

Flink和Spark性能对比
Benchmark设计
针对一个简单的广告应用。应用涉及广告促销活动业务,每个业务有很多广告数据。
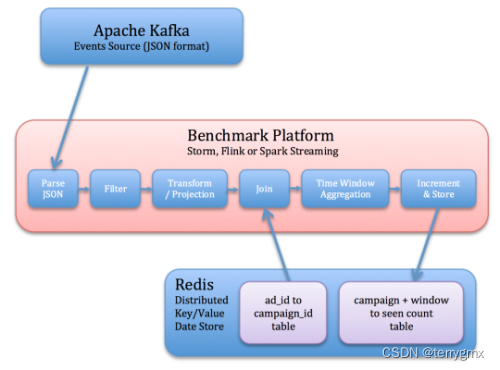
流处理平台需要从kafka读取JSON格式的事件,标识相关事件,按促销业务窗口读取关联事件,并保存到Redis中。
具体操作步骤(和流程图对应):
- 从kafka读取事件数据
- 反序列化Json字符串
- 去除无关联的事件数据(基于事件类型域)
- 关联字段投射(广告ID,事件时间)
- 依据广告ID查询其促销活动ID(这部分数据从Redis读取),关联广告事件数据
- 对每个促销活动开一个窗口,窗口内对事件计数,并将每个窗口计数结果,以及更新时间戳一起存储在 Redis 中。 此步骤要求能够处理迟到的事件。
输入数据schema:
• user_id: UUID
• page_id: UUID
• ad_id: UUID
• ad_type: String in {banner, modal, sponsored-search, mail, mobile}
• event_type: String in {view, click, purchase}
• event_time: Timestamp
• ip_address: String
原文链接:
链接: tumblr文章
https://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at
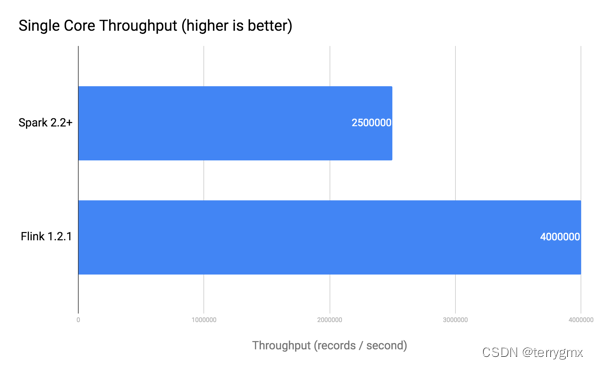
吞吐量
• Spark:250万记录单核每秒 (摘自Databricks 报告)
• Flink: 400万记录单核每秒
原文链接:
原文地址:https://www.jb51.cc/wenti/3284217.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

