

1. flink组件
作业管理器:jobmanager
任务管理器::taskManager
资源管理器:ResourceManager
分发器:dispatcher
2. flink任务提交流程
1. flink API介绍
flink 提供了不同的抽象级别以开发流式或批处理应用程序
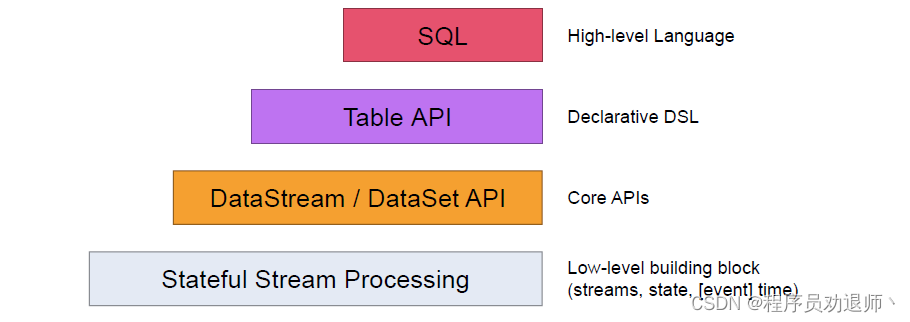
1.1 Stateful Stream Processing
最低级的抽象接口是状态化的数据流接口,这个接口是通过ProcessFunction集成到DataStramAPI中的,该接口允许用户自由的处理来自一个或多个流中的事件,并使用一致的容错状态,另外,用户也可以通过注册event time 和processing time 处理回调函数的方法来实现复杂的计算
1.2 DataStream/DataSet API
DataStream / DataSet API 是flink提供的核心API DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流,用户可以通过各种方法(map、flatMap,window,keyby,sum,max,min,avg,join等)将数据进行转换/计算
1.3 Table API
Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起
来却更加简洁,可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与
DataStream 以及 DataSet 混合使用
1.4 sql
Flink 提供的最高层级的抽象是 sql 。这一层抽象在语法与表达能力上与 Table API 类似。
sql 抽象与 Table API 交互密切,同时 sql 查询可以直接在 Table API 定义的表上执行
1.5 Stream API 的执行环境
此分布式运行时取决于你的应用是否是可序列化的。它还要求所有依赖对集群中的每个节点均可用
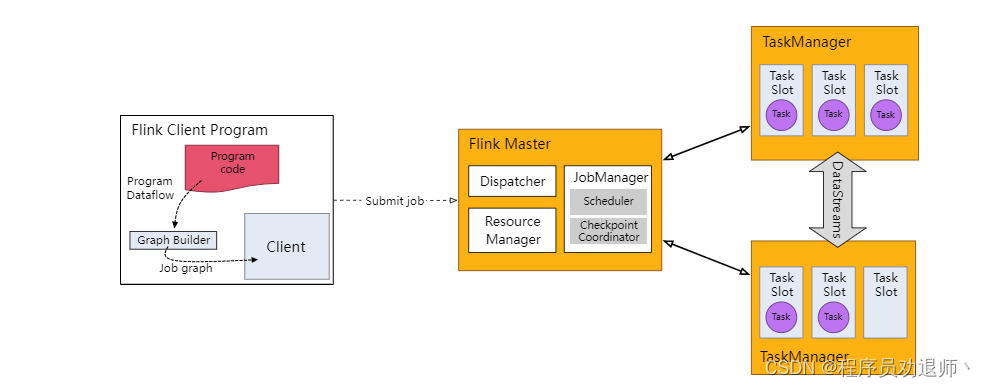
每个 Flink 应用都需要有执行环境,在该示例中为 env。流式应用需要用到 StreamExecutionEnvironment。
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。
注意,如果没有调用 execute(),应用就不会运行。
2. Dataflows数据流图
在flink中 ,一切都是数据流,所以对于批计算来说,那只是流计算的一个特例而已
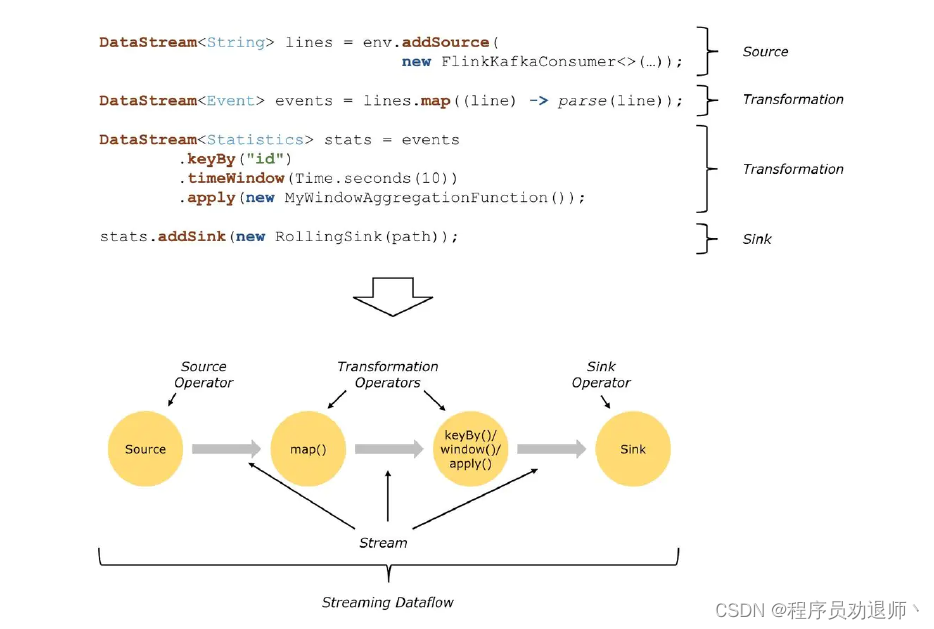
Flink Dataflows是由三部分组成,分别是:source、transformation、sink结束
source数据源会源源不断的产生数据,transformation将产生的数据进行各种业务逻辑的数据处理,最终由sink输出到外部(console、kafka、redis、DB......)
基于Flink开发的程序都能够映射成一个Dataflows
3. source类别简介
在真实的应用中,最常用的数据源是那些支持低延迟,高吞吐并行读取以及重复(高性能和容错能力为先决条件)的数据源,例如 Apache Kafka,Kinesis 和各种文件系统。REST API 和数据库也经常用于增强流处理的能力(stream enrichment)
3.1 也可以直接把集合当做数据源
基于本地集合的数据源,一般用于测试场景,没有太大意义
val env = StreamExecutionEnvironment.getExecutionEnvironment
val unit = env.fromElements(1, 2, 3)
val unit1 = env.fromCollection(List(1,2,3,4,5))3.2 可以直接读取hdfs数据
如果读取的是HDFS上的文件,那么需要导入Hadoop依赖
val env = StreamExecutionEnvironment.getExecutionEnvironment
val textStream = env.readTextFile("hdfs://node01:9000/flink/data")3.3 可以直接从文件中读取
val env = StreamExecutionEnvironment.getExecutionEnvironment
val textStream = env.readTextFile("data/flink")3.4 获取数据到流中的便捷方法是用 socket
val env = StreamExecutionEnvironment.getExecutionEnvironment
val hdfsWC = env.socketTextStream("node1",8888)3.5 Kafka Source
Flink接受Kafka中的数据,首先先配置flink与kafka的连接器依赖
https://nightlies.apache.org/flink/flink-docs-release-1.9/dev/connectors/kafka.html
3.6 Custom Source 自定义数据源
基于SourceFunction接口实现单并行度数据源
基于ParallelSourceFunction接口实现多并行度数据源
4. Transformations算子简介
提供好的算子
如果不能满足需求则可以使用process算子,
5. sink
内置:redis kafaka
本地文件: File(HDFS2.7以上)
自定义:socket
原文地址:https://www.jb51.cc/wenti/3280949.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

