

一.前言
我在上一篇文章中讲解了顺序表的基本功能和操作实现,有兴趣的各位可以点这个链接看看:数据结构——线性表之顺序表的基本操作讲解_
今天来讲一讲线性表的另一大功能表——链表。
其实顺序表有很多缺陷:
1.在实现头部的插入与删除时,都需要数据从后往前、从前往后的挪动数据,若是有n个元素,每次删除或插入都需要挪动一次,时间复杂度为O(1),若是删除或插入n次,就要挪动n次,所以时间复制度为n*O(1)=O(n),有极大的时间浪费。
2.增容需要申请新空间,拷贝数据、释放旧空间,会有所消耗。
3.增容一般是2倍增长,势必有空间浪费,例如容量为100的顺序表,增容到200,但在增容后我只插入了5个数据,浪费了95个空间。
基于此,链表会进行相应的改进。
目录
三.单链表的实现(Single List Node)——SLN
二.链表
1.链表的概念:
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。

链表链表,说白了各个节点之间是用链子关联起来的,就像火车一样,各个车厢就是链表中的节点,每个车厢之间的铁钩将其关联起来组成一个完整的火车。
每一个结点都有两部分组成:数据域和指针区域。

2.链表的结构概念:

链表的核心结构就是一个指针,指针中存的是第一个节点的地址,通过地址就可以找到节点,然后第一个节点的指针域会存取下一个节点的地址,依此类推,直到最后一个节点的指针域存NULL便结束了。
刚才在定义中说过链表在逻辑结构上连续,但在物理结构上不连续。如何理解?我来举个例子大家就明白了:
物理结构,就是在计算机内存中的存储关系。比如数组,在计算机上的存储是一段连续的内存块。链式存储,是在计算机中不连续的内存使用间接寻找方式连接的,是物理内存的表现,如下图:

而在我们的思想逻辑上,链表的每个节点都互相连着绳索,通过绳索就能找到对方(无视距离),所以说逻辑上连续,物理上不一定连续。
链表申请空间是在堆区上申请的动态内存,堆区内存是随机分配的,哪里空闲就就为其开辟空间,所以申请出来的几块空间地址有可能连续,有可能不连续。
3.链表的分类:
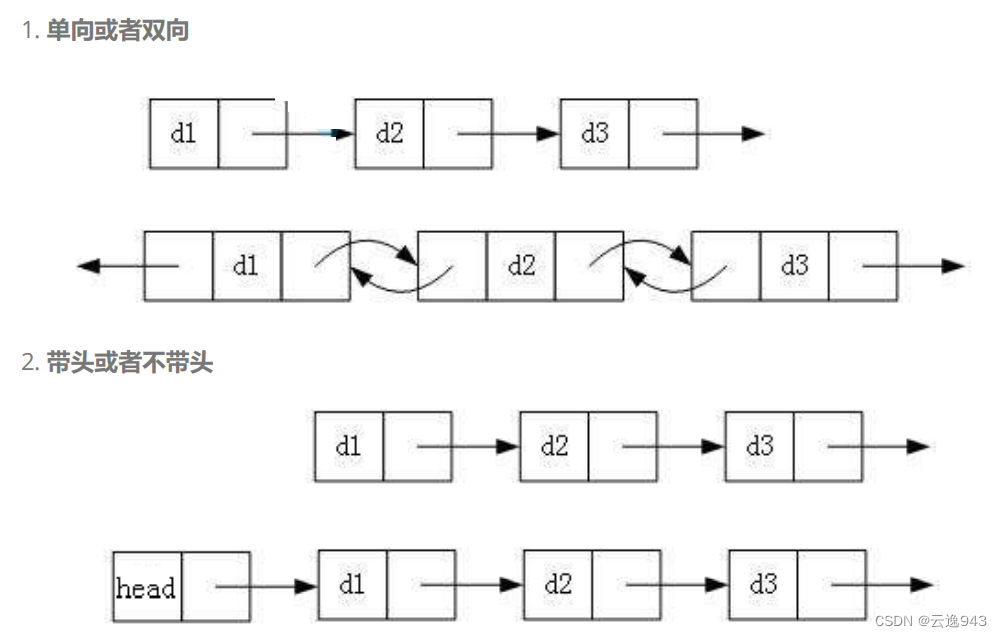


虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:

1. 无头单向非循环链表(简称单链表):结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结 构的子结构,如哈希桶、图的邻接表等等。
2. 带头双向循环链表(简称双向链表):结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都 是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带 来很多优势,实现反而简单了,后面我们代码实现了就知道了。
三.单链表的实现(Single List Node)——SLN
1.创建结构体类型
通过之前的讲解,链表有两部分数据域和指针域,所以使用结构体给其创建两个成员变量
typedef int SLTDataType;//重定义int类型为链表结构类型
typedef struct SListNode {
SLTDataType data; //数据域
struct SListNode* next;//指针域
}SLNode;typedef struct SListNode重定义为SLNode,因为struct SListNode名字太长,所以简化一下名字,但语句生效也是在定义之后才会生效,以下这种情况是错误的:
typedef struct SListNode {
SLTDataType data; //数据域
SLNode* next;//指针域
}SLNode;单链表也分有节点的链表和无节点的链表,所以写某些函数时要分情况而论!

2.打印单链表的函数
//打印链表
void SListPrint(SLNode* phead) {
SLNode* cur = phead;
while (cur != NULL) { //遍历链表
printf("%d->", cur->data);//打印结点
cur = cur->next;//跳转到下一个
}
printf("NULL\n");//
}打印链表实现原理:函数会创建一个临时的结体指针变量,保存phead指向的节点地址,创建临时指针变量的作用是为了不轻易改动phead指针变量,通过cur去遍历所有节点地址实现打印数据,直到NULL结束。
注:cur=cur->next 该语句是遍历链表的核心语句!!!

3.单链表申请动态开辟结点函数:
//创建结点函数(动态开辟)
SLTDataType* BuySLNode(SLTDataType x) {
SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));//动态开辟
if (newnode == NULL) {
perror("malloc fail\n");
return -1;//开辟失败则退出且报错
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
结点的开辟就是啥时候用啥时候在堆区开辟就行,根据开辟下的空间可以在数据域或指针域进行相应的赋值,若不知道地址处赋什么值好,就先置为空即可。
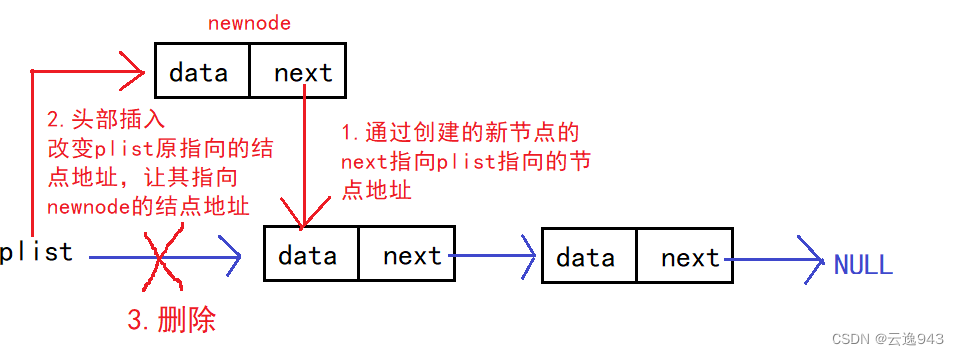
4.单链表头部插入函数:
图解:
//
void SListPushFront(SLNode** pphead, SLTDataType x) {
assert(pphead);
SLNode* newnode = BuySLNode(x);
newnode->next = *pphead;
*pphead = newnode;
}该函数用到了二级结构体指针,因为主函数中的实参也是结构体指针,若是实参传一级指针,形参再用一级指针接收 ,那就成了传值调用,形参是实参的一份临时拷贝,形参的改变不会影响实参,所以并不能改变链表,也就无法执行插入操作。
所以需要用到传址调用,实参传指针地址,形参用二级指针接收即可影响链表。
测试功能:


5.单链表尾部插入结点函数:
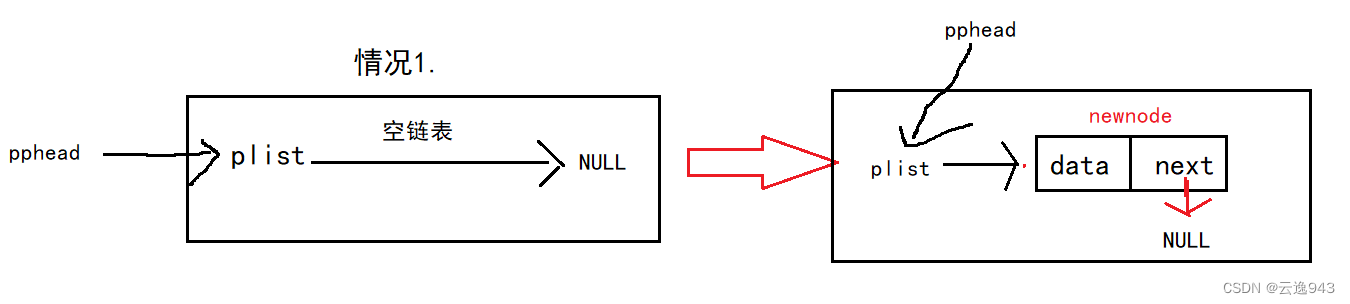
这次就需要分情况而论了:
情况一.当链表为空时,需要二级指针去影响实参改变plist的指针;
情况二.当链表中有结点时,只需要一级指针,不用改变实参plist的指向。

函数代码:
void SListPushBack(SLNode** pphead, SLTDataType x) {
assert(pphead);
SLNode* newnode = BuySLNode(x);
//情况1.
if (*pphead == NULL) {
*pphead = newnode;
}
//情况2.
else {
SLNode* tail = *pphead;
while (tail->next != NULL) {
tail = tail->next;
}
tail->next = newnode;
}
}函数实现原理:
注:plist为实参,实参传递是&plist,形参是用**pphead二级指针接收,*pphead(解引用)后等价于plist指针!!!
1.当前链表为空链表时,plist指向NULL,所以需要改变plist的指向,直接把新建的结点newnode地址交给plist即可。
2.当前链表有一个或多个结点时,创建一份临时指针变量,将plist指向的结点地址拷贝一个交给tail,然后遍历tail,让tail指针遍历一直向后走,直到tail指向NULL停止,可以开始尾插了,于是将新建的newcode节点地址交给tail的指针区域即可,这种情况不需要改变plist指向,所以没有用到pphead二级指针。
测试:

6.单链表头部删除结点函数:
图解:实现原理

函数代码:
//头删
void SListPopFront(SLNode** pphead) {
assert(pphead);
//温柔检查
if (*pphead == NULL) {
return;
}
//暴力检查
//assert(*pphead != NULL);
SLNode* del = *pphead; //创建一份临时指针变量存取plist指向的结点地址
*pphead = (*pphead)->next;//plist指向的结点的指针域指向下一个结点的地址,
//也就是plist指向的下下一个结点地址,由plist直接指向了
free(del); //原plist指向的第一个结点被释放掉了,直接指向了第二个结点地址
del = NULL;
}注:二级指针需要断言一下其是否为空。因为pphead存的是plist的指针地址,但pphead本身的地址不可为空!!!
测试:
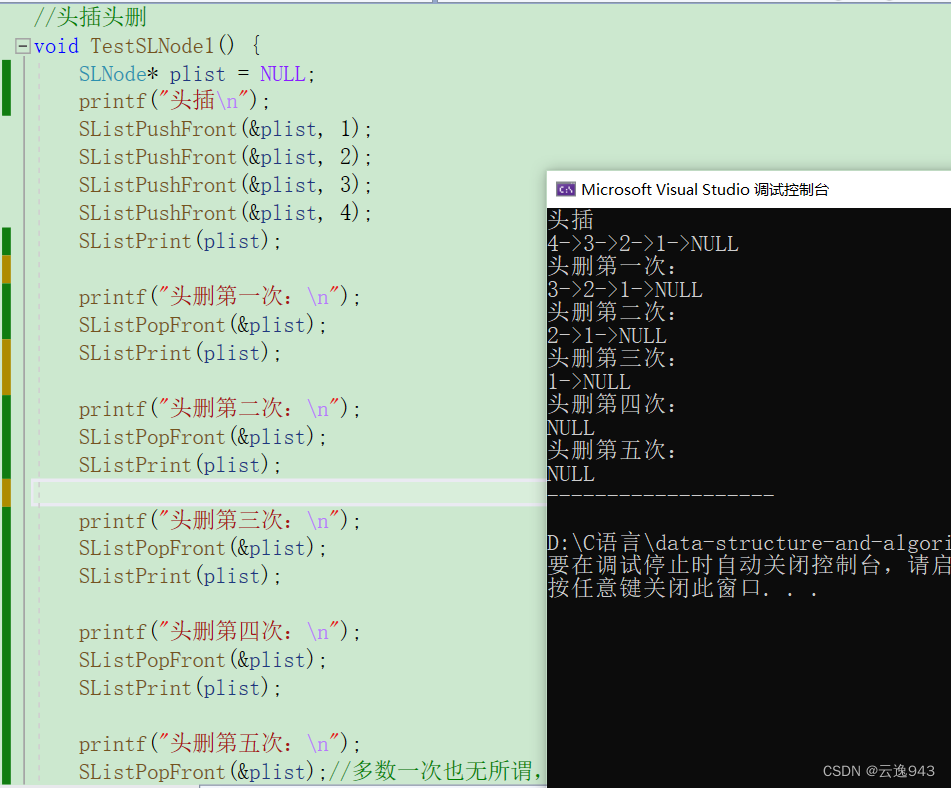
注:头删第四次和头删第五次的结果是一样的,原因是有检查判断:
:

若没有检查,系统会删除NULL,会崩溃!!!
注:检查可以二选一!
7.单链表尾部删除结点函数:
图解:

尾部删除也要分情况:
情况一.当链表中只有一个节点时,直接删即可,所以需要用到二级指针去改变plist指向。
情况二.当链表中有多个结点时,需要两个结点两个结点的跳跃寻找NULL,这次不需要二级指针,只用临时指针变量去遍历寻找NULL即可。找到NULL后,改变tail指向的下一个节点的指针域为NULL即可。
函数代码:
//尾删
void SListPopBack(SLNode** pphead) {
assert(pphead);
//温柔检查
if (*pphead == NULL) {
return;
}
//暴力检查
//assert(*pphead != NULL);
//情况一.当链表中只有一个结点时,直接删即可
if ((*pphead)->next == NULL) {
free(*pphead);
*pphead = NULL;
}
//情况二.当链表中有多个结点时,需要两个结点两个结点的跳跃寻找NULL
else {
SLNode* tail = *pphead;
while (tail->next->next != NULL) {
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}测试:
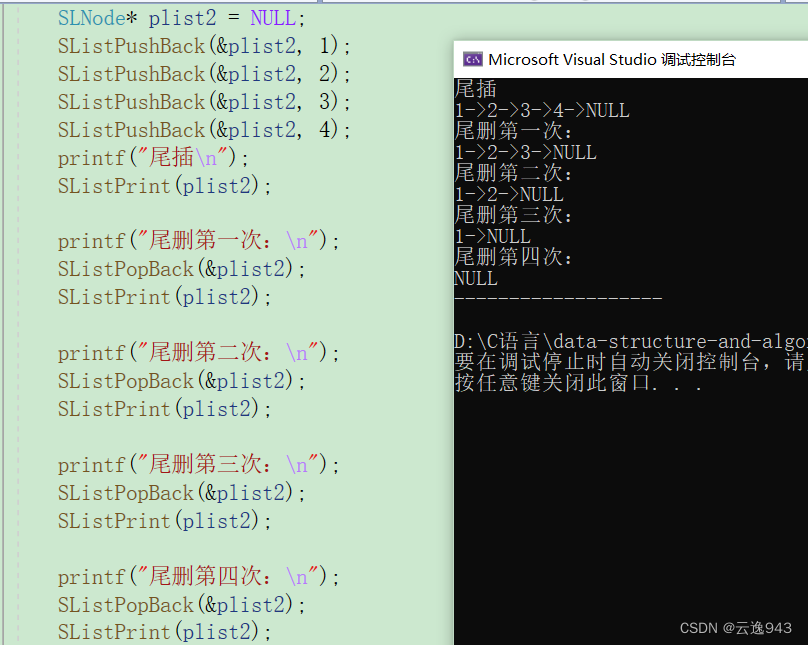
8. 单链表的查找函数
SLNode* SListFind(SLNode* phead, SLTDataType x) {
SLNode* cur = phead;
while (cur != NULL) {
if (cur->data == x) {
return cur;//找到了,返回该节点的地址
}
cur = cur->next;//继续向后找
}
return NULL;//找不到
}查找函数就十分简单了,只需要一个临时指针变量去指向第一个节点地址,通过循环遍历每个节点去找出相同的数据域,找到了就返回该节点的地址,找不到就返回空。
test.c中:
测试:
void TestSLNode3() {
//尾插
SLNode* plist3 = NULL;
SListPushBack(&plist3, 9);
SListPushBack(&plist3, 8);
SListPushBack(&plist3, 7);
SListPushBack(&plist3, 6);
SListPrint(plist3);
SLNode* ret=SListFind(plist3, 8);
if (ret!=NULL)
printf("找到了\n");
else
printf("没找到\n");
}
int main(){
TestSLNode3();
return 0;
}

其实查找函数也可以做修改功能:
void TestSLNode3() {
//尾插
SLNode* plist3 = NULL;
SListPushBack(&plist3, 9);
SListPushBack(&plist3, 8);
SListPushBack(&plist3, 7);
SListPushBack(&plist3, 6);
SListPrint(plist3);
SLNode* ret=SListFind(plist3, 8);
if (ret) {
printf("找到了\n");
//查找函数可以做修改功能,能修改当前查找结点的值
ret->data = 666;//将值为8的结点,改为值为666的结点
printf("修改成功\n");
SListPrint(plist3);
}
else
printf("没找到\n");
printf("-------------------\n");
}结果:

9.单链表的销毁释放功能:
图解:


函数代码:
//销毁
void SListDestory(SLNode** pphead) {
assert(pphead);
SLNode* cur = *pphead;
while (cur!= NULL) { //遍历链表
SLNode* next = cur->next;//创建临时指针变量,pphead不可轻易更改
free(cur);
cur = next;
}//从前到后一个一个释放空间
*pphead = NULL;//将起始结构体指针变量plist置为空就行
}10.单链表在某个位置的插入函数:
这个功能可以分情况:
链表在pos位置之前的插入节点;
链表在pos位置之后的插入节点;
而单链表不适合在pos位置之前插入节点,需要遍历链表找到pos位置的前一个节点,步骤很是复杂,不建议使用pos前添加节点!
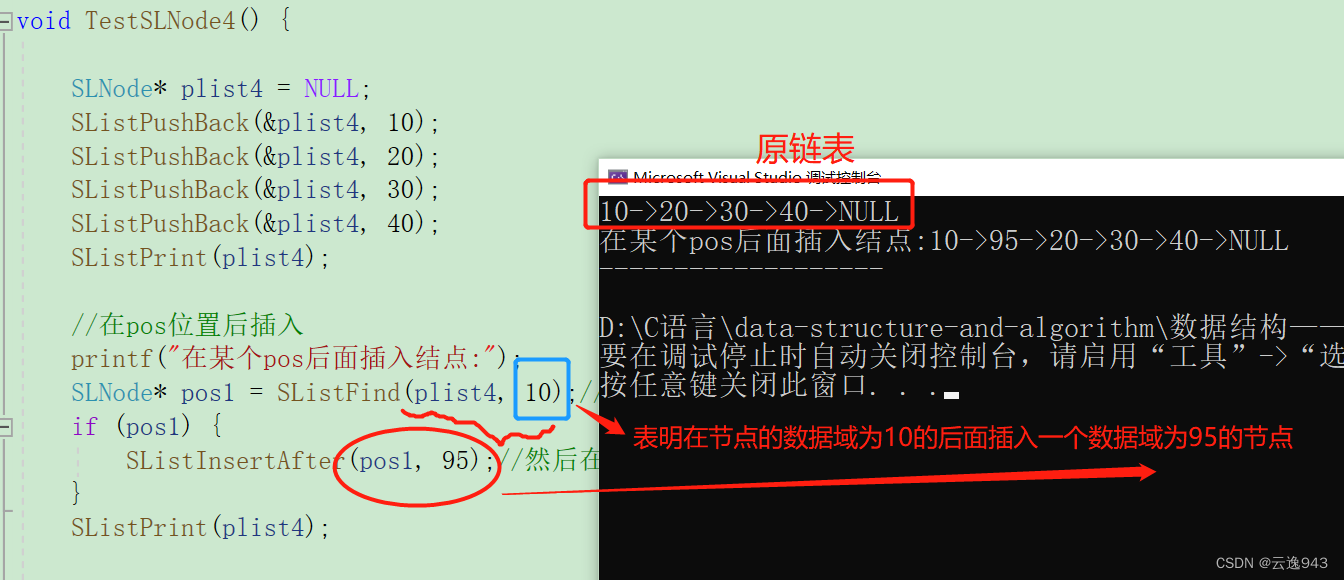
链表在pos位置之后的插入节点:

代码:
//链表在pos位置之后的插入
void SListInsertAfter( SLNode* pos, SLTDataType x) {
assert(pos);
SLNode* newnode = BuySLNode(x);
newnode->next = pos->next;//新节点的next指针指向pos位置的后一个结点
pos->next = newnode;//pos位置的next指向新节点
}pos是一个结构体指针,表示链表的节点位置。这个函数要配合查找函数进行,先查找你要插入的节点位置,即为pos位置,然后就可以插入节点了。
测试:
11.单链表在某个位置删除节点的函数:
这个功能可以分情况:
链表在pos位置之前的删除节点;
链表在pos位置之后的删除节点;
单链表在pos位置上删除节点的函数:
图解:

函数代码:
void SListerase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(*pphead); //链表不能为空
assert(pos); //给的pos位置不能为空
//pos位置为第一个节点,相当于头删
if (pos == *pphead)
{
SListPopFront(pphead);
}
//pos位置为中间节点
else
{
SListNode* prev = *pphead;
while (prev->next != pos) //找到pos位置的前一个节点
{
prev = prev->next;
}
prev->next = pos->next; //pos位置的前一个节点指向pos位置的后一个节点
free(pos); //释放pos节点
pos = NULL; //置空
}
}
测试:

单链表在pos位置后面删除节点的函数:
图解:

函数代码:
void SListeraseAfter(SLNode* pos) {
assert(pos);
assert(pos->next);
SLNode* cur = pos->next;
pos->next = pos->next->next;
free(cur);
}测试:

原文地址:https://www.jb51.cc/wenti/3283726.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

