

适宜人群:
从环境基础到进阶分布式,由浅入深,逐篇递进。
urllib是基于http的高层库,它有以下三个主要功能:
(1)request处理客户端的请求
(2)response处理服务端的响应
(3)parse会解析url
一、爬取网页内容
我们知道,网页上呈现的优美页面,本质都是一段段的HTML代码,加上JS 、CSS等,本人也是刚开始学python,这个文章也比较小白,资深老鸟请忽略~~。
本文所说的代码都是基于python3的,使用phython2的请注意
python 3.x中urllib库和urilib2库合并成了urllib库
其中urllib2.urlopen()变成了urllib.request.urlopen()
urllib2.Request()变成了urllib.request.Request()
那么获取网页有哪一些方法呢?这里列举了三种方法,具体查看代码。
import urllib.requestimport http.cookiejarurl = '直接通过url来获取网页数据print('第一种 :直接通过url来获取网页数据')response = urllib.request.urlopen(url)html = response.read()
将上面的代码copy之后,在pycharm新建一个python项目,如下图,新建一个python file ,命名为demo.py 黏贴上面的代码
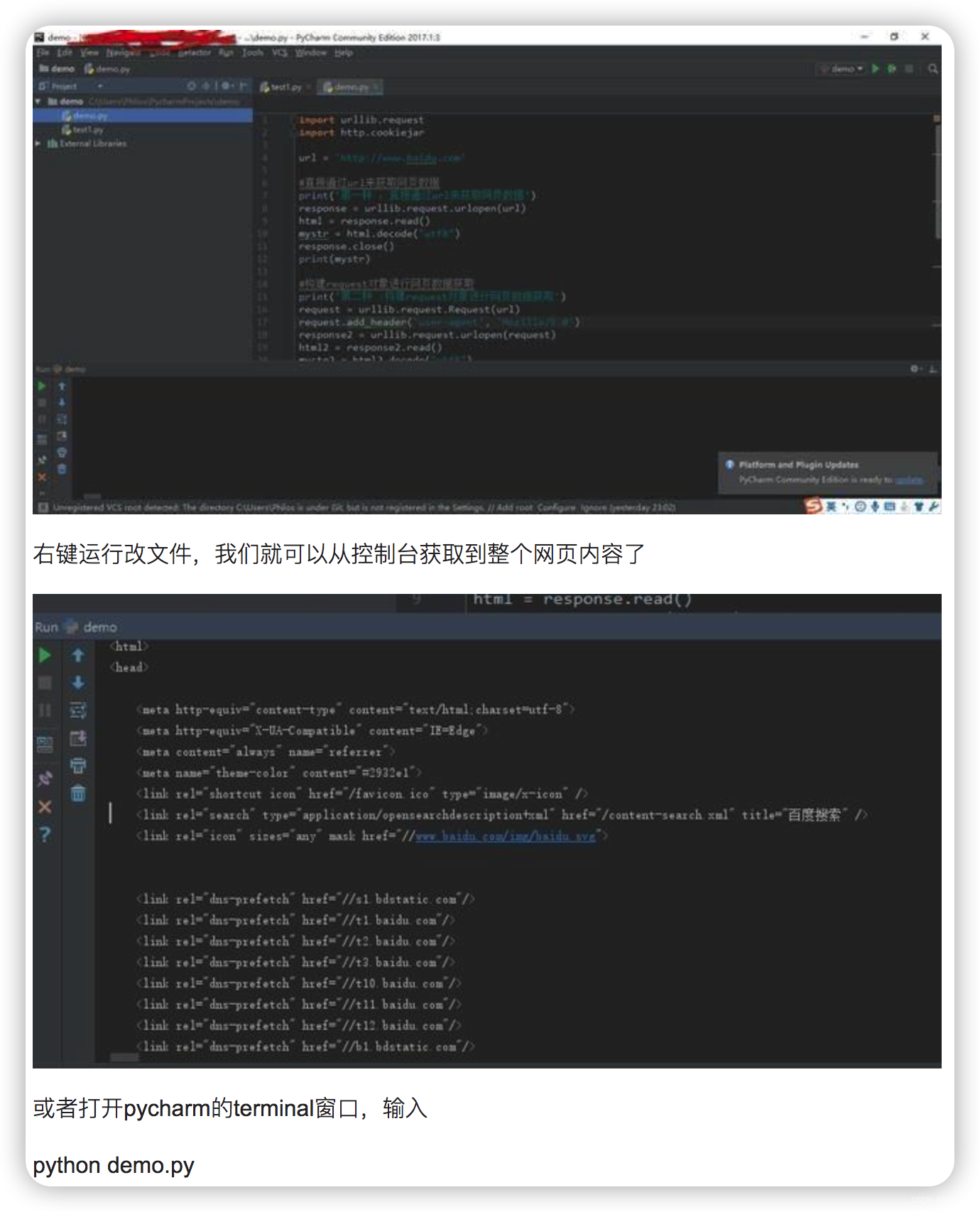
GET方式:
上面我们使用的是post的形式的,至于GET方式区别就是在URL上,我们如果直接把参数写到网址上面,构建一个带参数的URL。
values={}
四、添加头部
从上面的代码我们可以知道,可以使用build_opener 获取到opener对象,来添加头部
cookie = http.cookiejar.CookieJar()
五、http 错误
import urllib.request req = urllib.request.Request(' ')
六、异常处理
except HTTPError as e:
except URLError as e:
from urllib.request import Request, urlopen
except URLError as e:
if hasattr(e, 'reason'):
elif hasattr(e, 'code'):
from urllib.request import Request, urlopen
七、HTTP 认证
import urllib.request
八、使用代理
import urllib.request proxy_support = urllib.request.ProxyHandler({'sock5': 'localhost:1080'})
九、超时

原文地址:https://www.jb51.cc/wenti/3285517.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

