

1、什么是ClickHouse
ClickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
2、优势
3、使用
3.1 数据类型
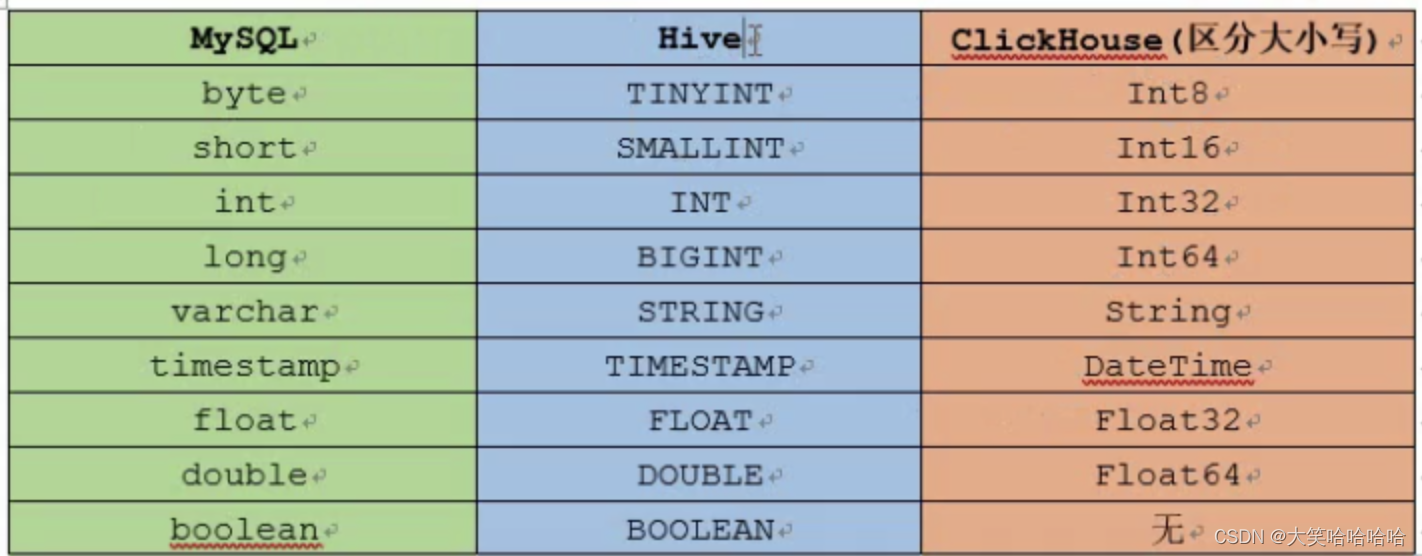
注意:ClickHouse 的数据类型严格区分大小写。
3.1.1 整型
固定长度的整型,包括有符号整型或无符号整型。
整型范围(-2^(n-1) ~ 2^(n-1)-1):
Int8、Int16、Int32、Int64、Int128、Int256
无符号整型范围(0~ 2^(n)-1):
UInt8、UInt16、UInt32、UInt64、UInt128、UInt256
3.1.2 浮点型
Float32 - float
Float64 - double
尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,例如货币数量或页面加载时间用毫秒为单位表示。因为浮点数进行计算可能引起四舍五入的误差。
与标准sql相比,ClickHouse 支持以下类别的浮点数:
Inf - 正无穷
-Inf - 负无穷
NaN - 非数字
3.1.3 字符串
1)String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
2) FixedString(N)
固定长度 N 的字符串(N 必须是严格的正自然数)。
当向ClickHouse中插入数据时:
- 如果字符串包含的字节数少于N,将对字符串末尾进行空字节填充。
- 如果字符串包含的字节数大于N,将抛出 Too large value for FixedString(N) 异常。
当做数据查询时,ClickHouse不会删除字符串末尾的空字节。 如果使用WHERE子句,则须要手动添加空字节以匹配FixedString的值。
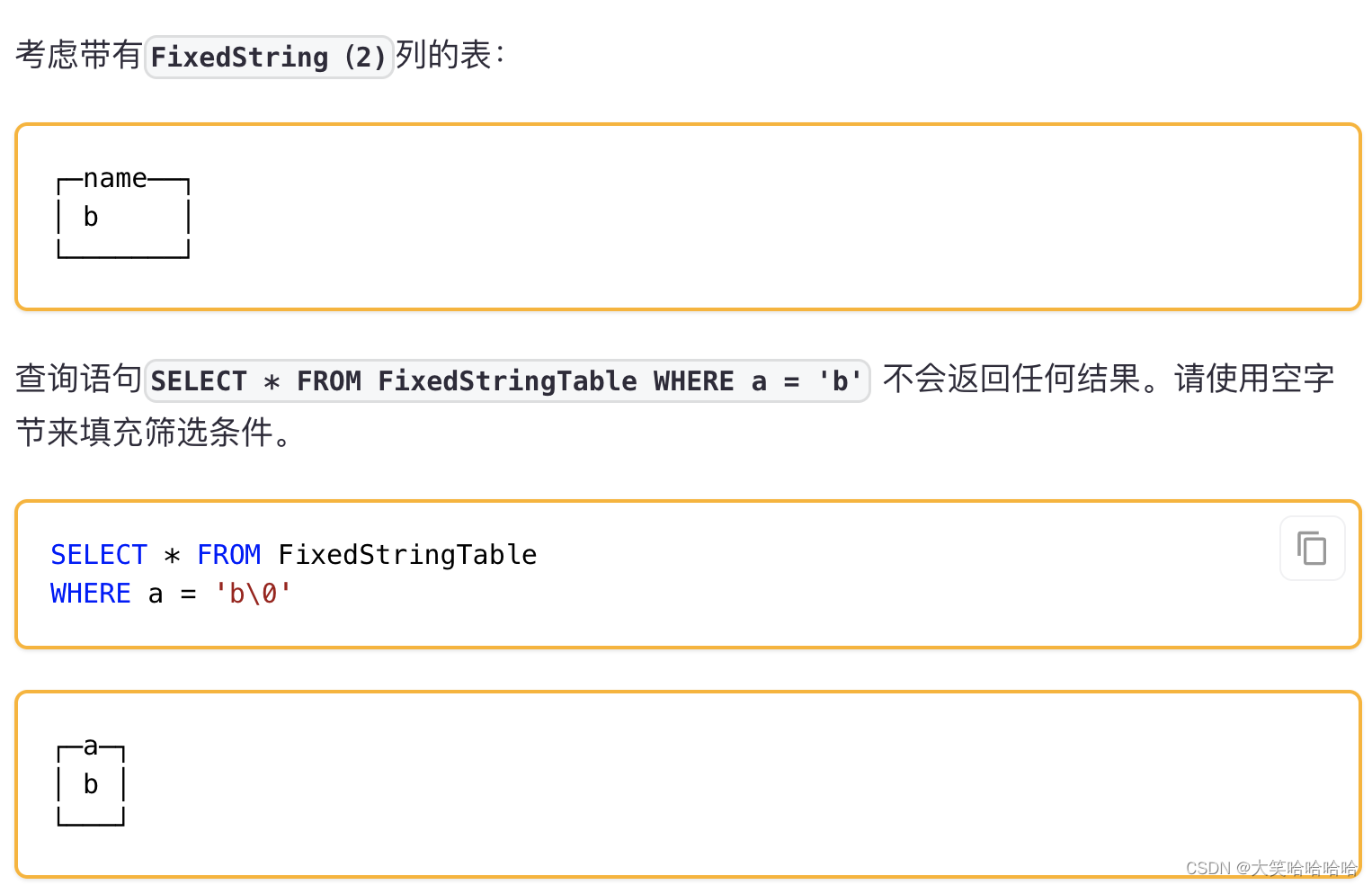
与String相比,极少会使用FixedString,因为使用起来不是很方便。
3.1.4 布尔值
从https://github.com/ClickHouse/ClickHouse/commit/4076ae77b46794e73594a9f400200088ed1e7a6e 之后,有单独的类型来存储布尔值。
在此之前的版本,没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。具体见枚举类型。
3.1.5 枚举类型
枚举包括 Enum8 和 Enum16 类型。Enum 保存 ‘String’=integer 的对应关系。
- Enum8 用 ‘String’=Int8 描述。
- Enum16 用 ‘String’=Int16 描述。
用法举例:
创建一个带有一个枚举 Enum8(‘hello’ = 1, ‘world’ = 2) 类型的列:
CREATE TABLE t_enum (
x Enum8('hello' = 1, 'world' = 2)
) ENGINE = TinyLog
这个 x 列只能存储类型定义中列出的值:‘hello’ 或 ‘world’。如果您尝试保存任何其他值,ClickHouse 抛出异常。
注意:键值对不能同时为空,不允许重复,key允许为空字符串。

3.1.6 数组
Array(T) : 由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能在 MergeTree 表引擎中存储多维数组。
创建数组:
array(T) 或 [] 类型必须相同
举例:
SELECT array(1, 2) AS x
SELECT [1, 2] AS x
ClickHouse会自动检测数组元素,并根据元素计算出存储这些元素最小的数据类型。如果在元素中存在 NULL 或存在 可为空 类型元素,那么数组的元素类型将会变成 可为空。
如果 ClickHouse 无法确定数据类型,它将产生异常。
3.1.6 元组
Tuple(T1, T2, …) :元组,其中每个元素都有单独的类型。
创建元组:
tuple(T1, T2, ...) 允许不同类型
举例:
SELECT tuple(1,'a') AS x
3.1.7 日期
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。
Date、DateTime、DateTime64
- Date:精确到天。(2022-08-01)
- DateTime:精确到秒。(2022-08-01 19:19:19)
- DateTime64:精确到亚秒,可以设置精度。(2022-08-01 19:19:19.000)
3.2 表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
3.2.1 TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。
该引擎没有并发控制:
- 如果同时从表中读取和写入数据,则读取操作将抛出异常。
- 如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once : 首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表(建议最多1,000,000行)。如果有许多小表,则使用此引擎是适合的,因为它需要打开的文件更少。当拥有大量小表时,可能会导致性能低下。
不支持索引。

3.2.2 Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,简单查询有非常高的查询性能(超过10G/s),因为没有磁盘读取,不需要解压缩或反序列化数据的过程。
不支持索引。
它可用于测试,适用于数据量又不太大(上限大概1亿行)的场景,这样查询性能比较高。
3.2.3 Merge
Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据。读是自动并行的,不支持写入。
读取时,如果底表是有索引的,那索引也会被使用。
Merge 引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
举例:先建 t1,t2,t3 三个表,然后用Merge引擎的 t 表再把它们链接起来。
-- 创建表
create table t1 (id UInt16, name String) ENGINE = TinyLog;
create table t2 (id UInt16, name String) ENGINE = TinyLog;
create table t3 (id UInt16, name String) ENGINE = TinyLog;
-- 插入数据
insert into t1 (id, name) values (1, 'first');
insert into t2 (id, name) values (2, 'second');
insert into t3 (id, name) values (3, '太棒了');
-- 使用 Merge 引擎创建表
create table t (id UInt16, name String) ENGINE = Merge(currentDatabase(),'^t');
3.2.4 MergeTree
Clickhouse中最强大的表引擎当属 MergeTree (合并树) 引擎及该系列(*MergeTree)中的其他引擎。
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
注意: Merge 引擎并不属于 *MergeTree 系列。
主要特点:
- 存储的数据按主键排序,这使得能创建一个稀疏索引来加快数据检索。
- 如果指定了分区键,可以使用分区,能有效增加查询效率。
- 支持数据副本。ReplicatedMergeTree 系列的表提供了数据副本功能。
- 支持数据采样。
3.2.5 ReplacingMergeTree
这个引擎是在 MergeTree 的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。
ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
ReplacingMergeTree 的可选参数:
ENGINE = ReplacingMergeTree([ver])
ver 表示版本列,类型为 UInt*, Date 或 DateTime。可选参数。
在数据合并时,ReplacingMergeTree 从相同排序键的行中选择一行留下:
- 如果 ver 列未指定,保留最后写入的一条。
- 如果 ver 列已指定,保留 ver 值最大的版本。
3.2.6 SummingMergeTree
该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把相同主键的行合并为一行,该行包含了被合并行中具有数值数据类型的列的汇总值。这样可显著减少存储空间并加快数据查询的速度。
SummingMergeTree 的可选参数:
ENGINE = SummingMergeTree([columns])
columns 包含了要被汇总列名的元组。可选参数。
注意:
1、所选的列必须是数值类型,并且不可位于主键中。
2、如果没有指定 columns,ClickHouse 会把所有不在主键中的数值类型的列都进行汇总。
3.2.7 distributed
分布式引擎本身不存储数据,但可以在多个服务器上进行分布式查询。读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
distributed 引擎的可选参数:
ENGINE = distributed(cluster, database, table[, sharding_key[, policy_name]])
- cluster:本地表所在的集群名称,与集群配置中的自定义名称相对应。在分布式表执行写入和查询的过程中,它会使用集群的配置信息来找到相应的host节点。
- database:本地表的数据库名称。
- table:本地表的表名称。
- sharding_key (可选): 分片key,在数据写入的过程中,分布式表会依据分片键的规则,将数据分布到各个host节点的本地表。一般可指定
rand()来随机分配数据,或者可指定为主键列的hash值,如intHash32(ID)、intHash64(ID),这样可以保证主键相同的数据落在同一个shard(分片)上,可以用于去重或聚合。 - storage_policy(可选):用于异步写入时,临时存储的本地磁盘的路径。
3.3 sql语法
3.3.1 创建表
ClickHouse 目前提供了三种最基本的建表方法。
- 1、第一种常规定义方法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
CREATE TABLE a (
Title String,
URL String,
EventTime DateTime
) ENGINE = Memory;
使用[db.] 参数可以为数据库指定数据库,如果不指定此参数,则默认会使用default数据库。
- 2、第二种定义方法是复制其他表的结构
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
-- 创建新的数据库
CREATE DATABASE IF NOT EXISTS new_db;
-- 将default.a 的结构复制到 new_db.a
CREATE TABLE IF NOT EXISTS new_db.a AS default.a ENGINE = TinyLog;
可以跨数据库复制表结构。
- 3、第三种定义方法是通过 SELECT 子句的形式创建
CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT ...
CREATE TABLE IF NOT EXISTS a_v1 ENGINE AS SELECT * FROM a;
根据 SELECT 子句建立相应的表结构,同时还会将 SELECT 子句查询的数据写入a_v1表中。
3.3.2 删除表
DROP DATABASE [IF EXISTS] db
删除数据表。
DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name
3.3.3 临时表
创建临时表需要添加 TEMPORARY 关键字。
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
)
特点:
- 它的生命周期是会话绑定的,所以它只支持Memory表引擎,如果会话结束,数据表就会被销毁。
- 临时表不属于任何数据库,所以不需要指定数据库参数和表引擎参数。
- 临时表的优先级大于普通表。当两张数据表名称相同时,会优先读取临时表的数据。
3.3.4 分区表
数据分区(partition)和数据分片(shard)是不同的两个概念。
- 分区
- 分片
CREATE TABLE partition_v1 (
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
3.3.5 数据表操作
- 追加新字段
ALTER TABLE tb_name ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [AFTER name_after]
说明:
[AFTER name_after] 是在指定列后面新加列,不指定则在表末尾添加列。
举例:在ID字段后面添加OS字段,默认值为'IOS'
ALTER TABLE partition_v1 ADD COLUMN OS String DEFAULT 'IOS' AFTER ID
- 修改字段类型
ALTER TABLE tb_name MODIFY COLUMN [IF EXISTS] name [type] [default_expr] [TTL]
- 修改备注
ALTER TABLE tb_name COMMENT COLUMN [IF EXISTS] name 'comment'
ALTER TABLE partition_v1 COMMENT COLUMN ID '主键ID'
- 删除已有字段
ALTER TABLE tb_name DROP COLUMN [IF EXISTS] name
ALTER TABLE partition_v1 DROP COLUMN URL
- 清空数据表
TruncATE TABLE [IF EXISTS] [db_name.]tb_name
TruncATE TABLE partition_v1
3.3.6 视图
ClickHouse 拥有普通和物化两种视图。
普通视图是一层简单的查询代理。物化视图拥有独立的存储。
- 普通视图
CREATE VIEW [IF NOT EXISTS] [db.]table_name AS SELECT ...
普通视图不会存储任何数据,它只是一层单纯的SELECT查询映射,起简化查询、明晰语义的作用,对查询性能不会有任何增强。
- 物化视图
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
物化视图支持表引擎,数据保存形式由它的表引擎决定。
物化视图创建好之后,如果源表写入新数据,那物化视图也会同步更新。
POPULATE 修饰符决定了物化视图的初始化策略:
- 使用 POPULATE 修饰符,那在创建视图的过程中,会连带将源表中已存在的数据一并导入。
- 不使用 POPULATE 修饰符,那在物化视图创建之后是没有数据的,它只会同步在此之后写入源表的新数据。
物化视图目前并不支持同步删除,如果在源表中删除了数据,物化视图的数据仍会保留。
3.3.7 数据的CRUD
1、数据的写入
INSERT 语法支持三种语法结构:
- 第一种是使用 VALUES 格式的常规语法:
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
INSERT INTO partition_v1 VALUES ('A01','www.xxx.com','2022-08-01')
- 第二种是使用指定格式的语法:
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name data_set
INSERT INTO partition_v1 FORMAT CSV \
'A02','www.xxx.com', '2022-08-01' \
'A03','www.xxx.com', '2022-08-02'
- 第三种是使用 SELECT 子句形式的语法:
INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
INSERT INTO partition_v2 SELECT * FROM partition_v1
3、数据的删除和修改
删除语法:
ALTER TABLE [db.]table DELETE WHERE filter_expr
ALTER TABLE partition_v1 DELETE WHERE ID = 'A03'
修改语法:
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr
ALTER TABLE partition_v1 UPDATE URL = 'www.666.com' WHERE ID IN ('A01','A03')
原文地址:https://www.jb51.cc/wenti/3280908.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

