

目录
1. 联合索引数据结构图
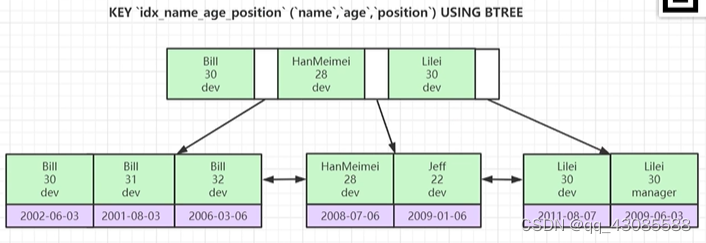
如下图所示联合索引的数据结构, 通过name,age,position三个字典进行一个联合索引,构建B+树索引结构。
2.联合索引是如何进行排序的
B+树是一个排好序的数据结构,联合索引是如何进行排序的。遵循最左原则,根据字段的先后顺序做排序。
首先比较name字段,Bill ,HanMeimei, Lilei, 这三个进行字母比较,根据首字母可以将排序排列出来
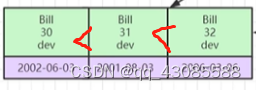
当第一个字段无法判断大小时,这时候根据第二个age字段进行排序, 30 < 31 <32
当第二个字段无法比较出来后,根据第三个字段进行排序,依次类推
字母转化Ascll进行大小的比较, d<m
如果联合索引的几个字段都相同的情况下,这时使用主键索引作比较,主键索引是唯一的,根据这个大小来进行排序


3. 联合索引查询特点
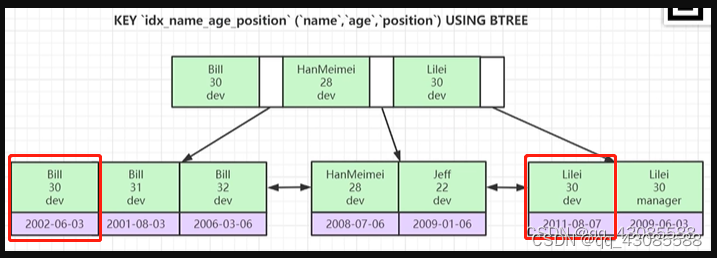
下图有一个联合索引表

EXPLAIN SELECT * FROM employees WHERE name='Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 31 and position='dev';
EXPLAIN SELECT * FROM employees WHERE position='manager';
上面3条sql语句,哪条语句会走索引?
第一条语句会走索引.
为什么第一条语句走索引?
根据联合索引最左原则,联合索引的排序的优先级为 name > age > position,而且是一环套一环的。
根据这个特性可以看出,第一条sql语句首先通过name字段进行一个索引快速查找,然后根据name=Bill过滤后的基础,在查询age=31的值
第二条sql就无法满足此条件,他没有经过name首次排序查询的前置条件,是无法进行age排序查询,当只有age = 30 and position='dev'此条件时,是无法通过索引树进行定位,只能走全表扫描,才能获取这两条记录
第三条sql和第二条一样
原文地址:https://www.jb51.cc/wenti/3284942.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

