有N-gram模型、HMM(隐马尔可夫模型)等,进入深度学习时代后,著名的语言模型有神经网络语言模型(Neural Network Language Model,NNLM),循环神经网络(Recurrent Neural Networks,RNN)等。
语言模型从概率论专业角度来描述就是:为长度为m的字符串确定其概率分布
P
(
w
1
,
w
2
,
.
.
.
,
w
n
)
P(w_1, w_2, ..., w_n)
P(w1,w2,...,wn),其中
w
1
w_1
w1到
w
n
w_n
wn依次表示文本中的各个词语。一般采用链式法则计算其概率值:
P
(
w
1
,
w
2
,
.
.
.
,
w
n
)
=
P
(
w
1
)
P
(
w
2
∣
w
1
)
P
(
w
3
∣
w
1
,
w
2
)
.
.
.
P
(
w
m
∣
w
1
,
w
2
,
.
.
.
,
w
m
−
1
)
P(w_1, w_2, ..., w_n) = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)...P(w_m|w_1,w_2,...,w_{m-1})
P(w1,w2,...,wn)=P(w1)P(w2∣w1)P(w3∣w1,w2)...P(wm∣w1,w2,...,wm−1)
观察上式,可发现,当文本长度过长时计算量过大,所以有人提出N元模型(N-gram)降低计算复杂度。
2. N-gram模型
所谓N-gram(N元)模型,就是在计算概率时,忽略长度大于N的上下文词的影响。当N=1时,称为一元模型(Uni-gram Mode),其表达式为:
P
(
w
1
,
w
2
,
.
.
.
,
w
n
)
=
∏
i
=
1
m
P
(
w
i
)
P(w_1, w_2, ..., w_n) = \prod_{i=1}^m P(w_i)
P(w1,w2,...,wn)=i=1∏mP(wi)
当N=2时,称为二元模型(Bi-gram Model),其表达式为:
P
(
w
1
,
w
2
,
.
.
.
,
w
n
)
=
∏
i
=
1
m
P
(
w
i
∣
w
i
−
1
)
P(w_1, w_2, ..., w_n) = \prod_{i=1}^m P(w_i|w_{i-1})
P(w1,w2,...,wn)=i=1∏mP(wi∣wi−1)
当N=3时,称为三元模型(Tri-gram Model),其表达式为:
P
(
w
1
,
w
2
,
.
.
.
,
w
n
)
=
∏
i
=
1
m
P
(
w
i
∣
w
i
−
2
,
w
i
−
1
)
P(w_1, w_2, ..., w_n) = \prod_{i=1}^m P(w_i|w_{i-2}, w_{i-1})
P(w1,w2,...,wn)=i=1∏mP(wi∣wi−2,wi−1)
可见,N值越大,保留的词序信息(上下文)越丰富,但计算量也呈指数级增长。
3. 神经网络语言模型(NNLM)
NNLM是利用神经网络对N元条件进行概率估计的一种方法,其基本结构如下图所示:
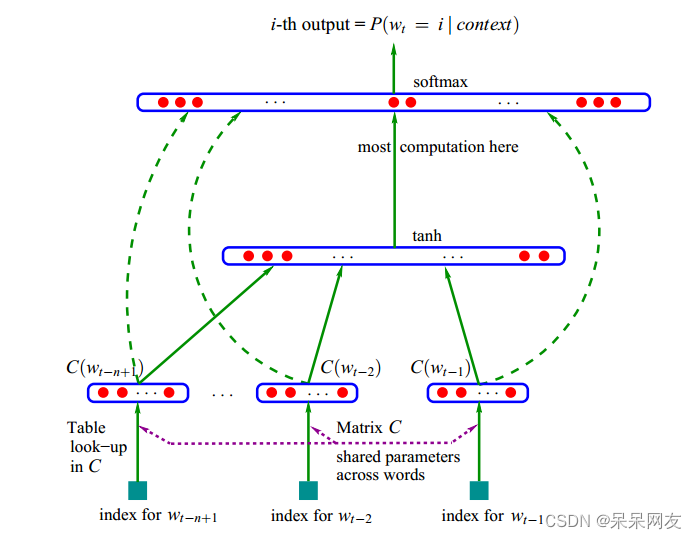
f ( w t , w t − 1 , . . . , w t − n + 1 ) = p ( p t ∣ w 1 t − 1 ) f(w_t, w_{t-1}, ..., w_{t-n+1}) = p(p_t|w_1^{t-1}) f(wt,wt−1,...,wt−n+1)=p(pt∣w1t−1)
其中, w t w_t wt表示第t个词, w 1 t − 1 w_1^{t-1} w1t−1表示第1个到第t个词语组成的子序列,每个词语概率均大于0,所有词语概率之和等于1。该模型计算包括两部分:特征映射、计算条件概率
- 特征映射:将输入映射为一个特征向量,映射矩阵 C ∈ R ∣ V ∣ × m C \in R^{|V| \times m} C∈R∣V∣×m
- 计算条件概率分布:通过另一个函数,将特征向量转化为一个概率分布
神经网络计算公式为:
h
=
t
a
n
h
(
H
x
+
b
)
y
=
U
h
+
d
h = tanh(Hx + b) \\ y = Uh + d
h=tanh(Hx+b)y=Uh+d
H为隐藏层权重矩阵,U为隐藏层到输出层的权重矩阵。输出层加入softmax函数,将y转换为对应的概率。模型参数
θ
\theta
θ,包括:
θ
=
(
b
,
d
,
H
,
U
,
C
)
\theta = (b, d, H, U, C)
θ=(b,d,H,U,C)
以下是一个计算示例:设词典大小为1000,向量维度为25,N=3,先将前N个词表示成独热向量:
呼:[1,0,0,0,0,...,0]
伦:[0,1,0,0,0,...,0]
贝:[0,0,1,0,0,...,0]
输入矩阵为:[3, 1000]
权重矩阵:[1000, 25]
隐藏层:[3, 1000] * [1000, 25] = [3, 25]
输出层权重:[25, 1000]
输出矩阵:[3, 25] * [25, 1000] = [3, 1000] ==> [1, 1000],表示预测属于1000个词的概率.
4. Word2vec
Word2vec是Goolge发布的、应用最广泛的词嵌入表示学习技术,其主要作用是高效获取词语的词向量,目前被用作许多NLP任务的特征工程。Word2vec 可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式,为自然语言处理领域的应用研究提供了新的工具,包含Skip-gram(跳字模型)和CBOW(连续词袋模型)来建立词语的词嵌入表示。Skip-gram的主要作用是根据当前词,预测背景词(前后的词);CBOW的主要作用是根据背景词(前后的词)预测当前词。
1)Skip-gram
Skip-gram的主要作用是根据当前词,预测背景词(前后的词),其结构图如下图所示:
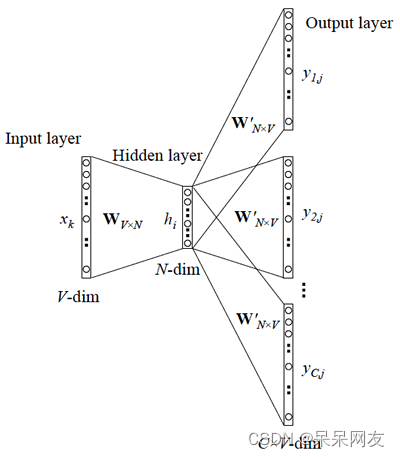
例如有如下语句:呼伦贝尔大草原
_ _贝_ _草原
呼_ _尔_ _原
呼伦_ _大_ _
预测出前后词的数量,称为window_size(以上示例中windows_size为2),实际是要将以下概率最大化:
P(呼|贝)P(伦|贝)P(尔|贝)P(大|贝)
P(伦|尔)P(贝|尔)P(大|尔)P(草|尔)
P(贝|大)P(尔|大)P(草|大)P(草|原)
可以写出概率的一般化表达式,设有文本Text,由N个单词组成:
T
e
x
t
=
w
1
,
w
2
,
w
3
,
.
.
.
,
w
n
Text = {w_1, w_2, w_3, ..., w_n}
Text=w1,w2,w3,...,wn
目标函数可以写作:
a
r
g
m
a
x
∏
w
∈
T
e
x
t
∏
c
∈
c
(
w
)
P
(
c
∣
w
;
θ
)
argmax \prod_{w \in Text} \ \ \prod_{c \in c(w)} P(c|w; \theta)
argmaxw∈Text∏ c∈c(w)∏P(c∣w;θ)
其中,
w
w
w为当前词,
c
c
c为
w
w
w的上下文词,
θ
\theta
θ为要优化的参数,这个参数即每个词(或字)的稠密向量表示,形如:
[ 呼 : θ 11 θ 12 θ 13 . . . θ 1 n 伦 : θ 21 θ 22 θ 23 . . . θ 2 n 贝 : θ 31 θ 32 θ 33 . . . θ 3 n 尔 : θ 41 θ 42 θ 43 . . . θ 4 n 大 : θ 51 θ 52 θ 53 . . . θ 5 n 草 : θ 61 θ 62 θ 63 . . . θ 6 n 原 : θ 71 θ 72 θ 73 . . . θ 7 n ] \left[ \begin{matrix} 呼: \theta_{11} \ \ \theta_{12} \ \ \theta_{13}\ ...\ \ \theta_{1n} \\ 伦: \theta_{21} \ \ \theta_{22} \ \ \theta_{23}\ ...\ \ \theta_{2n} \\ 贝: \theta_{31} \ \ \theta_{32} \ \ \theta_{33}\ ...\ \ \theta_{3n} \\ 尔: \theta_{41} \ \ \theta_{42} \ \ \theta_{43}\ ...\ \ \theta_{4n} \\ 大: \theta_{51} \ \ \theta_{52} \ \ \theta_{53}\ ...\ \ \theta_{5n} \\ 草: \theta_{61} \ \ \theta_{62} \ \ \theta_{63}\ ...\ \ \theta_{6n} \\ 原: \theta_{71} \ \ \theta_{72} \ \ \theta_{73}\ ...\ \ \theta_{7n} \\ \end{matrix} \right] ⎣ ⎡呼:θ11 θ12 θ13 ... θ1n伦:θ21 θ22 θ23 ... θ2n贝:θ31 θ32 θ33 ... θ3n尔:θ41 θ42 θ43 ... θ4n大:θ51 θ52 θ53 ... θ5n草:θ61 θ62 θ63 ... θ6n原:θ71 θ72 θ73 ... θ7n⎦ ⎤
该参数
θ
\theta
θ能够使得目标函数最大化。因为概率均为0~1之间的数字,连乘计算较为困难,所以转换为对数相加形式:
a
r
g
m
a
x
∑
w
∈
T
e
x
t
∑
c
∈
c
(
w
)
l
o
g
P
(
c
∣
w
;
θ
)
argmax \sum_{w \in Text} \ \sum_{c \in c(w)} logP(c|w;\theta)
argmaxw∈Text∑ c∈c(w)∑logP(c∣w;θ)
再表示为softmax形式:
a
r
g
m
a
x
∑
w
∈
T
e
x
t
∑
c
∈
c
(
w
)
l
o
g
(
e
u
c
⋅
v
w
/
∑
c
′
∈
v
o
c
a
b
e
u
c
′
⋅
v
w
)
argmax \sum_{w \in Text} \sum_{c \in c(w)} log \Big(e^{u_c \cdot v_w} / \sum_{c' \in vocab } e^{u_{c'} \cdot v_w} \Big)
argmaxw∈Text∑c∈c(w)∑log(euc⋅vw/c′∈vocab∑euc′⋅vw)
其中,U为上下文单词矩阵,V为同样大小的中心词矩阵,因为每个词可以作为上下文词,同时也可以作为中心词,
u
c
⋅
v
w
u_c \cdot v_w
uc⋅vw表示上下文词和中心词向量的内积(内积表示向量的相似度),相似度越大,概率越高;分母部分是以
w
w
w为中心词,其它所有上下文词
c
′
c'
c′内积之和,再将上一步公式进行简化:
=
a
r
g
m
a
x
∑
w
∈
T
e
x
t
∑
c
∈
c
(
w
)
(
l
o
g
(
e
u
c
⋅
v
w
)
−
l
o
g
(
∑
c
′
∈
v
o
c
a
b
e
u
c
′
⋅
v
w
)
)
=
a
r
g
m
a
x
∑
w
∈
T
e
x
t
∑
c
∈
c
(
w
)
(
u
c
⋅
v
w
−
l
o
g
∑
c
′
∈
v
o
c
a
b
e
u
c
′
⋅
v
w
)
= argmax \sum_{w \in Text} \sum_{c \in c(w)} \Big(log(e^{u_c \cdot v_w}) - log(\sum_{c' \in vocab } e^{u_{c'} \cdot v_w}) \Big)\\ = argmax \sum_{w \in Text} \sum_{c \in c(w)} \Big(u_c \cdot v_w - log \sum_{c' \in vocab }e^{u_{c'} \cdot v_w} \Big)
=argmaxw∈Text∑c∈c(w)∑(log(euc⋅vw)−log(c′∈vocab∑euc′⋅vw))=argmaxw∈Text∑c∈c(w)∑(uc⋅vw−logc′∈vocab∑euc′⋅vw)
上式中,由于需要在整个词汇表中进行遍历,如果词汇表很大,计算效率会很低。所以,真正进行优化时,采用另一种优化形式。例如有如下语料库:
文本:呼伦贝尔大草原
将window_size设置为1,构建正案例词典、负案例词典(一般来说,负样本词典比正样本词典大的多):
正样本:D = {(呼,伦),(伦,呼),(伦,贝),(贝,伦),(贝,尔),(尔,贝),(尔,大),(大,尔),(大,草)(草,大),(草,原),(原,草)}
负样本:D’= {(呼,贝),(呼,尔),(呼,大),(呼,草),(呼,原),(伦,尔),(伦,大),(伦,草),(伦,原),(贝,呼),(贝,大),(贝,草),(贝,原),(尔,呼),(尔,伦)(尔,草),(尔,原),(大,呼),(大,伦),(大,原),(草,呼),(草,伦),(草,贝),(原,呼),(原,伦),(原,贝),(原,尔),(原,大)}
词向量优化的目标函数定义为正样本、负样本公共概率最大化函数:
a
r
g
m
a
x
(
∏
w
,
c
∈
D
l
o
g
P
(
D
=
1
∣
w
,
c
;
θ
)
∏
w
,
c
∈
D
′
P
(
D
=
0
∣
w
,
c
;
θ
)
)
=
a
r
g
m
a
x
(
∏
w
,
c
∈
D
1
1
+
e
x
p
(
−
U
c
⋅
V
w
)
∏
w
,
c
∈
D
′
[
1
−
1
1
+
e
x
p
(
−
U
c
⋅
V
w
)
]
)
=
a
r
g
m
a
x
(
∑
w
,
c
∈
D
l
o
g
σ
(
U
c
⋅
V
w
)
+
∑
w
,
c
∈
D
′
l
o
g
σ
(
−
U
c
⋅
V
w
)
)
argmax (\prod_{w,c \in D} log P(D=1|w,c; \theta) \prod_{w, c \in D'} P(D=0|w, c; \theta)) \\ = argmax (\prod_{w,c \in D} \frac{1}{1+exp(-U_c \cdot V_w)} \prod_{w, c \in D'} [1- \frac{1}{1+exp(-U_c \cdot V_w)}]) \\ = argmax(\sum_{w,c \in D} log \sigma (U_c \cdot V_w) + \sum_{w,c \in D'} log \sigma (-U_c \cdot V_w))
argmax(w,c∈D∏logP(D=1∣w,c;θ)w,c∈D′∏P(D=0∣w,c;θ))=argmax(w,c∈D∏1+exp(−Uc⋅Vw)1w,c∈D′∏[1−1+exp(−Uc⋅Vw)1])=argmax(w,c∈D∑logσ(Uc⋅Vw)+w,c∈D′∑logσ(−Uc⋅Vw))
在实际训练时,会从负样本集合中选取部分样本(称之为“负采样”)来进行计算,从而降低运算量.要训练词向量,还需要借助于语言模型.
2)CBOW模型
CBOW模型全程为Continous Bag of Words(连续词袋模型),其核心思想是用上下文来预测中心词,例如:
呼伦贝_大草原
其模型结构示意图如下:
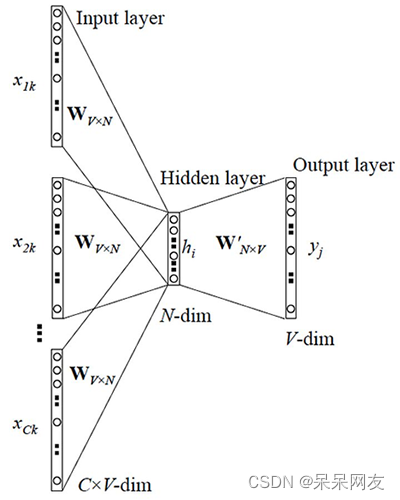
- 输入: C × V C \times V C×V的矩阵,C表示上下文词语的个数,V表示词表大小
- 隐藏层: V × N V \times N V×N的权重矩阵,一般称为word-embedding,N表示每个词的向量长度,和输入矩阵相乘得到 C × N C \times N C×N的矩阵。综合考虑上下文中所有词信息预测中心词,所以将 C × N C \times N C×N矩阵叠加,得到 1 × N 1 \times N 1×N的向量
- 输出层:包含一个 N × V N \times V N×V的权重矩阵,隐藏层向量和该矩阵相乘,输出 1 × V 1 \times V 1×V的向量,经过softmax转换为概率,对应每个词表中词语的概率
3)示例:训练词向量
数据集:来自中文wiki文章,AIStudio下数据集名称:中文维基百科语料库
- 安装gensim
!pip install gensim==3.8.1 # 如果不在AIStudio下执行去掉前面的叹号
import logging
import os
import os.path
from gensim.corpora import WikiCorpus
# 获取输入数据
input_file = "data/data104767/articles.xml.bz2"
# 创建输出文件
out_file = open("wiki.zh.text", "w", encoding="utf-8")
# 调用gensim读取xml压缩文件
count = 0
# lemmatize: 词性还原?
wiki = WikiCorpus(input_file, lemmatize=False, dictionary={})
for text in wiki.get_texts():
out_file.write(" ".join(text) + "\n") # 向文件写入一行
count += 1
if count % 200 == 0:
print("count:", count)
if count >= 20000: # 2万笔时退出
break
out_file.close()
import jieba
import jieba.analyse
import codecs # python封装的文件工具包
def process_wiki_text(src_file, dest_file):
with codecs.open(src_file, "r", "utf-8") as f_in, codecs.open(dest_file, "w", "utf-8") as f_out:
num = 1
for line in f_in.readlines():
line_seg = " ".join(jieba.cut(line)) # 分词
f_out.writelines(line_seg) # 写入目标文件
num += 1
if num % 200 == 0:
print("处理完成:", num)
f_in.close()
f_out.close()
process_wiki_text("wiki.zh.text", "wiki.zh.text.seg")
- 训练
import logging
import sys
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import Linesentence # 按行读取
logger = logging.getLogger(__name__)
# format: 指定输出的格式和内容,format可以输出很多有用信息,
# %(asctime)s: 打印日志的时间
# %(levelname)s: 打印日志级别名称
# %(message)s: 打印日志信息
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
in_file = "wiki.zh.text.seg" # 输入文件(经过分词后的)
out_file1 = "wiki.zh.text.model" # 模型
out_file2 = "wiki.zh.text.vector" # 权重
# 模型训练
model = Word2Vec(Linesentence(in_file), # 输入
size=100, # 词向量维度(推荐25~300之间)
window=3, # 窗口大小
min_count=5, # 如果语料中单词出现次数小于5,忽略该词
workers=multiprocessing.cpu_count()) # 线程数量
# 保存模型
model.save(out_file1)
# 保存权重矩阵C
model.wv.save_word2vec_format(out_file2, # 文件路径
binary=False) # 不保存二进制
- 测试
import gensim
from gensim.models import Word2Vec
# 加载模型
model = Word2Vec.load("wiki.zh.text.model")
count = 0
for word in model.wv.index2word:
print(word, model[word]) # 打印
count += 1
if count >= 10:
break
print("==================================")
result = model.most_similar(u"铁路")
for r in result:
print(r)
print("==================================")
result = model.most_similar(u"中药")
for r in result:
print(r)
输出(训练过程略):
('高速铁路', 0.8310302495956421)
('客运专线', 0.8245105743408203)
('高铁', 0.8095601201057434)
('城际', 0.802475094795227)
('联络线', 0.7837506532669067)
('成昆铁路', 0.7820425033569336)
('支线', 0.7775323390960693)
('通车', 0.7751388549804688)
('沪', 0.7748854756355286)
('京广', 0.7708789110183716)
==============================================
('草药', 0.9046826362609863)
('中药材', 0.8511005640029907)
('气功', 0.8384993672370911)
('中医学', 0.8368280529975891)
('调味', 0.8364394307136536)
('冶炼', 0.8328938484191895)
('药材', 0.8304706811904907)
('有机合成', 0.8298543691635132)
('针灸', 0.8297436833381653)
('药用', 0.8281913995742798)
原文地址:https://www.jb51.cc/wenti/3280773.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

