

distantly Supervised Named Entity Recognition via Confidence-Based Multi-Class Positive and Unlabeled Learning
目录
前言
面向远程监督数据集中,噪声问题;
面向在给定正例数据集和无标注数据集条件下,数据集label策略。
(一般是在实体词典的基础上,做回标,会造成数据质量较低)
在解决distant_NER,一项工作侧重于设计深度学习架构,以应对具有高误报率的训练数据,以部分减轻有缺陷的远程注释的影响(Shang 等人,2018 年;Liang 等人,2020 年)。另一项工作应用部分条件随机场 (CRF) 为未标记样本分配所有可能的标签并最大化整体概率
PUlearning:二元正和未标记(PU)学习应用于 DS-NER 任务(Peng 等人,2019)。 PU 学习仅使用有限的标记正数据和未标记数据进行分类,因此自然适用于处理远程监督,其中外部知识通常对正样本的覆盖范围有限。在实际应用时,一般会将n个type的实体识别问题,建模为n个二分类任务。
PU learning的基本假设是:未标注数据的分布和整体数据的分布相同。
论文核心
首先,计算每个token被估计为实体的置信度分值。
之后,提出了Conf-mpu风险估计,被用来训练一个多类别分类网络。
- 对于distant labeled training data,我们首先进行token级别的二进制分类来估计token作为实体token的置信度分数([0, 1]中的概率值)
- 然后,我们使用神经网络模型和提出的 Conf-mpu 风险估计器执行 NER 分类,该模型结合了从风险估计的第一步获得的置信度分数。
论文建模
涉及到一些数据公式的推导,概率论部分的数学公式。
conf计算 二分类问题,0表示positive class,1表示negative class。目标是建立决策函数,减少决策的错误。
这一块,作者给出了比较详细的公式推导
标准的二分类监督
是从标准的二分类监督学习中,出发的,
定义的决策函数是:
前半部分是正例的loss,后半部分是neg的loss和,π是比率,每部分占的先验概率。
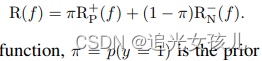
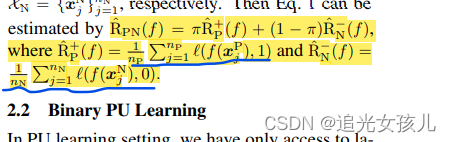
在binary PU learning中

然后,经过推导,得到的最终公式:
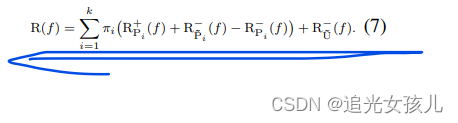
多出的两部分是,是作者考虑到,未标记数据的分布 pU(x) 可能与整体分布 p(x) 不同,这就与最初的PU的假设相违背。在这种情况下,未标记的数据将具有更接近真实负数据分布 pN(x) 的分布,而不是整体分布 p(x)。
因此,将Pu部分的概率分布,分为了正负数据分开考虑的。
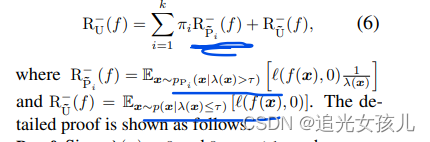
最终的risk estimator,可以表示为(分为pos和neg两部分):
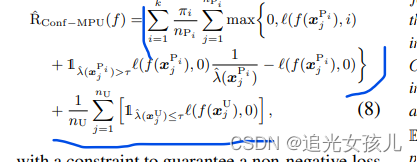
模型的使用
损失函数是:
label是y
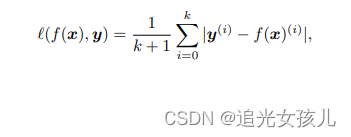
总结
作者补充了一些提高训练性能的方法,比如,例如基于模型预测迭代丰富字典(Peng et al., 2019),或迭代训练师生框架(梁等人,2020)。
在实验中,作者发现,随着实体字典越发丰富,整个模型的准确率和recall是呈现下降的趋势的。给出的解释是,认为,当字典呈现高收敛的时候,PU中的分布假设,即未标注部分的数据服从整体数据分布,并不成立,而是更趋近于negative data部分的数据分布。
这篇的文章的实用性,我觉得是可以的。
需要再次翻阅。
原文地址:https://www.jb51.cc/wenti/3284173.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

