

目录
简单数据操作
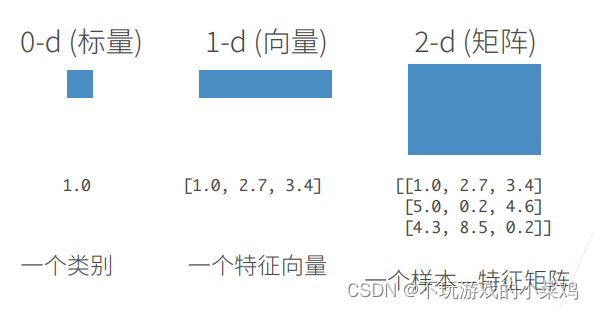
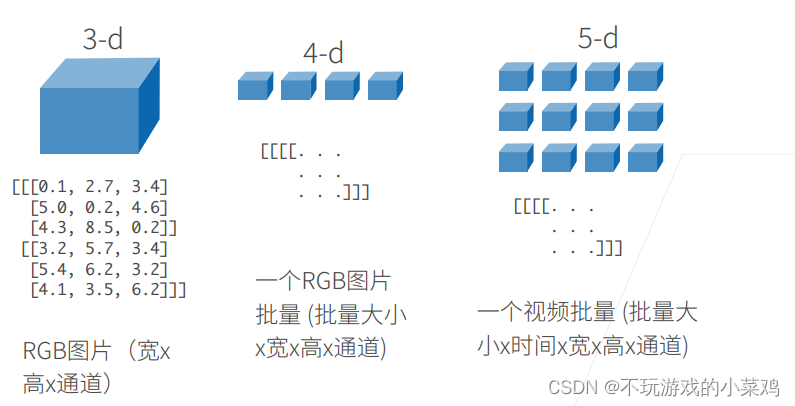
N维数组是机器学习和神经网络的主要数据结构
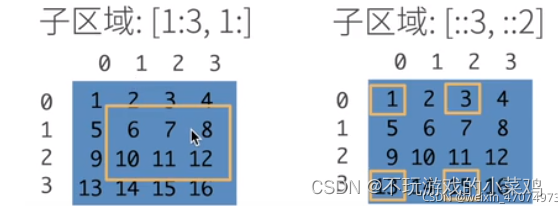
元素访问
比如数组[[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]]
访问一个元素:[1,2])(7)
访问一行元素:[1,:] ([5,6,7,8])
访问一列元素:[:,1](2,6,10,14)
子区域:[1:3,1:](表示第1行到第3行的开区间结束,即第1行和第2行,第1列开始到后面所有列)
子区域:[::3,::2](表示把第0行和第3行拿出来,再把第0列和第2列拿出来)
元素基本操作
创建数组(形状、数据类型、每个元素的数值)
访问元素(按特定单数值、行、列、特定区域)
常见标准算数运算(+ - * / ** e**() )
张量合并(torch.cat((X,Y),dim = 0))
逻辑运算符(X==Y)
所有元素求和(X.sum() )
通过广播机制来进行求和()
为多个元素赋值为相同的值,先索引再为其赋值
转换为numpy张量 (torch.tensor() / .numpy() )
将大小为1的张量转换为python标量
import torch
x = torch.arange(20)# 创建一个行向量 x
print(x)#打印行向量x
print(x.shape)#通过shape属性查看张量形状
print(x.numel)#
X = x.reshape(4, 5)#改为4行5列
y = torch.zeros((2,3))#2行3列 0
z = torch.ones((3,4))#2行4列 1
print(y,z)
a = torch.randn(3, 4)#随机标准高斯采样 3行4列
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])数据预处理
使用pandas 来进行导入数据文件
Data = pd.read_csv(data_file)
Data
预测缺失数据
插值和删除
import pandas
dada = pd.read_csv(data_file)
print(data)原文地址:https://www.jb51.cc/wenti/3281851.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

