


监督学习的应用主要在三个方面:分类问题、标注问题、回归问题。
一、分类问题
1.基本概念
1.分类器(classifier):监督学习从数据中学习一个分类模型或者分类决策函数称为分类器(classifier);
2.分类(classification):分类器对新的输入进行输出的预测,称为分类;
3.类别(class):可能的输出称为类别。
2.分类过程
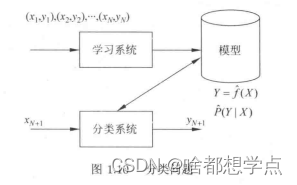
3.性能指标
通常我门用分类准确率来评价分类器的性能。所谓的分类准确率就是指:对于给定的预测数据集,分类器正确分类的样本数与总样本数之比。
对于二类分类问题,常用的评价指标是精确率、召回率。
例 1
假设有100人的身体健康检查数据,我们通过先前的训练,获得一个学习模型用于判断一个人是否患病,通过该学习模型对这100人的健康数据记性分类,具体情况如下表:
| 实际健康 | 实际患病 | 预测总计 | |
|---|---|---|---|
| 预测健康 | 40(TP) | 10(FP) | 50 |
| 预测患病 | 30(FN) | 20(TN) | 50 |
| 实际总计 | 70 | 30 |
通过上边可知,在这100人的数据中,真正患病的有30人,健康的有70人。而我们通过学习模型进行预测后,预测健康和患病的各50人。我们将:
- 实际健康预测为健康的情况用TP表示;
- 实际健康预测为患病的情况用FN表示;
- 实际患病预测为健康的情况用FP表示;
- 实际患病预测为患病的情况用TN表示;
精确率定义为:
P
=
T
P
T
P
+
F
P
P=\frac{TP}{TP+FP}
P=TP+FPTP
召回率定义为:
R
=
T
P
T
P
+
F
N
R=\frac{TP}{TP+FN}
R=TP+FNTP
准确率定义为:
a
c
c
u
r
a
c
y
=
预测正确的数量
样本总数
accuracy =\frac{预测正确的数量}{样本总数}
accuracy=样本总数预测正确的数量
二、标注问题
1.基本概念
标注问题的输入是一个观测序列,输出是一个标记序列或者状态序列。
标注问题的目的在于学习一个模型,是他能够对观测序列给出标记序列作为预测。
2. 标注过程
标注问题分为学习和标注两个过程。
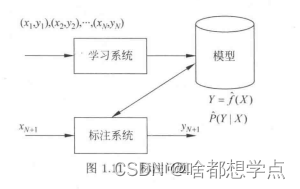
三、回归问题
1.基本概念
回归问题用于预测输入变量和输出变量之间的关系,回归模型是表示从输入变量到输出变量之间映射函数,等价于函数拟合:选择一条函数曲线时期很好的拟合一直数据且很好的预测未知数据。
2.回归过程
回归问题分为学习和预测两个过程;
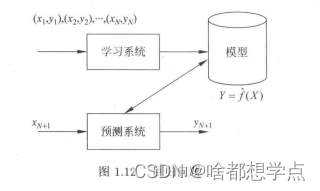
按照输入变量的个数,回归问题分为一元回归和多元回归;
按照输入变量和输出变量之间的关系的类型,回归问题分为线性回归和非线性归回。
原文地址:https://www.jb51.cc/wenti/3287371.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

