

前言:
因为实验需要复现某篇论文的模型,而作者提供的是使用hovorod进行分布式训练的代码框架,所以自己从头试着配置了一遍hovorod,大约把所有坑都踩了一遍,折腾了好久终于配好了,在这里记录一下配置过程遇到的问题和解决方法,希望可以给遇到类似问题的人启发。
开始前的一些建议
大多数人主要是在GPU上使用hovorod,因此强烈建议如果可以的话,首先阅读一下官方提供的配置文档,可以省去很多的麻烦:
- 直接配置GPU版本hovorod:
https://github.com/horovod/horovod/blob/master/docs/gpus.rst - 在虚拟环境中配置GPU版本hovorod:
https://github.com/horovod/horovod/blob/master/docs/conda.rst
https://github.com/KAUST-CTL/horovod-gpu-data-science-project
如果按照以上文档不能成功配置,可以参考以下的配置过程。由于官方只提供了cuda 10.1版本下安装tensorflow的完整虚拟环境依赖yaml,而我实验需要使用cuda 11.0版本下的pytorch,因此实际配置的过程和官方的文档有些许区别。
1 下载 NVIDIA CUDA Toolkit 11.0
注意,很多时候我们都是直接在构建好的虚拟环境中使用conda下载cudatoolkit,比如:
conda install cudatoolkit=11.0 -c pytorch
但这里在hovorod安装过程中会需要用到NVIDIA CUDA Compiler (NVCC)进行编译,如果直接使用conda下载的cudatoolkit,在安装过程中会出现错误:
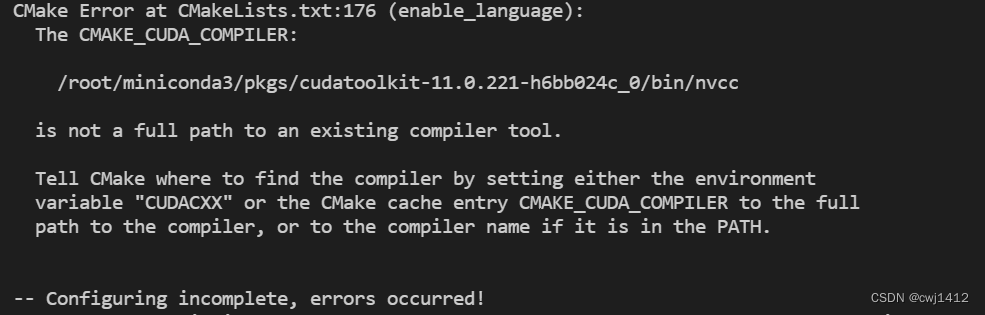
关于这两者的区别及详细分析,感兴趣的话可以到以下文档中进一步阅读:cuda和cudatoolkit的区别 和 官方提供的conda虚拟环境安装hovorod文档
1) 未安装过cuda
请先前往nvidia官网下载:https://developer.nvidia.com/cuda-toolkit-archive
根据系统配置选择即可,然后按照提供的指令输入命令行:
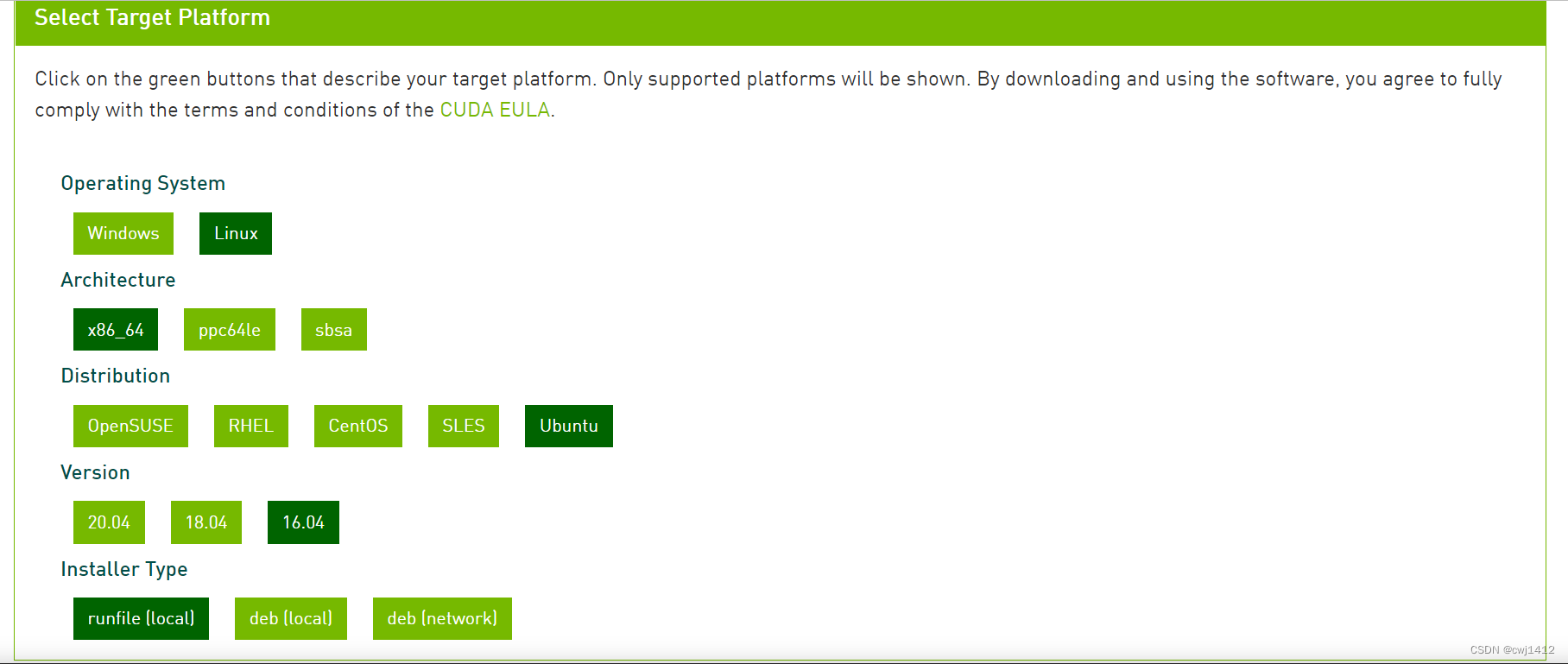
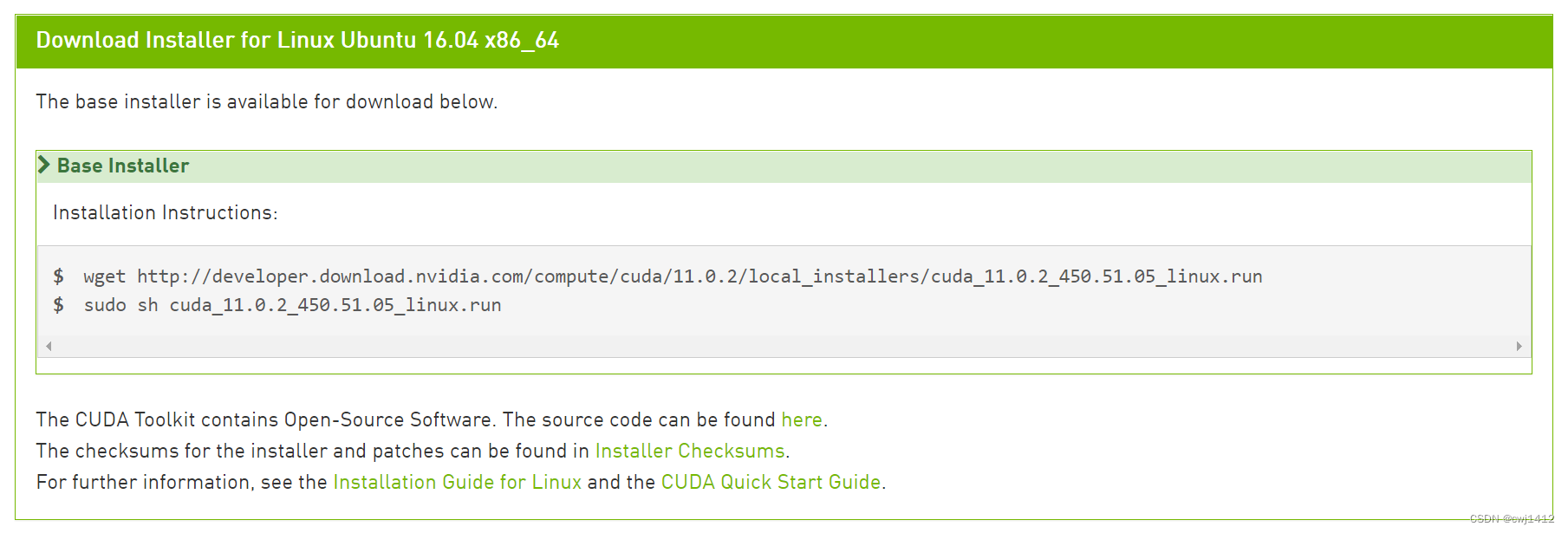
这里即需要输入如下命令,下载并安装cuda
$ wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda_11.0.2_450.51.05_linux.run
$ sh cuda_11.0.2_450.51.05_linux.run
如果已有其他版本cuda安装了驱动,可以不再安装驱动,只安装CUDA Toolkit即可。具体过程可以参考 安装多版本cuda 中的“安装CUDA”一节,其中给出了详细的安装指示,此处不再赘述。
2) 已经安装过cuda
如果本机或者服务器上已经安装cuda,甚至存在有多个版本cuda,请进行如下两步操作:
1. 检查cuda版本是否>9.0
如果可用的所有cuda版本≤9.0,也请再安装一个更高版本的cuda。否则,将会在安装时出现错误如下:
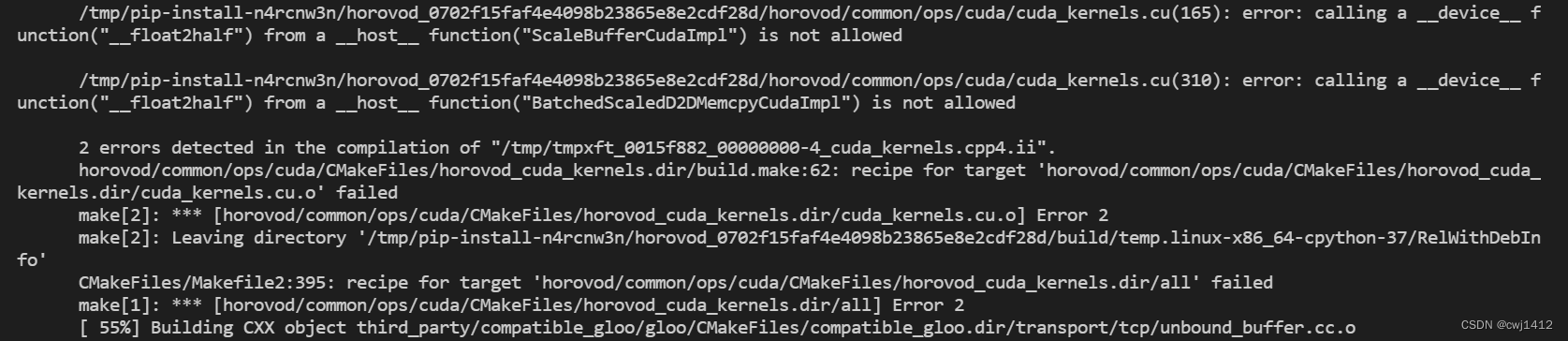
具体可以查看官方github上相关问题的讨论,https://github.com/horovod/horovod/issues/2462
主要原因在于cuda版本提高后,这里采用的函数发生变化,导致编译失败。
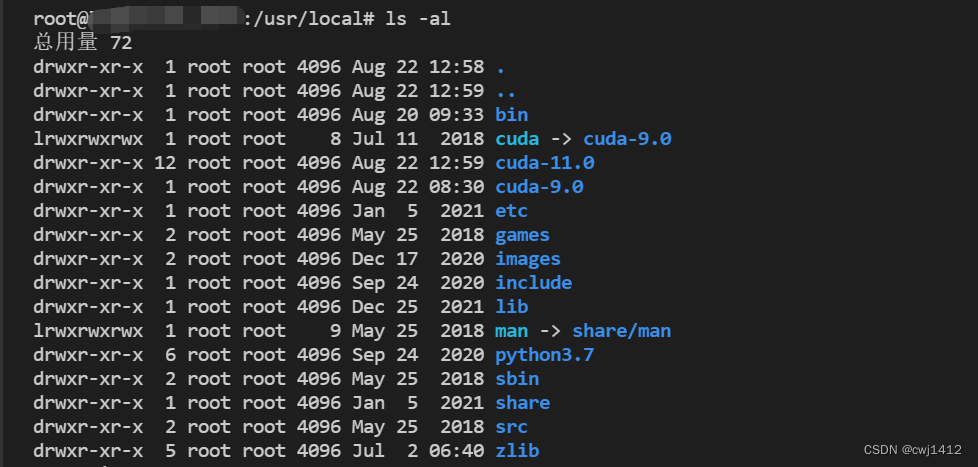
2. 检查/usr/local/cuda/的软链接是否指向的是正确版本的cuda
因为在安装hovorod时,如果没有指定HOROVOD_CUDA_HOME的路径,将默认采用/usr/local/cuda/所指的cuda版本(比如这里将采用cuda 9.0),这可能会在后面由于版本不一造成问题。
2 新建环境
1. 新建环境torch11,指定python版本为3.7:
$ conda create -n torch11 python=3.7
2. 进入新建的环境:
$ source activate torch11
or
$ conda activate torch11
3. 使用conda或pip配置需要的包:
1)根据实际需要下载pytorch、tensorflow、mxnet等深度学习模型架构需要的库。我主要需要pytorch,因此只安装pytorch其他暂不下载。
- 下载pytorch
$ conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch
其他版本下载可前往pytorch官网查看对应指令:https://pytorch.org/get-started/previous-versions/#conda-3
- 下载tensorflow
$ pip install tensorflow-gpu==2.4.*
$ conda install cudnn=8.0
- 下载mxnet
$ pip install mxnet-cu110
2)下载其他包使得安装过程更稳定(推荐)
- 官方建议同时用conda安装nvcc_linux-64、mpi4py
$ conda install nvcc_linux-64=11.0
$ pip install mpi4py
详细可以参考官方提供的yaml:https://github.com/horovod/horovod/blob/master/docs/conda.rst
3 安装Nccl2和Open MPI
1. 安装OpenMPI
网上有很多教程,可参考:https://blog.csdn.net/weixin_41010198/article/details/86289834
https://blog.csdn.net/weixin_38505222/article/details/120967948
可以通过下面的指令,查看是否成功安装mpi,成功会显示mpirun的路径:
$ which mpirun
2. 安装Nccl 2
同样可以找到很多教程,可参考:
https://blog.csdn.net/u013431916/article/details/94145584
https://zhuanlan.zhihu.com/p/108984987
可以通过如下指令,查看是否安装成功nccl:
$ apt search nccl
3. 检查gcc版本是否在5.0及以上
查看系统gcc版本:
$ gcc -v
如果版本低于5.0,需要升级到更高版本。同时注意,如果此前是通过conda安装pytorch或tensorflow,还需要安装gxx_linux-64包:
$ conda install gxx_linux-64
否则可能出现安装完成后,无法正常启用tensorflow的情况:https://github.com/tlkh/ai-lab/issues/27
4 安装hovorod
实际上官方提供了两种配置进行hovorod安装,大家可以根据机器的实际情况,选择allreduce操作更快的一种进行配置:
1. 采用Nccl加速
1)如果只有单个版本CUDA,可直接运行:
$ HOROVOD_GPU_OPERATIONS=Nccl pip install --no-cache-dir horovod
2)如果有多个版本CUDA,建议用HOROVOD_CUDA_HOME指定准确版本的路径:
$ HOROVOD_GPU_OPERATIONS=Nccl HOROVOD_CUDA_HOME=/usr/local/cuda-11.0 pip install --no-cache-dir horovod
3)如果是通过nccl-< version >.txz安装的Nccl,需要用HOROVOD_Nccl_HOME指定其路径:
$ HOROVOD_Nccl_HOME=/usr/local/nccl-<version> HOROVOD_GPU_OPERATIONS=Nccl pip install --no-cache-dir horovod
4)如果是CentOS / RHEL系统,需要写明HOROVOD_Nccl_INCLUDE和HOROVOD_Nccl_LIB路径:
$ HOROVOD_Nccl_INCLUDE=/usr/include HOROVOD_Nccl_LIB=/usr/lib64 HOROVOD_GPU_OPERATIONS=Nccl pip install --no-cache-dir horovod
2. 采用MPI加速
1)只需要修改前面的配置参数,其他同Nccl的方法(多CUDA依然需要指定路径):
$ HOROVOD_GPU_ALLREDUCE=MPI pip install --no-cache-dir horovod
2)如果MPI支持GPU上的allgather, broadcast和reducescatter操作,可以更改参数:
$ HOROVOD_GPU_OPERATIONS=MPI pip install --no-cache-dir horovod
安装完成后,请用如下指令检查是否安装成功:
$ horovodrun --check-build
如果输出如下信息,恭喜你成功安装hovorod,可以开始训练模型啦~
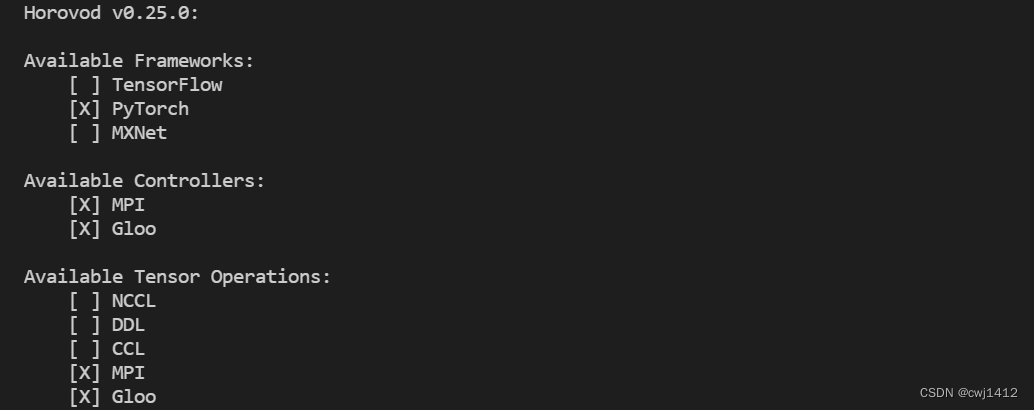
如果未能出现这些信息,那么实际上hovorod安装没有完全成功,后续使用仍然存在问题。建议到官方github issue中输入报错信息查找进一步的解决方法。
5 安装过程遇到的一些其他问题
1. Nccl安装失败
实际上我使用Nccl安装hovorod虽然显示已经成功安装,但使用check-build指令检查却一直出现各种各样的错误。在github上的issue和Stack Overflow上看了很多讨论,最终也没有完全解决。怀疑可能是服务器上的Nccl和我使用的CUDA版本不对应导致的,也可能是开始安装的hovorod版本较低的问题。
2. 多利用官方github issue
建议大家如果遇到问题,可以先去官方github issue中搜一搜,里面已经有很多各种各样问题讨论和解决的方法可以参考,比如安装hovorod后tensorflow不能正常工作:
https://github.com/horovod/horovod/issues/1831
官方建议遇到类似错误后,可以重装一次hovorod并在前面选择性加上HOROVOD_WITH_MPI、HOROVOD_WITH_GLOO、HOROVOD_WITHOUT_MXNET、HOROVOD_WITH_PYTORCH、HOROVOD_WITHOUT_TENSORFLOW参数,安装过程就会输出具体的报错信息。
卸载horovod输入如下指令:
$ pip uninstall -y horovod
3. 多CUDA版本建议还是配置一下虚拟环境的环境变量
1)在当前环境的路径下的etc/conda/activate.d文件夹里,新建activate.sh
cd /root/miniconda3/envs/torch11/etc/conda/activate.d
vim activate.sh
写入:
ORIGINAL_CUDA_HOME=$CUDA_HOME
ORIGINAL_LD_LIBRARY_PATH=$LD_LIBRARY_PATH
ORIGINAL_PATH=$PATH
export CUDA_HOME=/usr/local/cuda-11.0
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
2)在当前环境的路径下的etc/conda/deactivate.d文件夹里,新建deactivate.sh
cd /root/miniconda3/envs/torch11/etc/conda/deactivate.d
vim deactivate.sh
写入:
export CUDA_HOME=$ORIGINAL_CUDA_HOME
export LD_LIBRARY_PATH=$ORIGINAL_LD_LIBRARY_PATH
export PATH=$ORIGINAL_PATH
unset ORIGINAL_CUDA_HOME
unset ORIGINAL_LD_LIBRARY_PATH
unset ORIGINAL_PATH
原文地址:https://www.jb51.cc/wenti/3287370.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

