

一.认识微服务技术栈

(1)服务集群:根据业务功能模块拆分成一个个独自的项目,每个项目完成独自的功能,每个项目又称为独自的服务,每个服务构成了一个服务集群;
(2)注册中心:由于服务多,肯定要记录每个服务的信息(ip 端口 功能)就用到了注册中心。每个服务在注册中心中注册,当用户进行调用服务,它首先到注册中心拉取服务信息再去调用相对于的服务
(3)配置中心:每个服务都会有各自的配置信息,便于统一管理,使用到配置中心,如果想更改服务的配置中心,就在配置中心上进行更改,配置中心会通知相关的服务实现配置的日更新
(4)服务网关:是为了校验身份和请求路由,负载均衡
(5)分布式缓存:目的是当一个请求来访问数据库,首先是在缓存中查找是否存在,不存在从数据库中进行查询再放入到缓存中,提高效率,这里的缓存为分布式缓存(集群),在查找的同时也有搜索功能,就用到了分布式搜索(用于复杂的查询)
(6)消息队列:由于一个请求,请求链路估计很长,各种服务之间的调用频繁,性能下降;消息队列的作用于通知,通知服务就可以调用,之前的服务结束了,会缩短了链路,加快了效率(用于并发)

(7)系统监控链路追踪,分布式日志服务:用于服务的错误的信息进行排查
(8)Jenkins:用于自动化部署(持续集成)
以上图为完整的微服务技术栈
二.认识微服务
1.单体架构
单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署。


优点:架构简单 部署成本低
缺点:耦合度高(不利于大项目的开发,改一个动全身)
2.分布式架构
分布式架构∶根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务。

优点:降低服务耦合,有利于服务升级拓展
3.微服务
(1) 微服务是一种经过良好架构设计的分布式架构方案,微服务架构特征:
1.单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
2.面向服务:微服务对外暴露业务接口
3.自治:团队独立、技术独立、数据独立、部署独立
4.隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题

常见的微服务框架 :SpringCloud和阿里巴巴的dubbo
微服务技术对比:

(2)SpringCloub
1.SpringCloud是目前国内使用最广泛的微服务框架。官网地址: https://spring.io/projects/spring-cloud。
2.SpringCloud集成了各种微服务功能组件,并基于SpringBoot实现了这些组件的自动装配,从而提供了良好的开箱即用体验:

注:SpringCloub与SpringBoot的版本兼容关系如下:

(3) 服务拆分及远程调用
(i) 服务拆分注意事项
1.不同微服务,不要重复开发相同业务
2.微服务数据独立,不要访问其它微服务的数据库
3.微服务可以将自己的业务暴露为接口,供其它微服务调用
(ii) 远程调用
本质就是发送http请求
(1)注册RestTemplate 例如在order-service的OrderApplication中注册RestTemplate
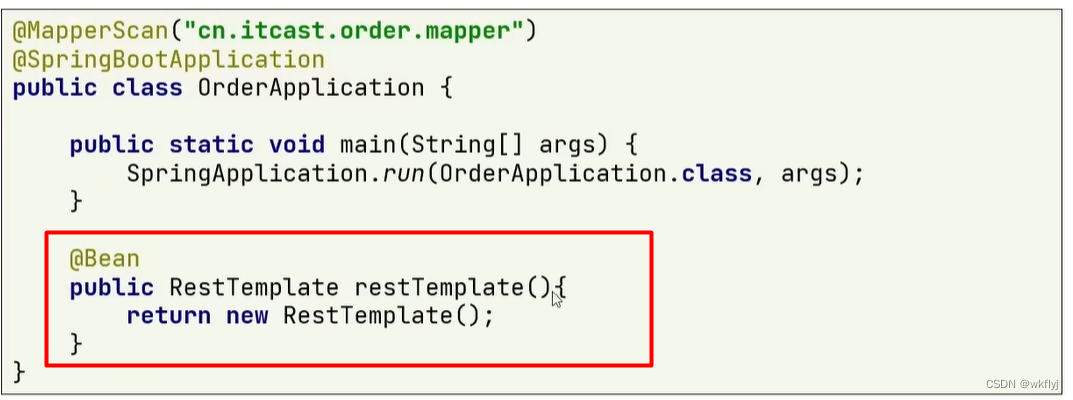
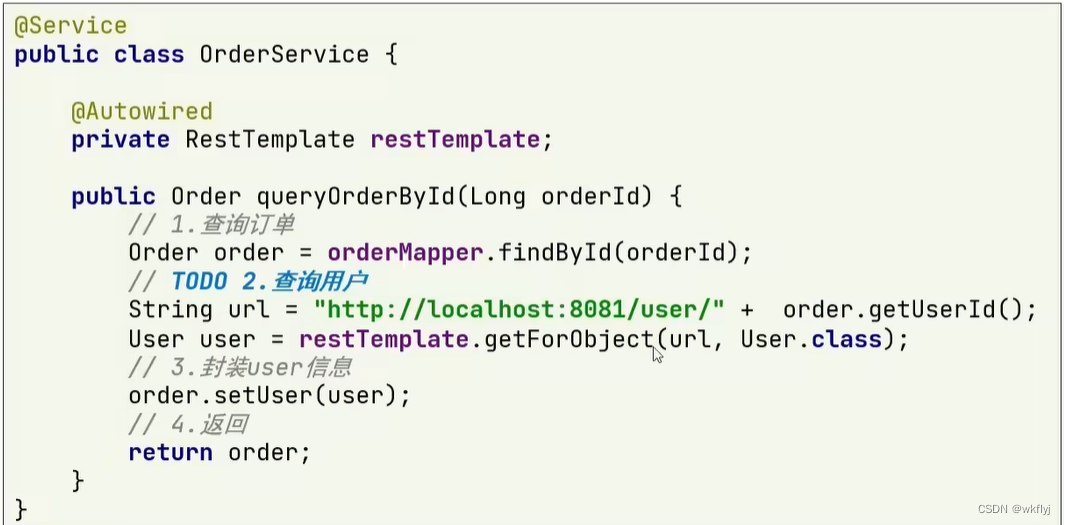
(2) 服务远程调用RestTemplate 修改order-service的查询方法 远程调用就是请求url路径
调用方式: 基于RestTemplate发起http请求实现远程调用
http请求做远程调用是与语言无关的调用,只要知道对方的ip,端口 接口路径,请求参数即可
(iii) 提供者与消费者
服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)
总结:
服务调用关系
服务提供者:暴露接口给其它微服务调用
服务消费者:调用其它微服务提供的接口
提供者与消费者角色其实是相对的
一个服务可以同时是服务提供者和服务消费者
总结:
单体架构特点
·简单方便,高度耦合,扩展性差,适合小型项目。例如:学生管理系统
分布式架构特点
·松耦合,扩展性好,但架构复杂,难度大。适合大型互联网 项目,例如:京东、淘宝
微服务:一种良好的分布式架构方案
·优点:拆分粒度更小、服务更独立、耦合度更低·缺点:架构非常复杂,运维、监控、部署难度提高
4.Eureka注册中心
(1) Eureka的作用:
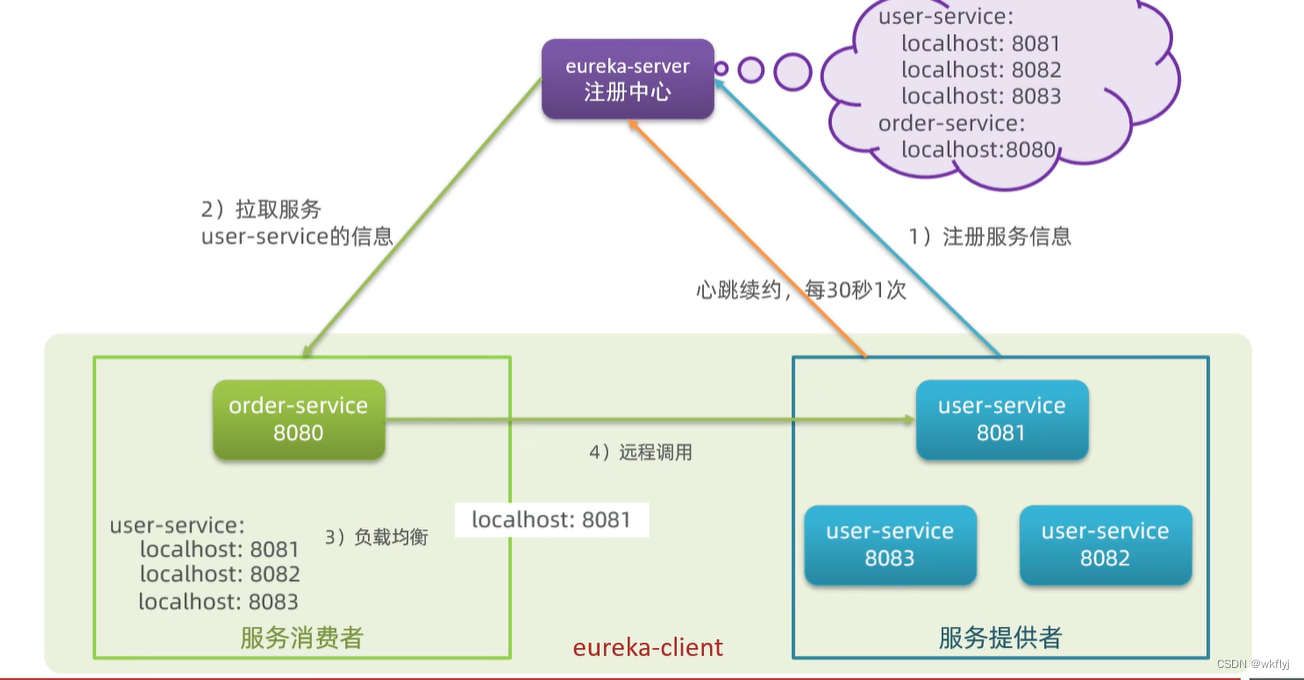
1.消费者该如何获取服务提供者具体信息?
服务提供者启动时向eureka注册自己的信息
eureka保存这些注册信息
消费者根据服务名称向eureka拉取提供者信息
2.如果有多个服务提供者,消费者该如何选择?
服务消费者利用负载均衡算法,从服务列表中挑选一个
3.消费者如何感知服务提供者健康状态?
服务提供者会每隔30秒向EurekaServer发送心跳请求,报告健康状态
eureka会更新记录服务列表信息,心跳不正常会被剔除
消费者就可以拉取到最新的信息
在Eureka架构中,微服务角色有两类:
1.EurekaServer:服务端,注册中心
记录服务信息
心跳监控
2.EurekaClient:客户端
Provider:服务提供者,例如案例中的user-service
注册自己的信息到EurekaServer
每隔30秒向EurekaServer发送心跳
consumer:服务消费者,例如案例中的order-service
根据服务名称从EurekaServer拉取服务列表
基于服务列表做负载均衡,选中一个微服务后发起远程调用
(2)搭建EurekaService
搭建EurekaServer服务步骤如下:
1.创建项目,引入spring-cloud-starter-netflix-eureka-server的依赖

2.编写启动类,添加@EnableEurekaServer注解
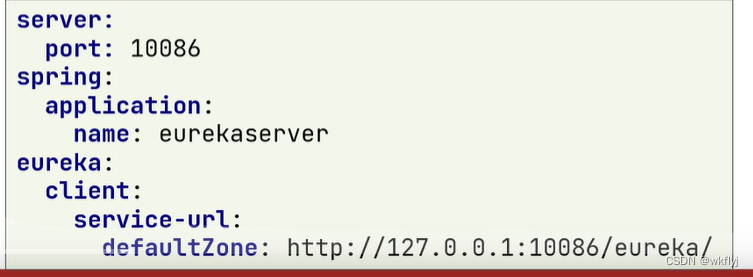
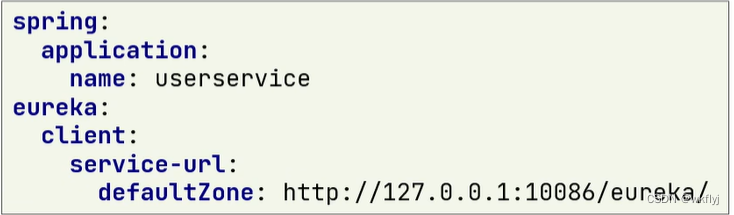
3.添加application.yml文件,编写下面的配置:
(3)注册user-service
将user-service服务注册到EurekaServer步骤如下:
1.在user-service项目引入spring-cloud-starter-netflix-eureka-client的依赖

(4) 在order-service 完成服务拉取
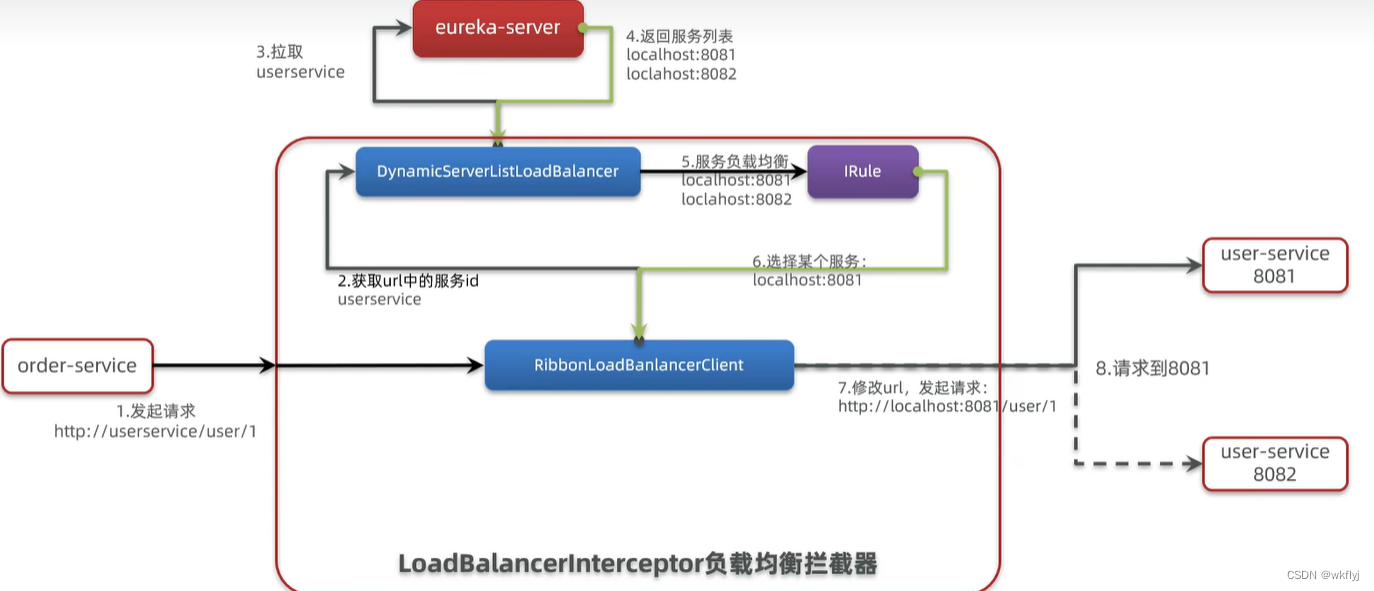
服务拉取是基于服务名称获取服务列表,然后在对服务列表做负载均衡(Ribbon)
1.修改OrderService的代码,修改访问的url路径,用服务名代替ip、端口︰

2.在order-service项 目的启动类OrderApplication中的RestTemplate添加负载均衡注解: .

总结:
1.搭建EurekaServer
引入eureka-server依赖
添加@EnableEurekaServer注解
在application.yml中配置eureka地址
2.服务注册
引入eureka-client依赖
在application.yml中配置eureka地址
3.服务发现
引入eureka-client依赖
在application.yml中配置eureka地址
给RestTemplate添加@L oadBalanced注解
用服务提供者的服务名称远程调用
5. Ribbon 负载均衡
(1).负载均衡流程
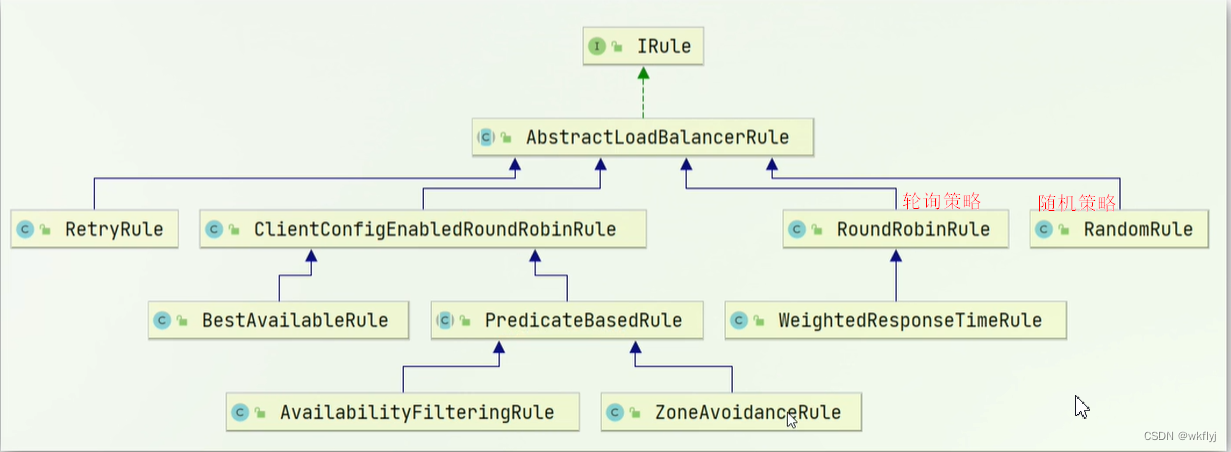
(2) 负载均衡策略
Ribbon的负载均衡规则是一个叫做lRule的接 来定义的,每一-个子接口都是一种规则:

1.代码方式:在order-service中的OrderApplication类中, 定义一个新的IRule:
(全局,针对任意一个服务都是随机的)

(局部,针对某一个服务都是随机的,指定服务名称)

(3)饥饿加载
Ribbon默认是采用懒加载,即第一-次访问时才 会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时, 通过下面配置开启饥饿加载:

总结:
1. Ribbon负载均衡规则
规则接口是IRule
默认实现是ZoneAvoidanceRule,根据zone选择服务列表,然后轮询
2.负载均衡自定义方式
代码方式:配置灵活,但修改时需要重新打包发布
配置方式:直观,方便,无需重新打包发布,但是无法做全局配置
3.饥饿加载
开启饥饿加载
6.Nacos注册中心
(1)认识Nacos
Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件。相比Eureka功能更加丰富,在国内受欢迎程度较高。
(2)服务注册到Nacos
1.在demo父工程中添加spring-cloud-alilbaba的管理依赖: .

2.注释掉order-service和user-service中 原有的eureka依赖。
3.添加nacos的客 户端依赖:

4. 修改user-service&order-service中的application.ym|文件, 注释eureka地址,添加nacos地址:

(3) nacos服务分级存储模型
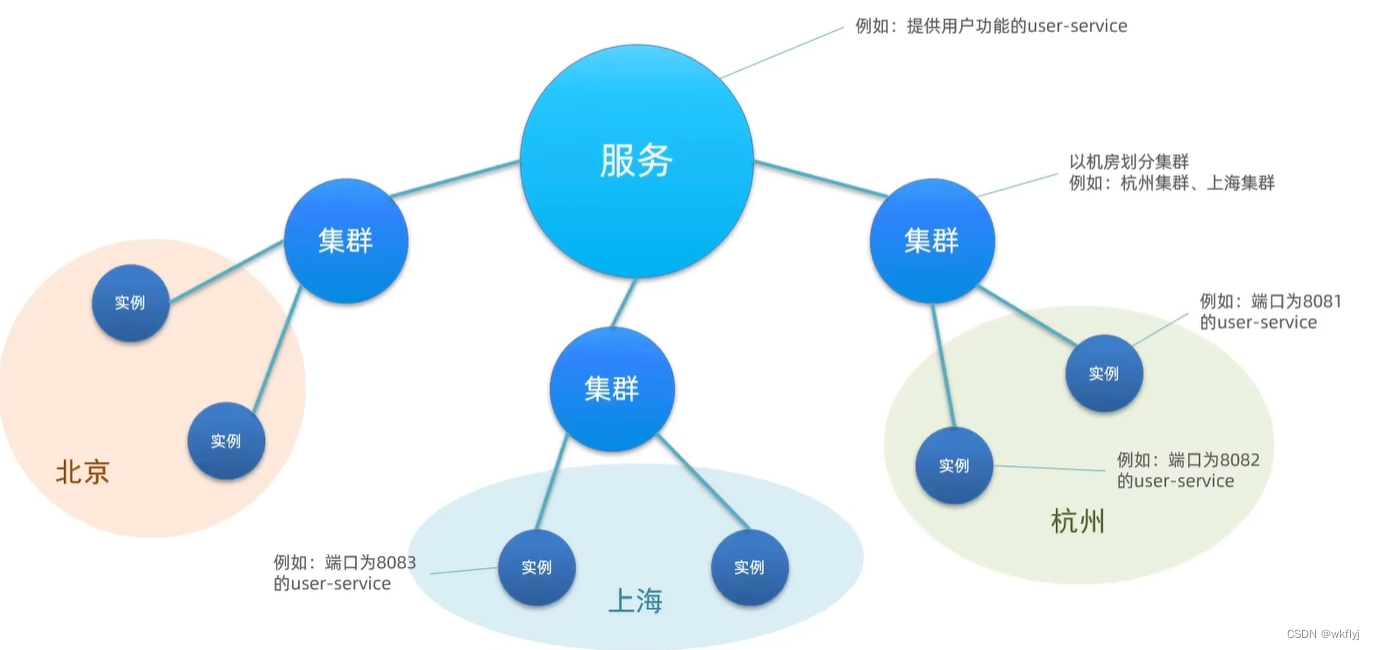
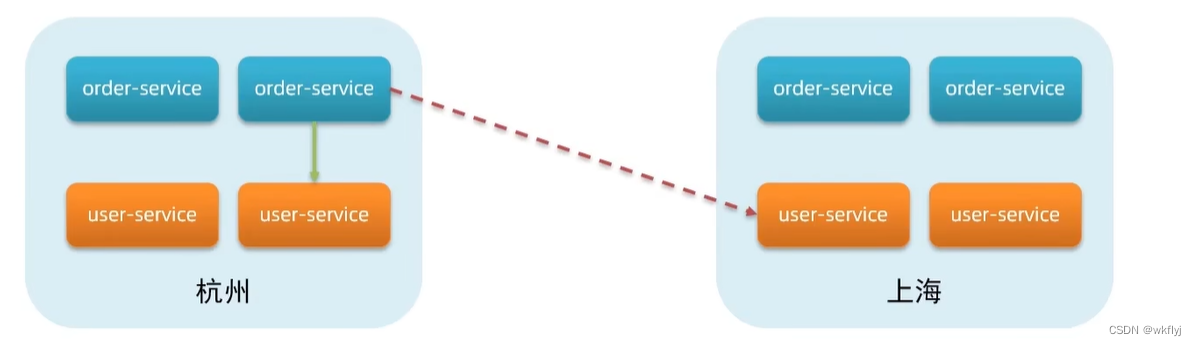
服务调用尽可能选择本地集群的服务,跨集群调用延迟较高
本地集群不可访问时,再去访问其它集群
服务集群属性

总结:
1. Nacos服务分级存储模型
①一级是服务,例如userservice
②二级是集群,例如杭州或上海
③三级是实例,例如杭州机房的某台部署了userservice的服务器
2.如何设置实例的集群属性
①修改application.yml文件, 添加
spring.cloud.nacos.discovery.cluster-name属性即可
(4)根据集群负载均衡
1.修改order-service中的application.ymI, 设置集群为HZ:

2.然后在order-service中设置负载均衡的IRule为NacosRule, 这个规则优先会寻找与自己同集群的服务: (在同集群中是随机策略,如果同集群没有该服务,会跨服务调用发出一个警告)

总结:
1. NacosRule负载均衡策略
①优先选择同集群服务实例列表
②本地集群找不到提供者,才去其它集群寻找,并且会'报警告
③确定了可用实例列表后,再采用随机负载均衡挑选实例
2.实例的权重控制
①Nacos控制台可以设置实例的权重值,0~1之间
②同集群内的多个实例,权重越高被访问的频率越高
③权重设置为0则完全不会被访问
(5)环境隔离 - namespace
Nacos中服务存储和数据存储的最外层都是一个名为namespace的东西, 用来做最外层隔离
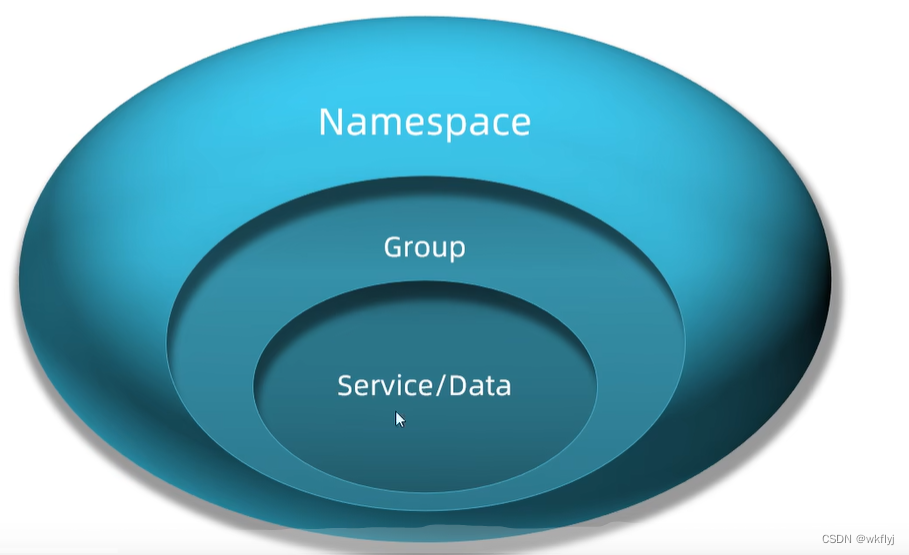
1.在Nacos控制台可以创建namespace,用来隔离不同环境
2.然后填写一个新的命名空间信息:
3.保存后会在控制台看到这 个命名空间的id:
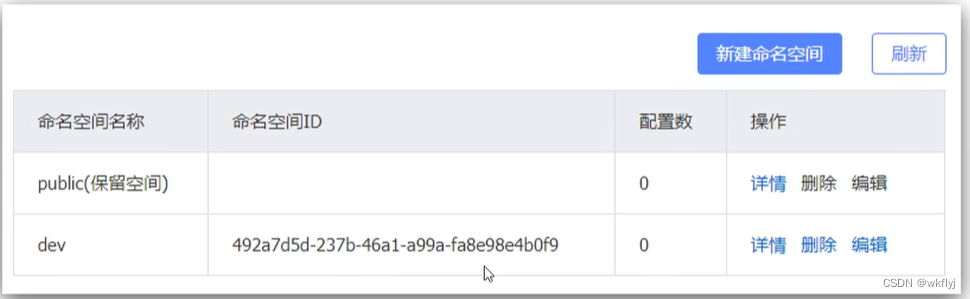
4.修改order-service的application.yml, 添加namespace: .
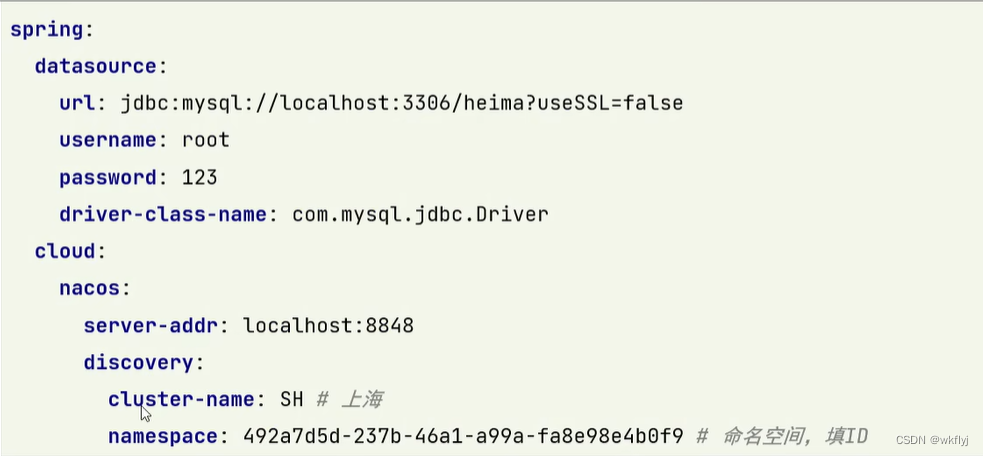
总结:
1.Nacos环境隔离
①namespace用来做环境隔离
②每个namespace都有唯一id
③不同namespace 下的服务不可见(要是可见放到同一个namespace空间下)
nacos注册中心细节分析
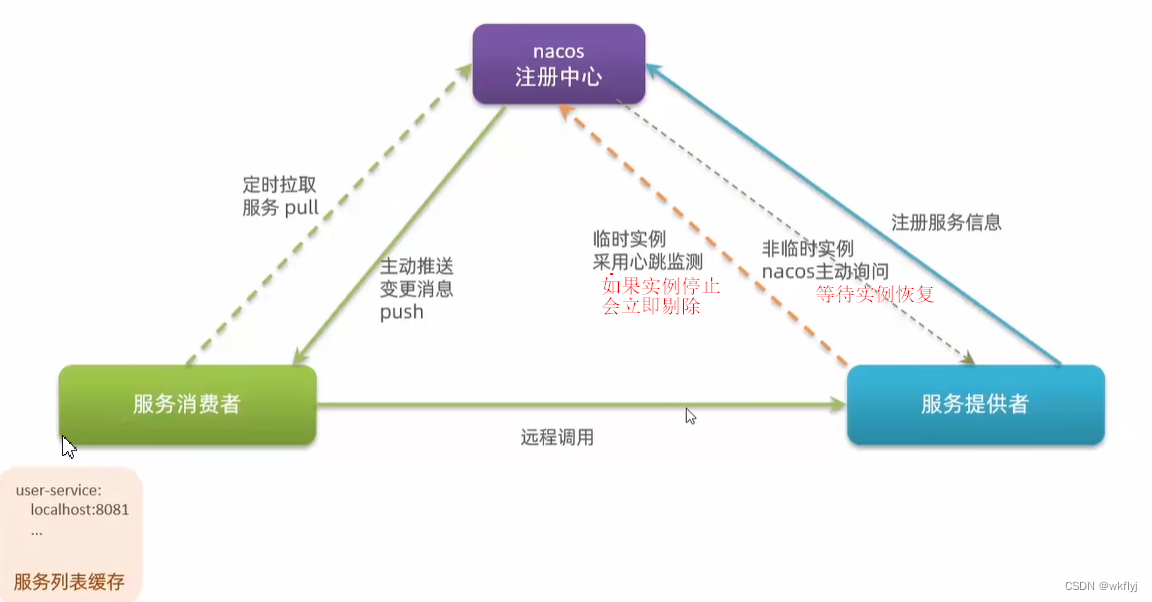
临时实例和非临时实例
服务注册到Nacos时,可以选择注册为临时或非临时实例,通过下面的配置来设置:

总结:
1. Nacos与eureka的共同点
①都支持服务注册和服务拉取
②都支持服务提供者心跳方式做健康检测
2. Nacos与 Eureka的区别
①Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
②临时实例心跳不正常会被剔除,非临时实例则不会被剔除
③Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
④Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式; Eureka采用AP方式
(6)Nacos配置管理
1.统一配置管理
(i)配置更改热更新(当配置发生改变,不会重启微服务,会读取nacos的配置)
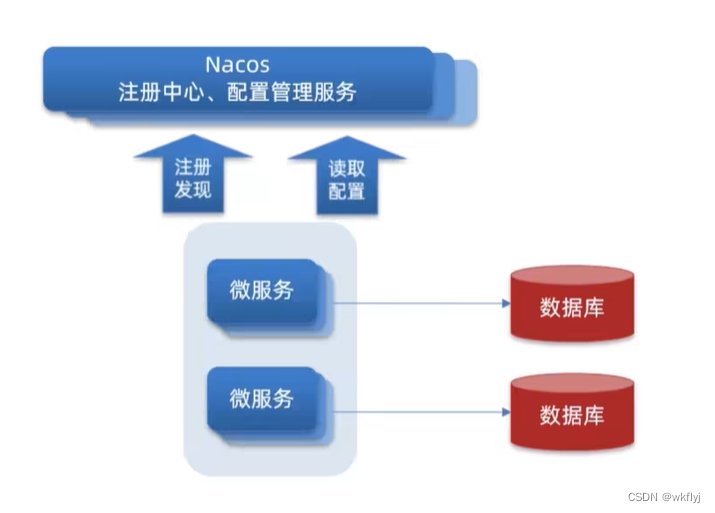
(ii)nacos添加配置信息
步骤一:在nacos中添加配置信息:
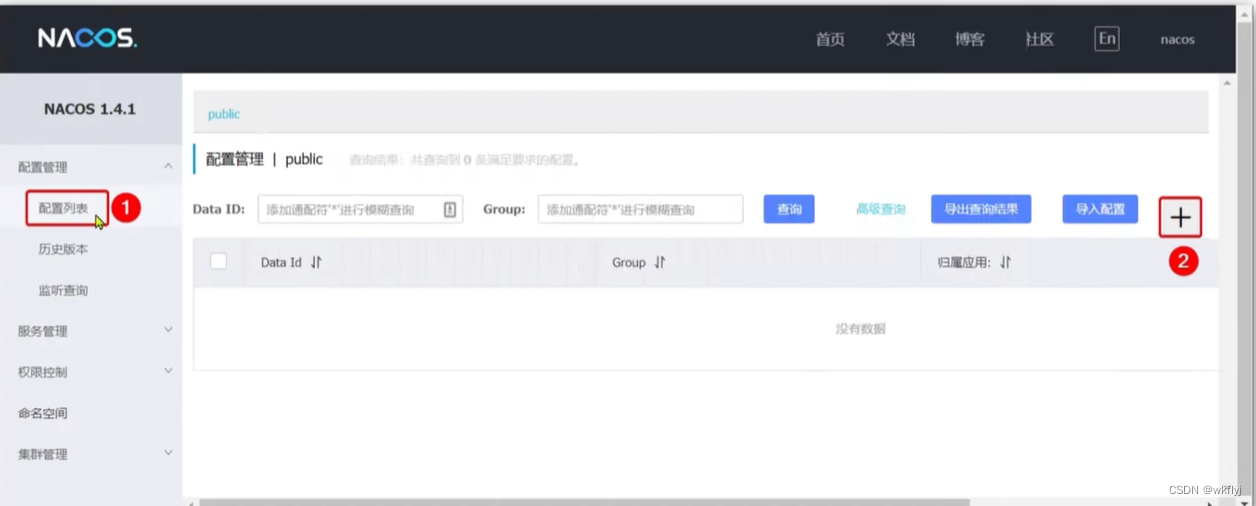
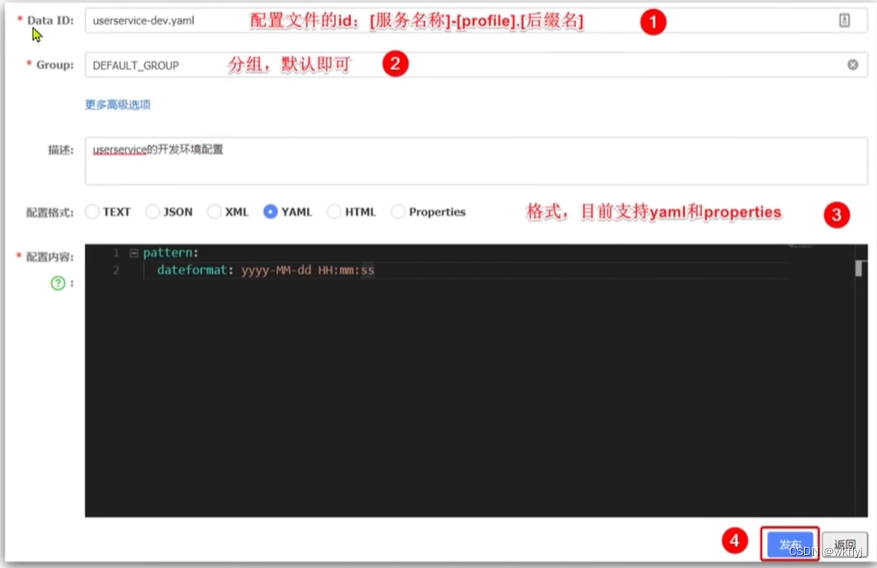
步骤二:在弹出表单中填写配置信息:
(iii)配置获取步骤如下
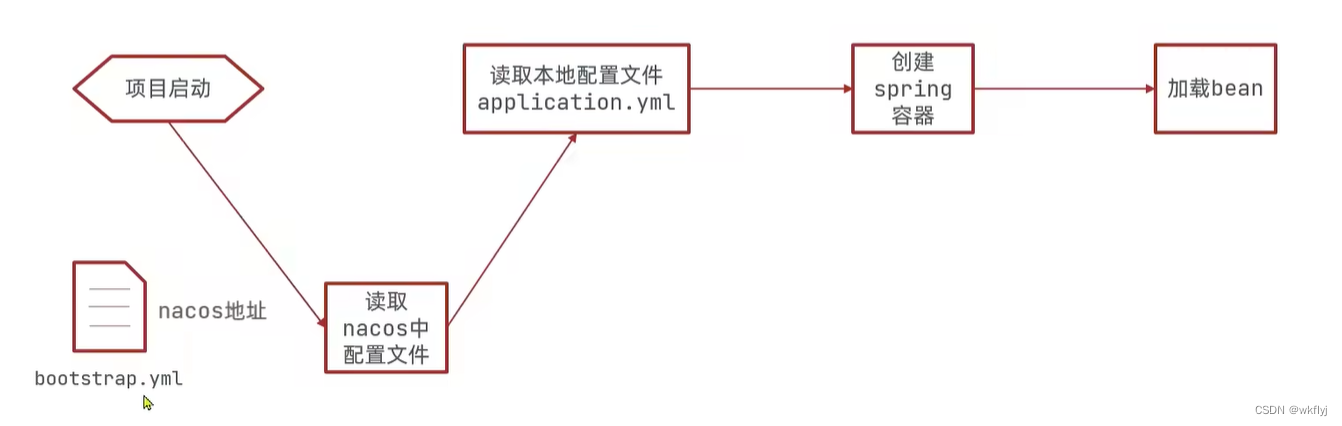
项目启动时,会优先读取bootstrap.yml,比application优先级很高,所以应把读取nacos配置地址写入bootstrap.xml,可以完成先读取nacos的配置,再与application.yml配置相结合
配置获取
步骤一: 引入Nacos的配置管理客户端依赖:

步骤二:在userservice中的resource目录添加一个bootstrap.ym|文件, 这个文件是引导文件,优先级高于application.yml
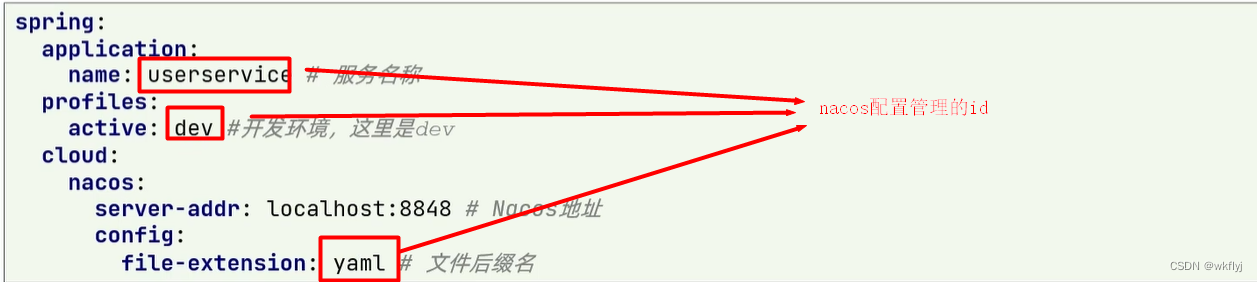
步骤三:服务的读取--我们在user-service中将pattern.dateformat这个属性注入到UserController中做测试(如果浏览器中显示的格式为yyyy-mm-dd HH-MM-SS的格式,说明已经读取到nacos的配置)

总结:
将配置交给Nacos管理的步骤
①在Nacos中添加配置文件
②在微服务中引入nacos的config依赖
③在微服务中添加bootstrap.yml,配置nacos地址、当前环境、服务名称、文件后缀名。这些决定了程序启动时去nacos读取哪个文件
2.配置自动刷新
Nacos中的配置文件变更后,微服务无需重启就可以感知。不过需要通过下面两种配置实现:
方式一 : 在@Value注入的变量所在类上添加注解@RefreshScope
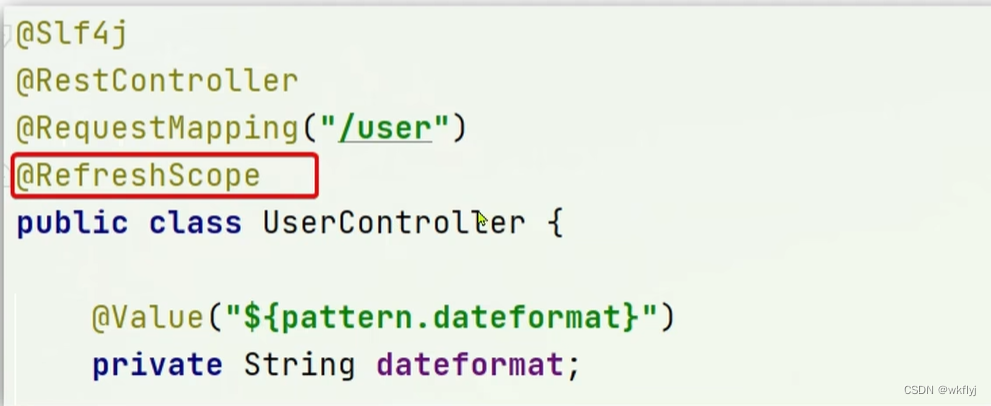
方式二:使用@ConfigurationProperties注解

总结:
Nacos配置更改后,微服务可以实现热更新,方式:
①通过@Value注解注入,结合@RefreshScope来刷新
②通过@ConfigurationProperties注入, 自动刷新
注意事项:
不是所有的配置都适合放到配置中心,维护起来比较麻烦,建议将一些关键参数,需要运行时调整的参数放到nacos配置中心,一-般都是自定义配置
3. 多环境配置共享
(i) 微服务启动时会从nacos读取多个配置文件:
[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml
[spring.application.name].yaml,例如:userservice.yaml
无论profile如何变化,[spring.application.name].yaml这个文件一定会加载,因此多环境共享配置可以写入这个文件
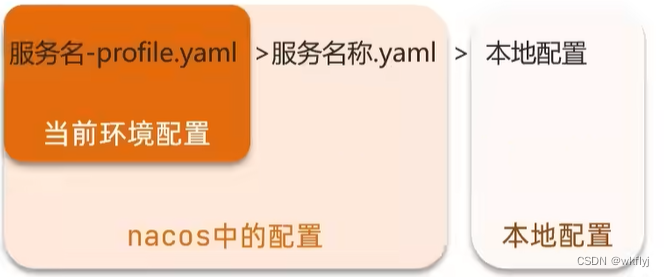
(ii)多种配置的优先级:
总结:
微服务会从nacos读取的配置文件:
[服务名]-[spring.profile.active].yaml,环境配置[服务名].yaml,默认配置,多环境共享
优先级:
[服务名]-[环境].yaml >[服务名].yaml >本地配置
4.Nacos集群搭建
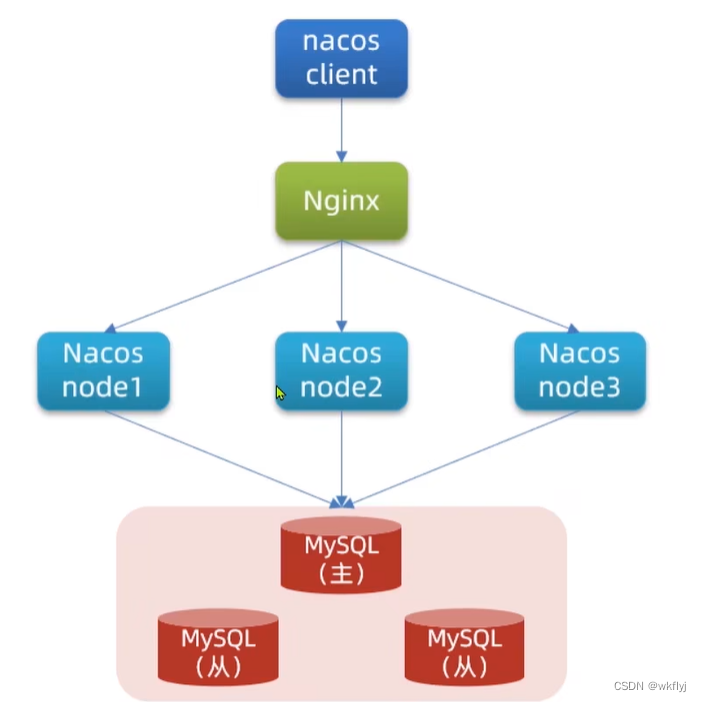
(i)集群结构图
(ii)搭建集群
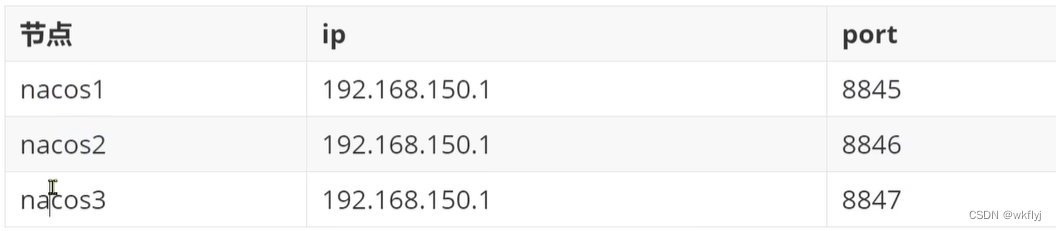
三个nacos节点的地址
(a)进入nacos的conf目录,修改配置文件cluster.conf.example,重命名为cluster.conf:
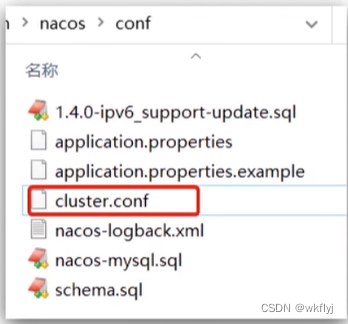

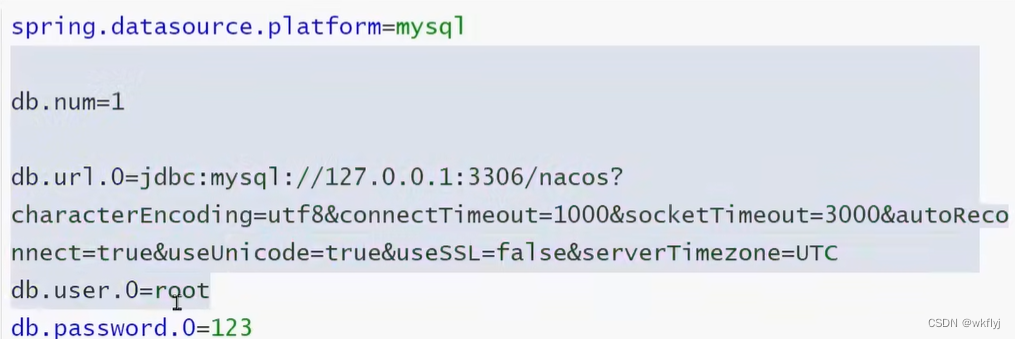
(b)修改application.properties文件,添加数据库配置
(c)将nacos文件夹复制三份,分别命名为: nacos1、nacos2、nacos3

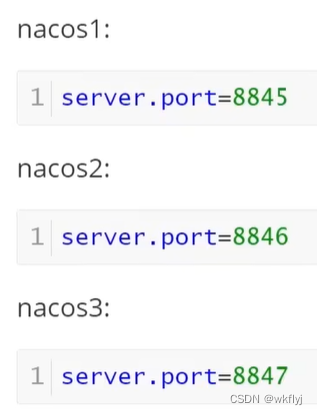
(d)修改三个文件中application。properties
(e)分别启动三个nacos节点
startup.cmd
(f)配置Nginx 修改conf/Nginx.conf文件,配置如下:
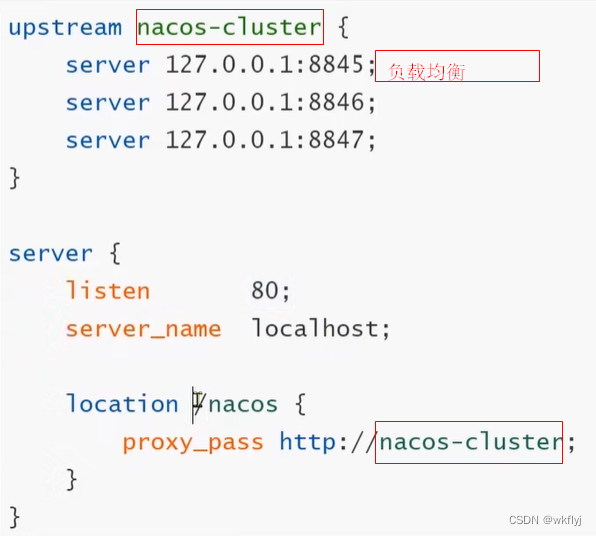
(g)在浏览器中访问http://localhost:80/nacos/ 它会在三个nacos集群中做一个负载均衡
总结:
集群搭建步骤:
①搭建MysqL集群并初始化数据库表
②下载解压nacos
③修改集群配置(节点信息)、数据库配置
④分别启动多个nacos节点
⑤Nginx反向代理
7.http客户端Feign
出现Feign的原因:
RestTemplate方式调用存在的问题
先来看我们以前利用RestTemplate发起远程调用的代码:

存在下面的问题:
(1)代码可读性差,编程体验不统一 (2)参数复杂URL难以维护
(1)定义和使用Feign客户端
使用Feign的步骤如下:
1.引入依赖

2.在order-service的启动类添加注解开启Feign的功能:
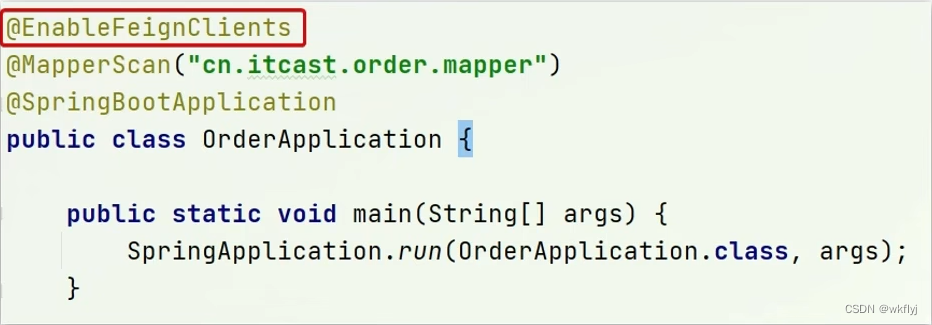
3.编写Feign客户端:Feign
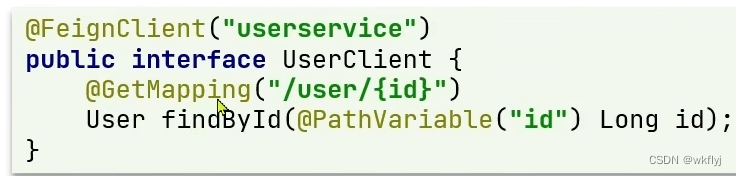
主要是基于SpringMVC的注解来声明远程调用的信息,比如:
1)服务名称:userservice
(2)请求方式:GET
(3)请求路径:/user/{id}
(4)请求参数:Long id
(5)返回值类型:User
(2)自定义Feign的配置
Feign运行自定义配置来覆盖默认配置,可以修改的配置如下:

配置Feign日志有两种方式:
方式一:配置文件方式
全局生效:

局部生效:

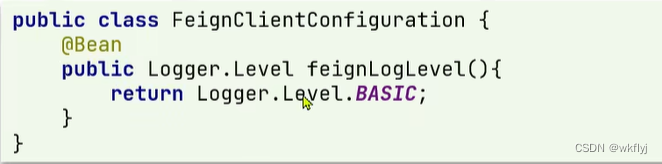
① 而后如果是全局配置,则把它放到@EnableFeignClients这个注解中:

② 如果是局部配置,则把它放到@FeignClient这个注解中:
![]()
总结:
Feign的日志配置:
1.方式一是配置文件,feign.client.config.xxx.loggerLevel
①如果xxx是default则代表全局
②如果xxx是服务名称,例如userservice则代表某服务
2.方式二是java代码配置Logger.Level这个Bean
①如果在@EnableFeignClients注解声明则代表全局
②如果在@FeignClient注解中声明则代表某服务
(3)Feign的性能优化
Feign底层的客户端实现:
URLConnection:默认实现,不支持连接池
Apache HttpClient :支持连接池
OKHttp:支持连接池
因此优化Feign的性能主要包括:
使用连接池代替默认的URLConnection
日志级别,最好用basic或none
1.连接池配置
引入依赖:

配置连接池

(4)Feign的最佳实践
方式一(继承)∶给消费者的FeignClient和提供者的controller定义统一的父接口作为标准。(不推荐)
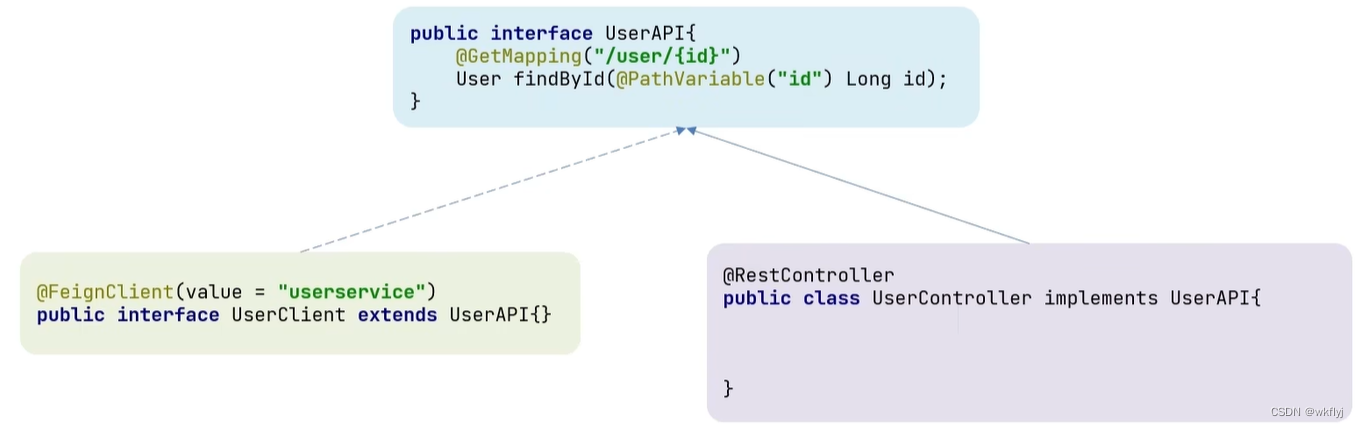
缺点:
服务紧耦合
父接口参数列表中的映射不会被继承
方式二(抽取)︰将FeignClient抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用
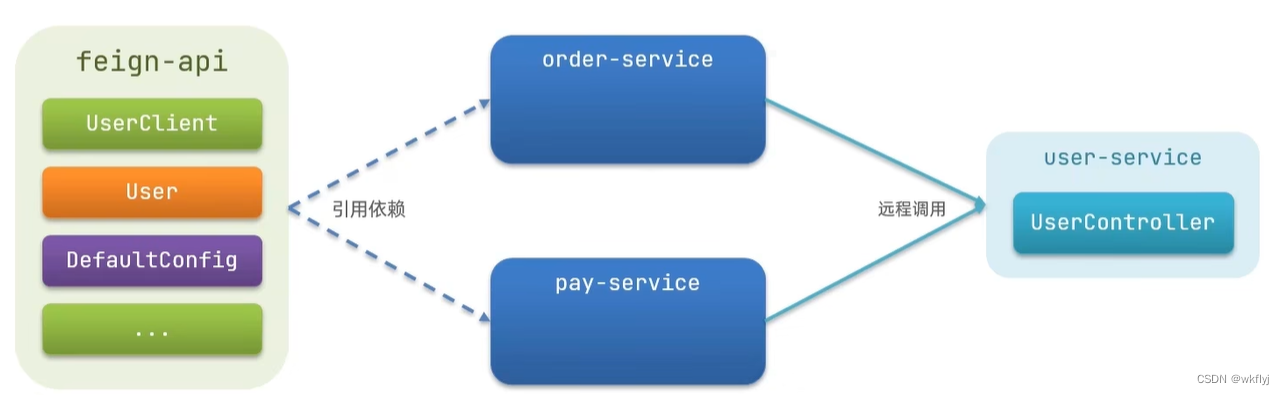
实现最佳实践方式二的步骤如下:
1.首先创建一个module,命名为feign-api,然后引入feign的starter依赖
2将order-service中编写的UserClient、User、DefaultFeignconfiguration都复制到feign-api项目中3.在order-service中引入feign-api的依赖
4.修改order-service中的所有与上述三个组件有关的import部分,改成导入feign-api中的包5.重启测试
当定义的Feignclient不在SpringBootApplication的扫描包范围时,这些FeignClient无法使用
有两种方式解决:
方式一:指定FeignClient所在包

方式二:指定FeignClient字节码
![]()
总结:
不同包的FeignClient的导入有两种方式:
在@EnableFeignClients注解中添加basePackages,指定FeignClient所在的包
在@EnableFeignClients注解中添加clients,指定具体FeignClient的字节码
8.统一网关Gateway
1.为什么需要网关
网关的功能:(1)身份认证和权限校验 (2)服务路由、负载均衡 (3)请求限流
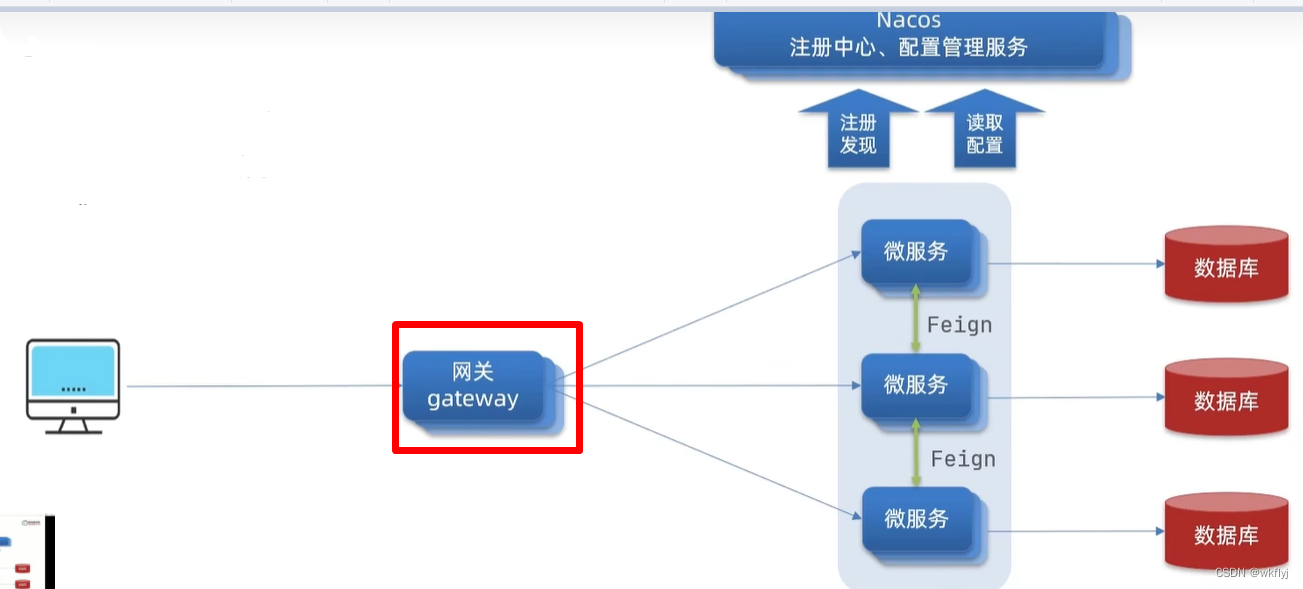
在SpringCloud中网关的实现包括两种: (1)gateway (2)zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能
2.搭建网关服务
搭建网关服务的步骤:
1. 创建新的module,引入SpringCloudGateway的依赖和nacos的服务发现依赖:

2.编写路由配置及nacos地址

3.网关服务流程图
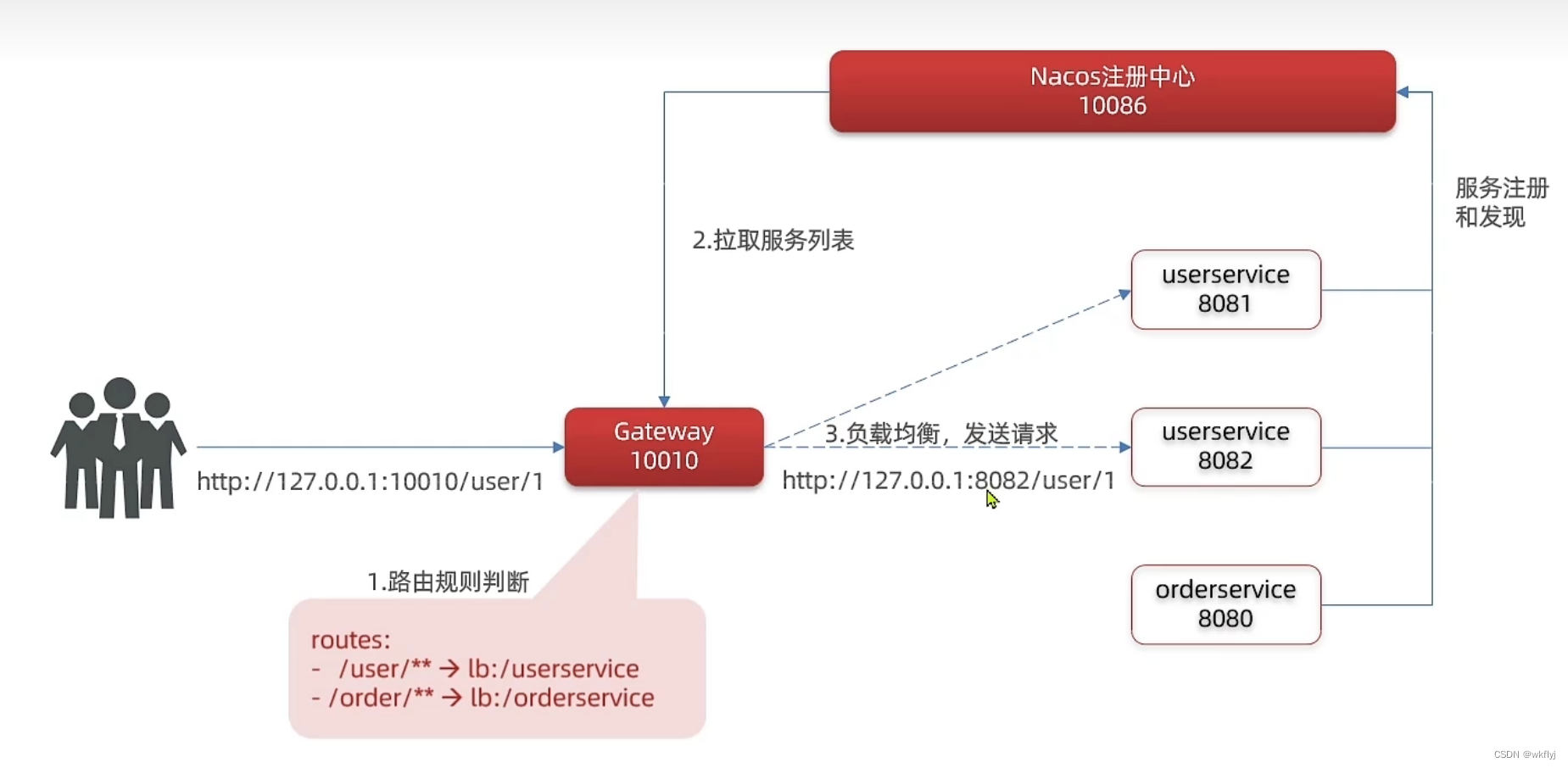
网关搭建步骤总结:
1.创建项目,引入nacos服务发现和gateway依赖
2.配置application.yml,包括服务基本信息、nacos地址、路由路由配置包括:
1.路由id:路由的唯一标示
2.路由目标(uri) :路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
3.路由断言( predicates) :判断路由的规则,如果符合路由规则,则转发对应的服务
4.路由过滤器(filters) :对请求或响应做处理心
3.断言工厂
1.路由断言工厂Route Predicate Factory
我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件
例如Path=/user/**是按照路径匹配,这个规则是由org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来处理的
像这样的断言工厂在SpringCloudGateway还有十几个。
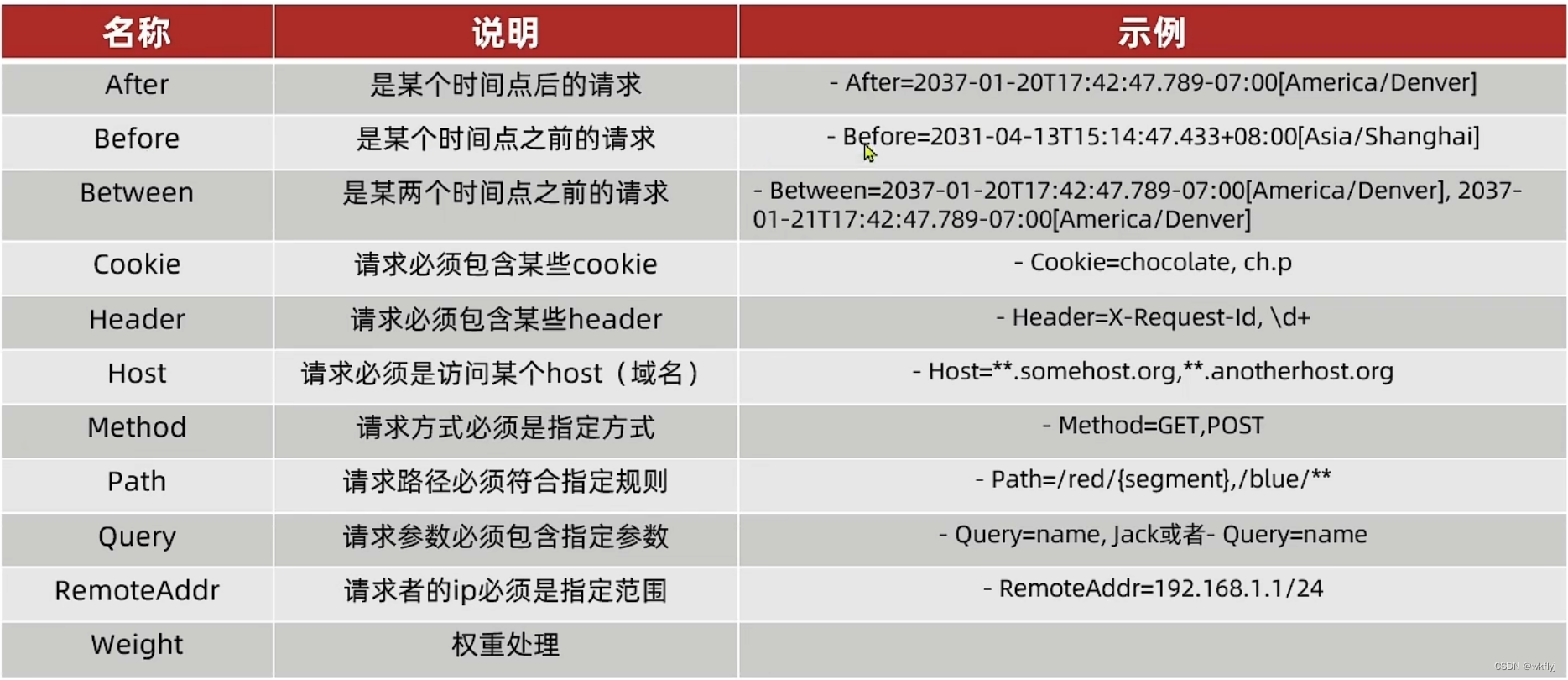
总结:
问1:PredicateFactory的作用是什么?
答:读取用户定义的断言条件,对请求做出判断
问2:Path=/user/**是什么含义?
答:路径是以/user开头的就认为是符合的
4.路由过滤器GatewayFilter
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:
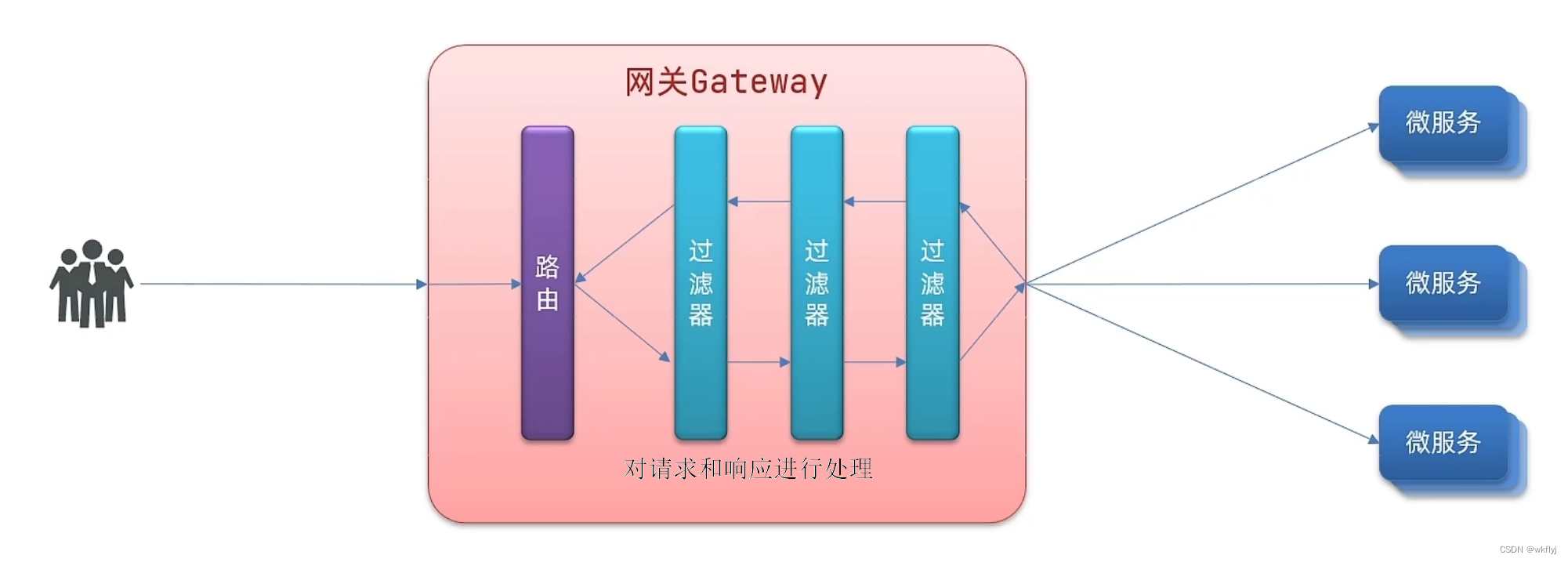
Spring提供了31种不同的路由过滤器工厂。例如:
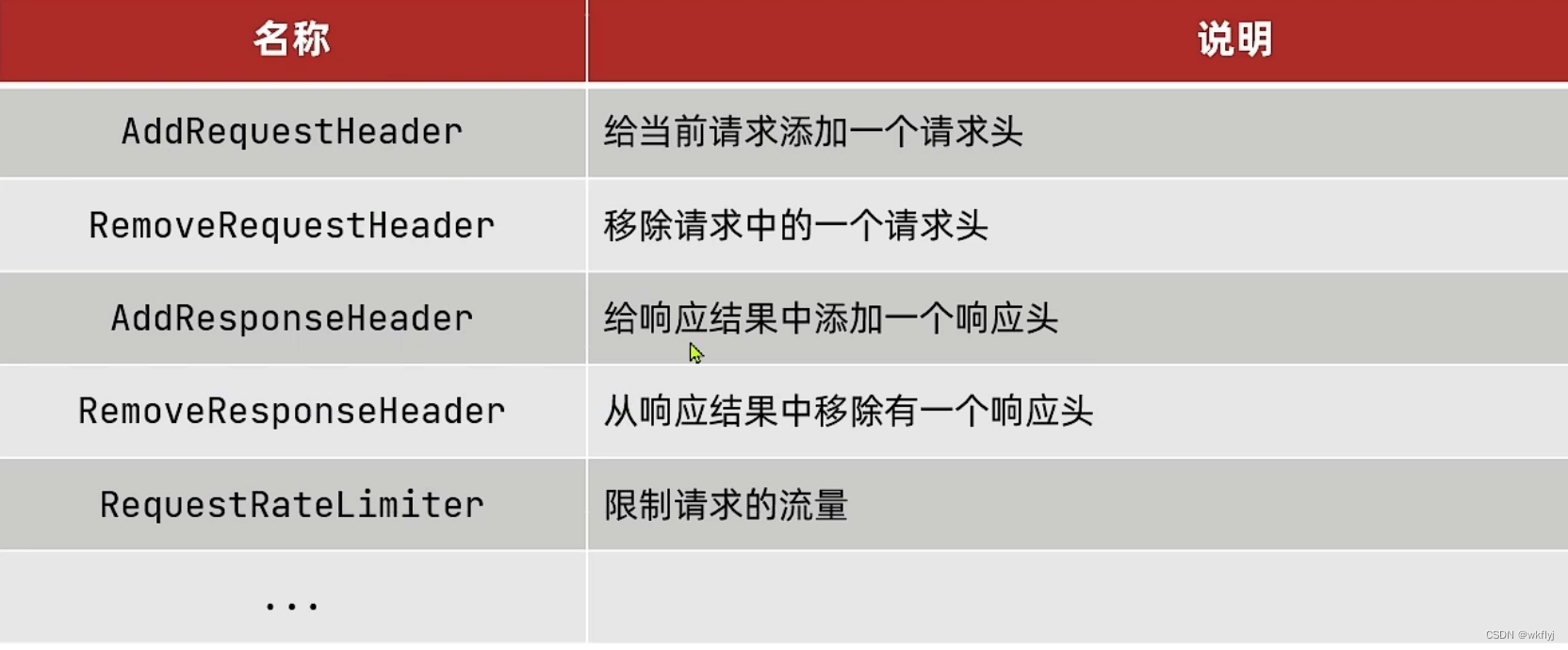
(1)给所有进入userservice的请求添加一个请求头:Truth=itcast is freaking awesome!
实现方式:在gateway中修改application.yml文件,给userservice的路由添加过滤器:

(2)如果要对所有的路由都生效,则可以将过滤器工厂写到default下(默认过滤器)。格式如下:

总结:
问1:过滤器的作用是什么?
答1:①对路由的请求或响应做加工处理,比如添加请求头
②配置在路由下的过滤器只对当前路由的请求生效
问2:defaultFilters的作用是什么?
答2:对所有路由都生效的过滤器
5.全局过滤器 GlobalFilter
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的。而GlobalFilter的逻辑需要自己写代码实现。定义方式是实现GlobalFilter接口。

例如:需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
参数中是否有authorization, authorization参数值是否为admin
如果同时满足则放行,否则拦截

总结:
问1:全局过滤器的作用是什么?
答1:对所有路由都生效的过滤器,并且可以自定义处理逻辑
问1:实现全局过滤器的步骤?
答2:①实现GlobalFilter接口
②添加@Order注解或实现Ordered接口③编写处理逻辑
6.过滤器的执行顺序
①每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
②GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
③路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
④当过滤器的order值一样时,会按照defaultFilter >路由过滤器>GlobalFilter的顺序执行。
总结:
问1:路由过滤器、defaultFilter、全局过滤器的执行顺序?
答1:order值越小,优先级越高。
当order值一样时,顺序是defaultFilter最先,然后是局部的路由过滤器,最后是全局过滤器
三.docker
1.初识Docker
Docker如何解决依赖的兼容问题的?
①将应用的Libs(函数库)、Deps(依赖)、配置与应用一起打包
②将每个应用放到一个隔离容器去运行,避免互相干扰

问1:Docker如何解决大型项目依赖关系复杂,不同组件依赖的兼容性问题?
答1:Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像。 Docker应用运行在容器中,使用沙箱机制,相互隔离
问2:Docker如何解决开发、测试、生产环境有差异的问题
答2:Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可以在任意Linux操作系统上运行
Docker和虚拟机的差异:
①docker是一个系统进程;虚拟机是在操作系统中的操作系统
②docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
镜像和容器
镜像(Image) : Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像。
容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器做隔离,对外不可见。
Docker和dockerhub
dockerhub: dockerhub是一个Docker镜像的托管平台。这样的平台称为Docker Registry。
2.docker的架构
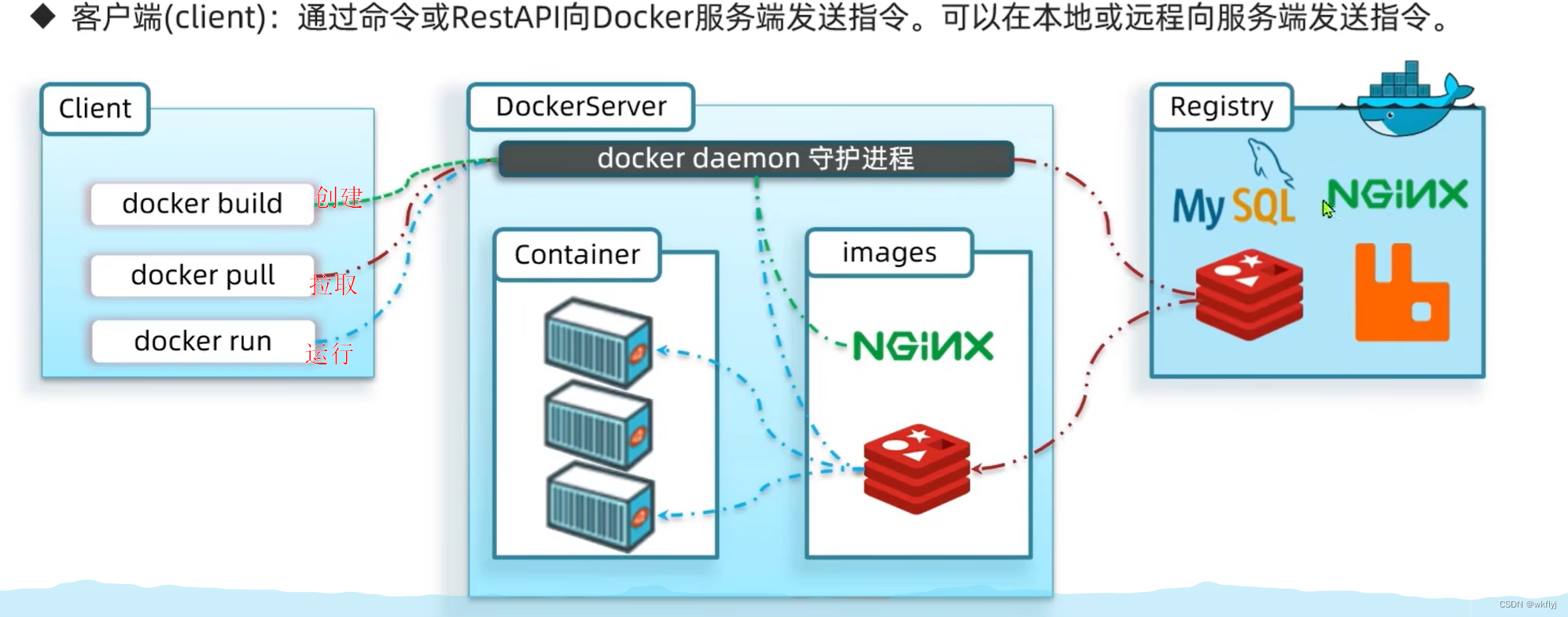
Docker是一个CS架构的程序,由两部分组成:
服务端(server): Docker守护进程,负责处理Docker指令,管理镜像、容器等
客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令。
总结:
镜像:将应用程序及其依赖、环境、配置打包在一起
容器:镜像运行起来就是容器,一个镜像可以运行多个容器
Docker结构:
服务端:接收命令或远程请求,操作镜像或容器中,o
客户端:发送命令或者请求到Docker服务端
dockerhub:
一个镜像托管的服务器,类似的还有阿里云镜像服务,统称为DockerRegistry
3.Docker的基本操作
1.镜像相关命令
① 镜像名称一般分两部分组成:[repository]:[tag]
② 在没有指定tag时,默认是latest,代表最新版本的镜像

镜像操作命令
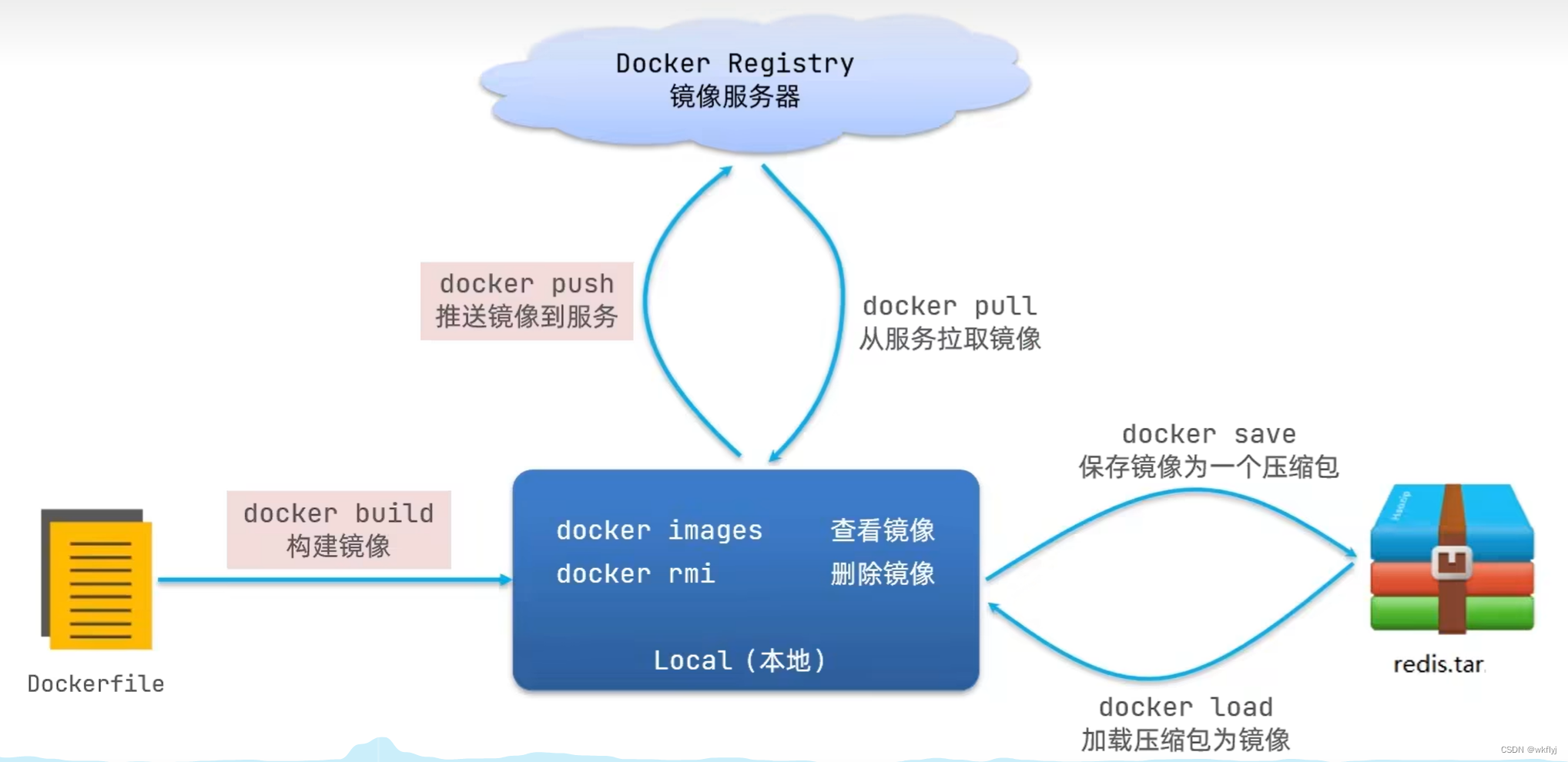
构建镜像: docker build -f Dockerfile -t [repository]:[tag] .
查看镜像: docker images
删除镜像: docker rmi imageName
保存镜像为一个压缩包: docker save -o [repository].tar [repository]:[tag]
加载压缩包为镜像: docker load -i [repository].tar
拉取镜像:docker pull imageName (如果没有指定版本,为最新版本)
推送服务:docker push imageName (如果没有指定版本,为最新版本)
2.容器的相关命令
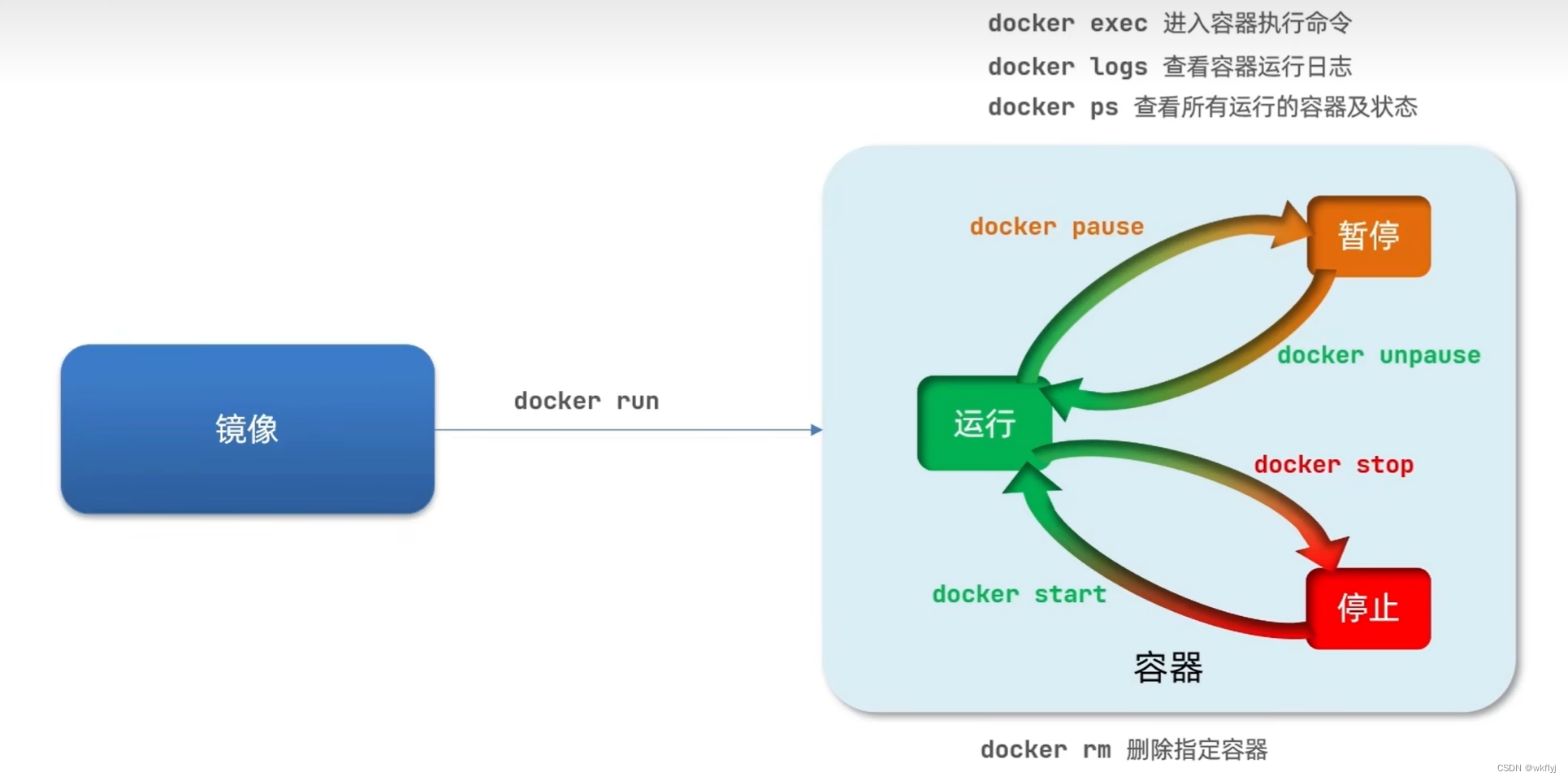
容器运行:docker run
运行到暂停: docker pause
暂停到运行: docker unpause
运行到停止: docker stop
停止到运行: docker start
查看所有运行的容器及状态: docker ps
查看容器运行日志:docker logs
进入容器执行命令:docker exec
删除指定容器: docker rm
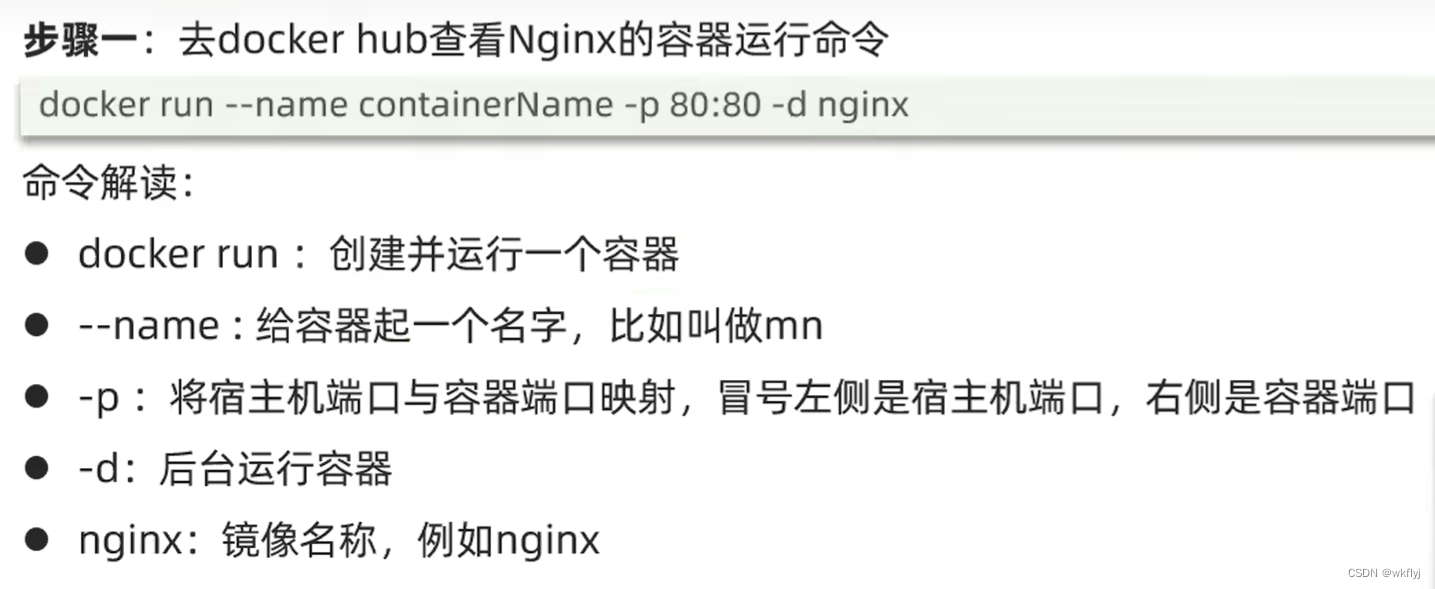
总结:
docker run命令的常见参数有哪些?
--name:指定容器名称
-p:指定端口映射. -d:让容器后台运行
查看容器日志的命令:
- docker logs
添加-f参数可以持续查看日志
查看容器状态:docker ps
案例:进入Nginx容器,修改HTML文件内容,添加“传智教育欢迎您”

总结:
查看容器状态:
docker ps
添加-a参数查看所有状态的容器
删除容器:
docker rm
不能删除运行中的容器,除非添加–-f参数
进入容器:
命令是docker exec -it [容器名][要执行的命令]
exec命令可以进入容器修改文件,但是在容器内修改文件是不推荐的
3.数据卷
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录。
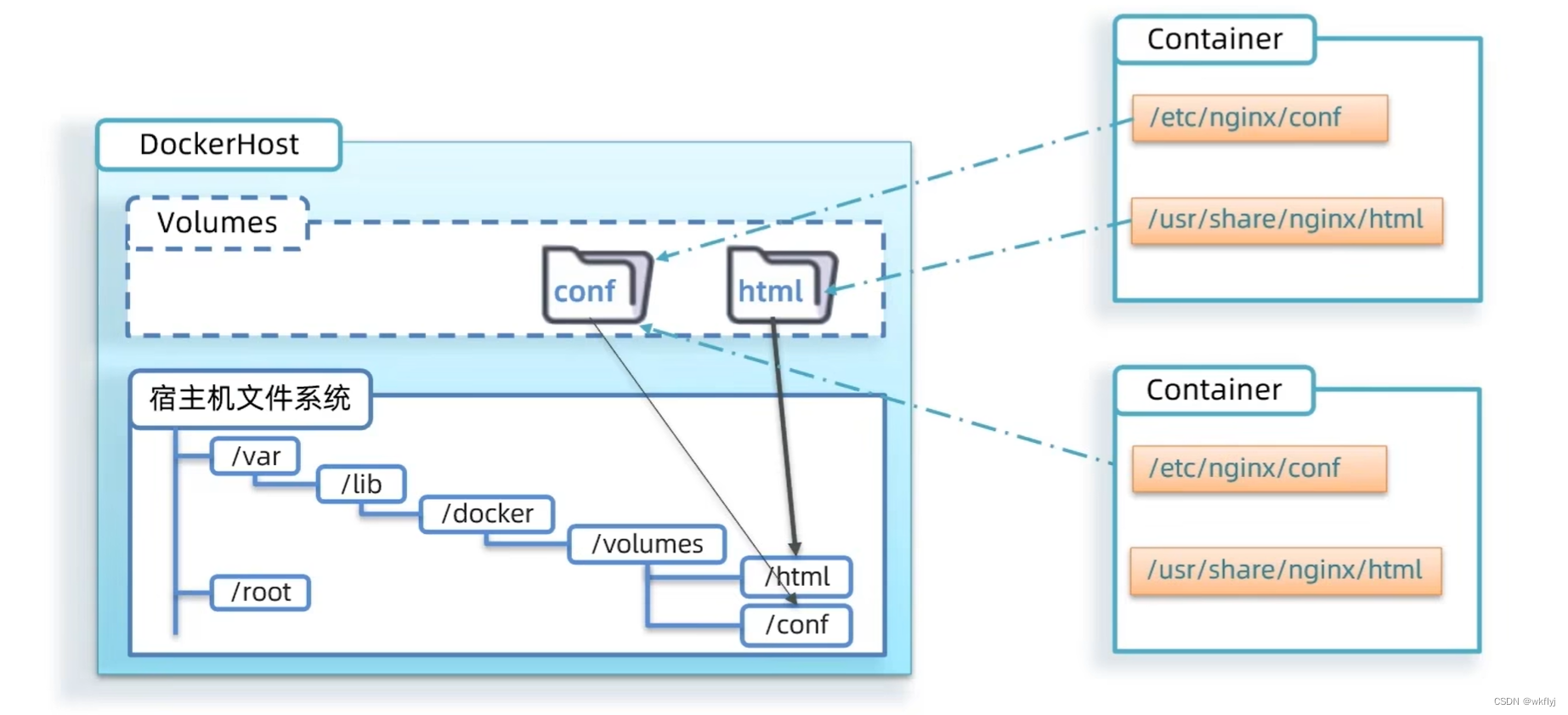
数据卷的作用是为了方便对容器中的文件进行修改等操作,宿主机文件系统中某个目录下有多少文件,对应的数据卷就有多少个文件,等容器运行起来,这些数据卷文件会根据对应的需求挂载到相应的容器中,进行关联。宿主中文件若发生修改,容器中对应的文件也会修改。相反,若容器中的文件发生改变,宿主中文件也跟着改变。若将容器删除,这些数据卷依旧还在,等下个容器运行还能复用。数据卷可以共享,只要挂载到不同的容器中实现共享
数据卷操作的基本语法如下:
docker volume [COMMAND]
docker volume命令是数据卷操作,根据命令后跟随的command来确定下一步的操作:
create : 创建一个volume
inspect : 显示一个或多个volume的信息
ls : 列出所有的volume
prune : 删除未使用的volume
rm : 删除一个或多个指定的volume
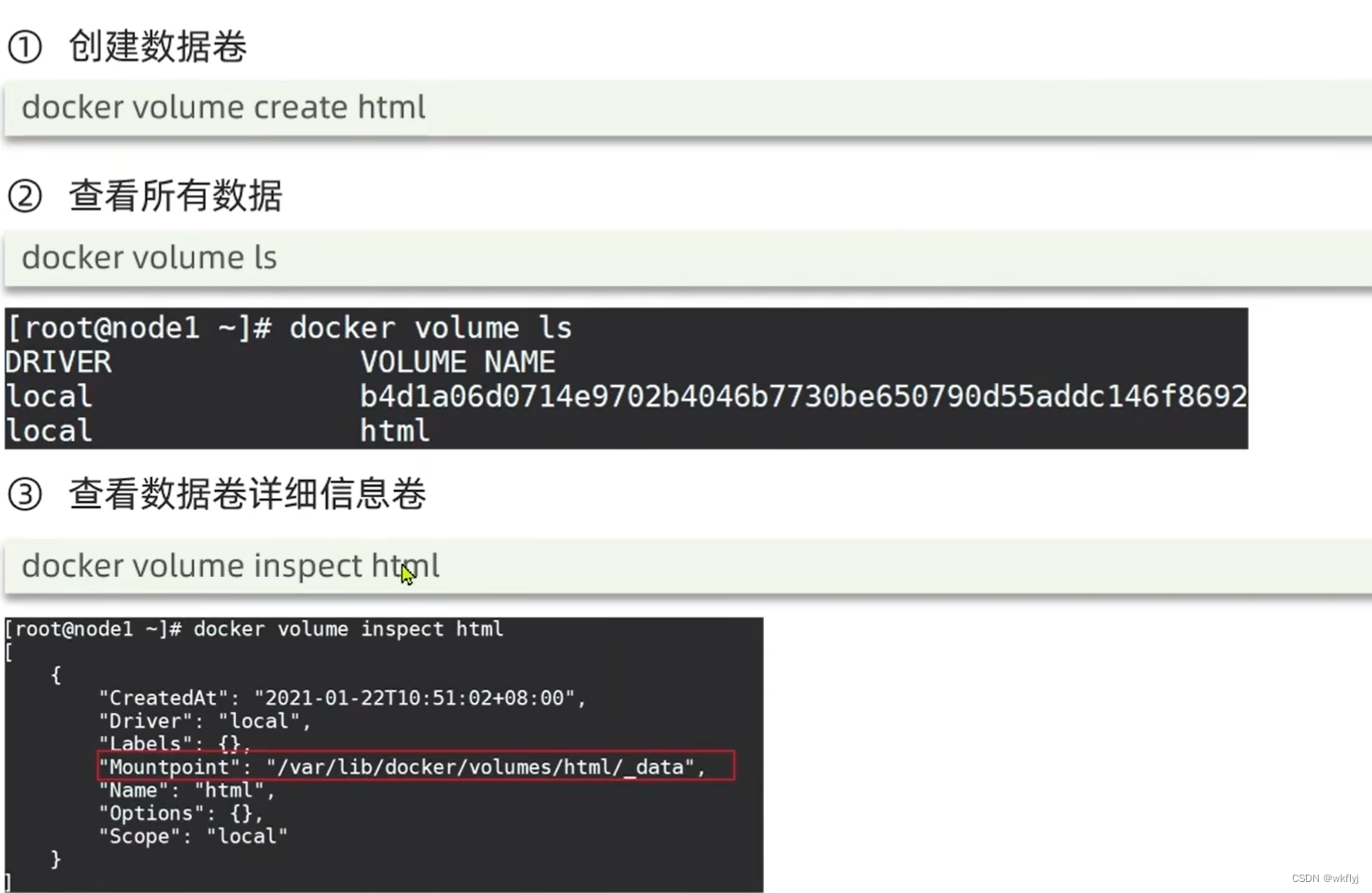
案例:创建一个数据卷,并查看数据卷在宿主机的目录位置
总结:
数据卷的作用:
将容器与数据分离,解耦合,方便操作容器内数据,保证数据安全
数据卷操作:
docker volume create 创建数据卷
docker volume ls 查看所有数据
docker volume inspect 查看数据卷的详情信息
docker volume rm 删除数据卷
docker volume prune 删除未使用的数据卷
案例:创建一个Nginx容器,修改容器内的html目录内的index.html内容
需求说明:上个案例中,我们进入Nginx容器内部,已经知道Nginx的html目录所在位置
/usr/share/Nginx/html,我们需要把这个目录挂载到html这个数据卷上,方便操作其中的内容。提示:运行容器时使用-v参数挂载数据卷
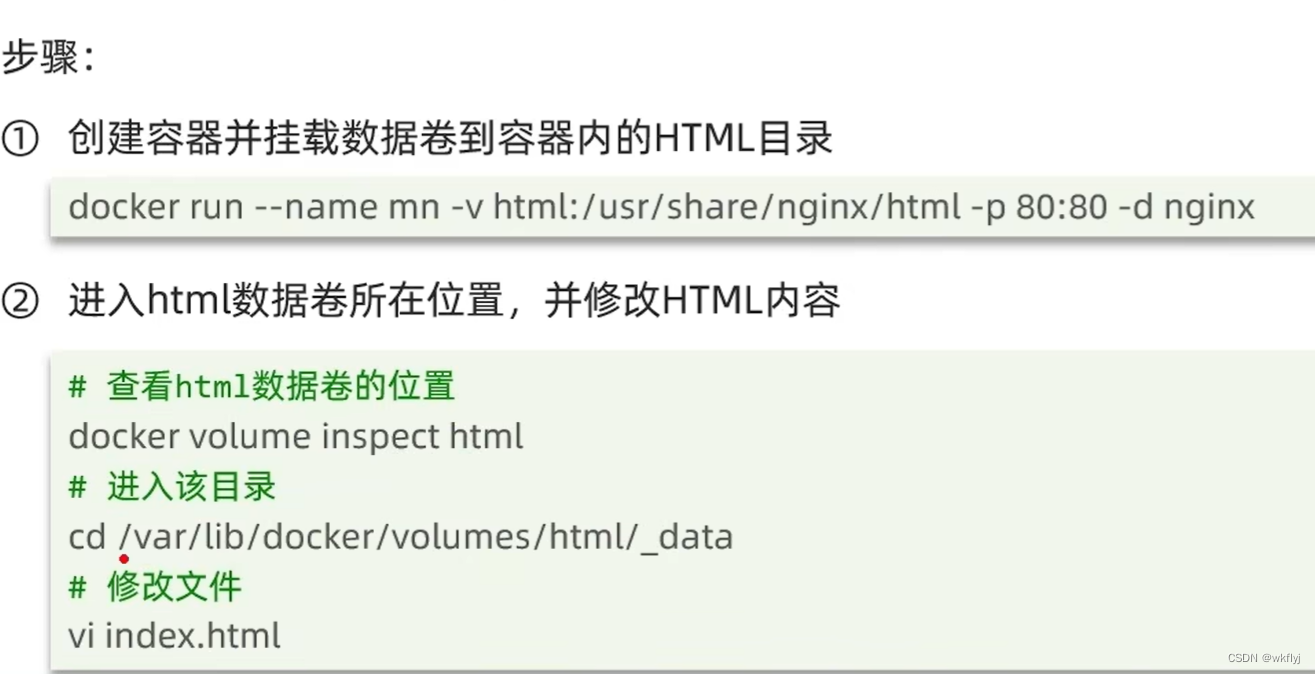
总结:
数据卷挂载方式:
-v volumeName: /targetContainerPath
如果容器运行时volume不存在,会自动被创建出来
案例:创建并运行一个MysqL容器,将宿主机目录直接挂载到容器
提示:目录挂载与数据卷挂载的语法是类似的:
-v[宿主机目录]:[容器内目录]
-v[宿主机文件]:[容器内文件]
实现思路如下︰
1.在将课前资料中的MysqL.tar文件上传到虚拟机,通过load命令加载为镜像
2.创建目录/tmp/myql/data
3.创建目录/tmp/myql/conf,将课前资料提供的hmy.cnf文件上传到/tmp/myql/conf
4.去dockerhub查阅资料,创建并运行MysqL容器,
要求:
①挂载/tmp/myql/data到MysqL容器内数据存储目录
②挂载/tmp/myql/conf/hmy.cnf到MysqL容器的配置文件
③设置MysqL密码
总结:
docker run的命令中通过-v参数挂载文件或目录到容器中:
-v volume名称:容器内目录
-v宿主机文件:容器内文件
-v宿主机目录:容器内目录
数据卷挂载与目录直接挂载的
①数据卷挂载耦合度低,由docker来管理目录,但是目录较深,不好找
②目录挂载耦合度高,需要我们自己管理目录,不过目录容易寻找查看
4. 自定义镜像
1.镜像的结构
镜像是将应用程序及其需要的系统函数库、环境、配置、依赖打包而成。
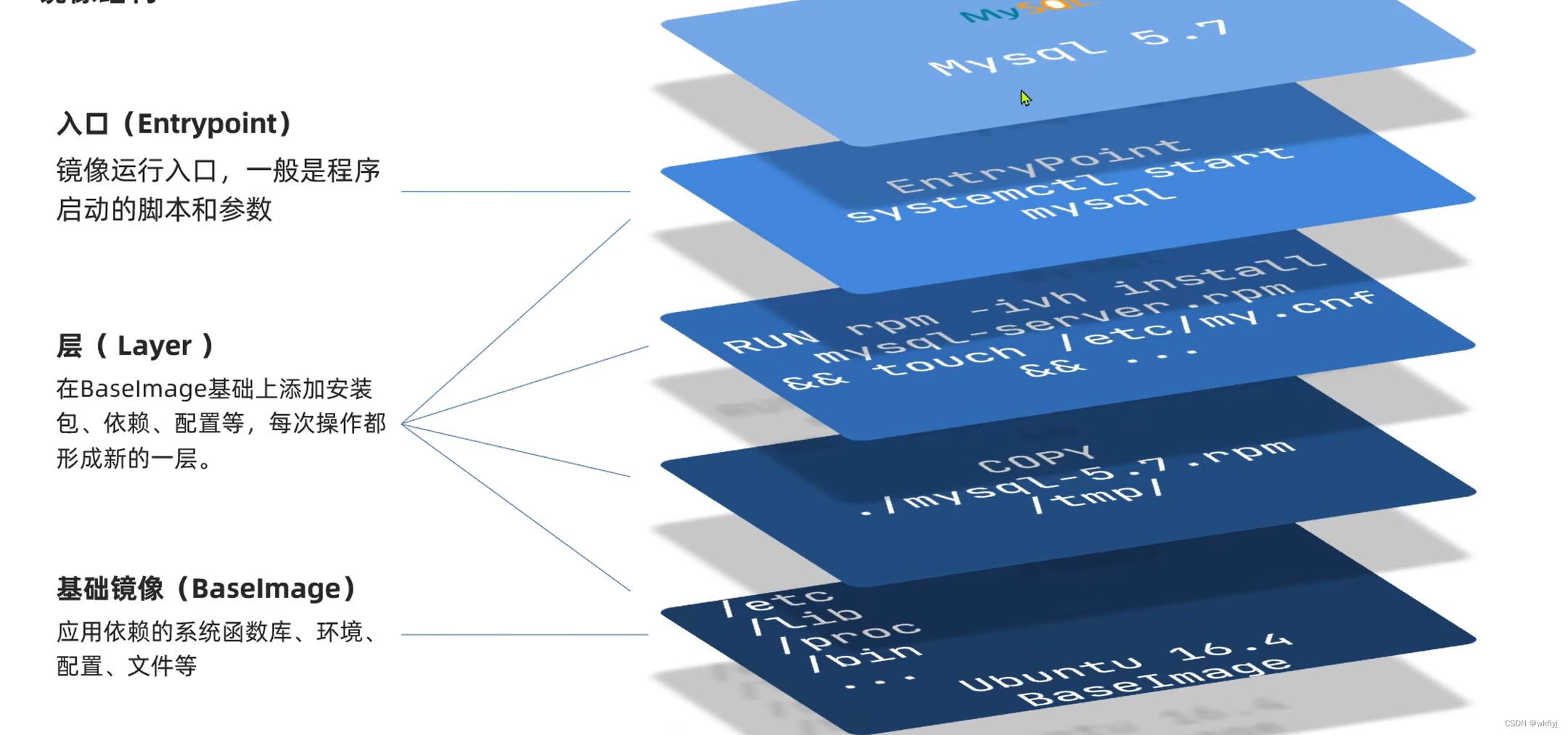
总结:
镜像是分层结构,每一层称为一个Layer
Baselmage层:包含基本的系统函数库、环境变量、文件系统
Entrypoint: 入口,是镜像中应用启动的命令
其它:在Baselmage基础上添加依赖、安装程序、完成整个应用的安装和配置
补:分层的作用就是在镜像更新时,不会将所有的层级删除,会留下可用的层级,,在其基础之上添加更新镜像所用的层数,提高层级可复用性,节约时间
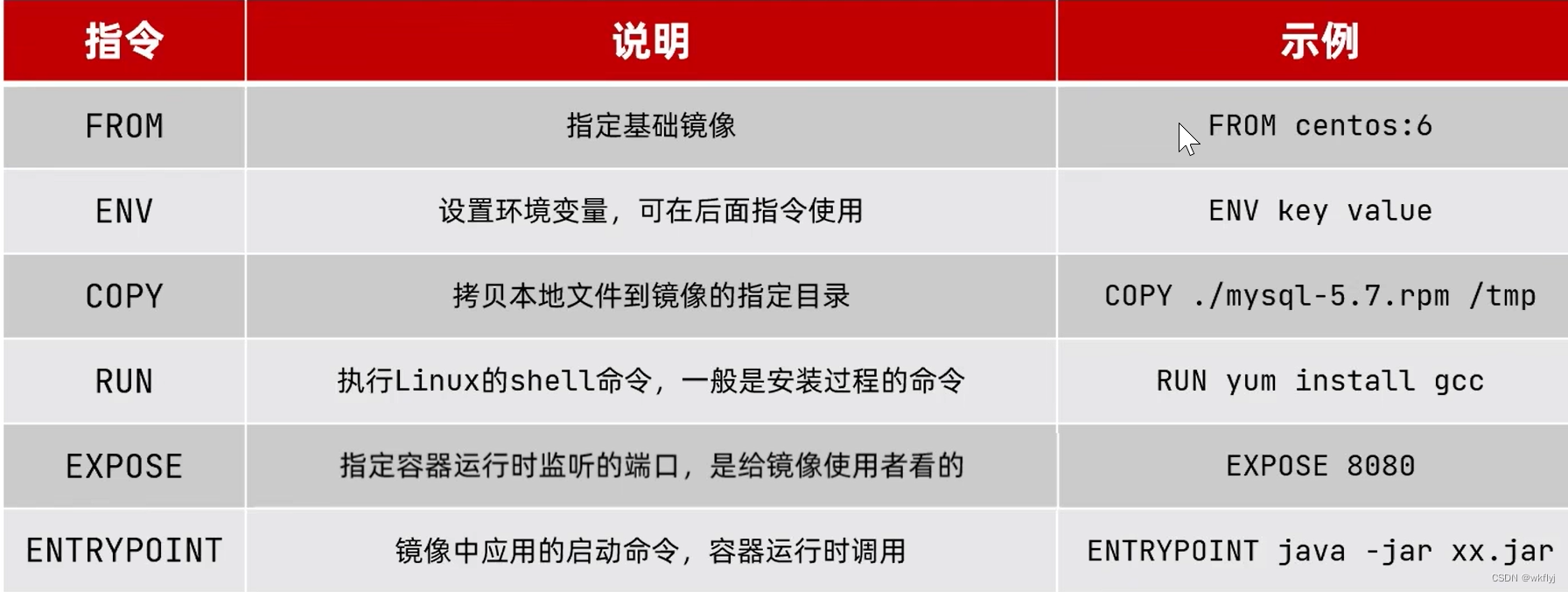
2.什么是Dockerfile
Dockerfile就是一个文本文件,其中包含一个个的指令(Instruction),用指令来说明要执行什么操作来构建镜像。每一个指令都会形成一层Layer。
案例:基于Ubuntu镜像构建一个新镜像,运行一个java项目
步骤1:新建一个空文件夹docker-demo
步骤2:拷贝课前资料中的docker-demo.jar文件到docker-demo这个目录
步骤3:拷贝课前资料中的jdk8.tar.gz文件到docker-demo这个目录
步骤4∶拷贝课前资料提供的Dockerfile到docker-demo这个目录
步骤5:进入docker-demo
步骤6:运行命令: dockerbuild -t javaweb: 1.0 .
Dockerfile 文件内容:
#指定基础镜像
FROM· ubuntu : 16.04
#配置环境变量,JDK的安装目录
ENV JAVA_DIR=/usr/ local
#拷贝jdk和java项目的包
copY ./jdk8.tar.gz $JAVA_DIR/
copY ./docker-demo.jar /tmp/app.jar
#安装JDK
RUN cd $JAVA_DIR \
&tar -xf ./jdk8.tar.gz l&&mv ./jdk1.8.0_144 ./java8
#配置环境变量
ENV JAVA_HOME=$JAVA_DIR/java8ENV PATH=$PATH:$JAVA_HOME/bin
#暴露端口
EXPOSE 8090
#入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar案例:基于java:8-alpine镜像,将一个Java项目构建为镜像
实现思路如下:
①新建一个空的目录,然后在目录中新建一个文件,命名为Dockerfile
②拷贝课前资料提供的docker-demo.jar到这个目录中
③编写Dockerfile文件:
a)基于java:8-alpine作为基础镜像
b)将app.jar拷贝到镜像中
c)暴露端口
d)编写入口ENTRYPOINT
④使用docker build命令构建镜像
⑤使用docker run创建容器并运行
Dockerfile 文件内容:
#指定基础镜像
FROM java:8-alpine
copY ./ docker-demo.jar /tmp/app.jar
#暴露端口
EXPOSE 8090
#入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar
总结:
Dockerfile的本质是一个文件,通过指令描述镜像的构建过程
Dockerfile的第一行必须是FROM,从一个基础镜像来构建
基础镜像可以是基本操作系统,如Ubuntu。也可以是其他人制作好的镜像,例如: java:8-alpine
3.DockerCompose
1.什么是DockerCompose
Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!
Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。
version: "3.8"
services:
MysqL:
image: MysqL:5.7.25
environment:
MysqL_ROOT_PASSWORD:123
volumes:
- /tmp/MysqL/data: /var/lib/MysqL
- /tmp/MysqL/conf/ hmy.cnf:/etc/MysqL/conf.d /hmy.cnf
web:
build: .
ports:
- 8090:8090总结:
问1:DockerCompose有什么作用?
答1:帮助我们快速部署分布式应用,无需一个个微服务去构建镜像和部署。
2.DockerCompose 部署微服务

version: "3.2"
services:
nacos:
image: nacos/nacos-server
environment:
MODE: standalone
ports :
- "8848:8848"
MysqL:
image: MysqL:5.7.25
environment:
MysqL_ROOT_PASSWORD:123
volumes :
-"$PWD/MysqL/data : /var/lib/MysqL"
- "$PWD/MysqL/conf : /etc/MysqL/conf.d /"
userservice:
build: ./user-service #会读取user-service下的Dockerfile文件,创建镜像
orderservice:
build: ./order-service #会读取order-service下的Dockerfile文件,创建镜像
gateway:
build: ./gateway #会读取gateway下的Dockerfile文件,创建镜像
ports:
- "10010:10010"
4.Docker镜像仓库
1.常见镜像仓库服务
镜像仓库(Docker Registry )有公共的和私有的两种形式:
①公共仓库:例如Docker官方的Docker Hub,国内也有一些云服务商提供类似于Docker Hub的公开服务,比如网易云镜像服务、DaoCloud镜像服务、阿里云镜像服务等。
②除了使用公开仓库外,用户还可以在本地搭建私有Docker Registry。企业自己的镜像最好是采用私有DockerRegistry来实现。
原文地址:https://www.jb51.cc/wenti/3281852.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

