

下面所写,完全是下面的链接里视频说讲的笔记
原子类之基本类型原子类
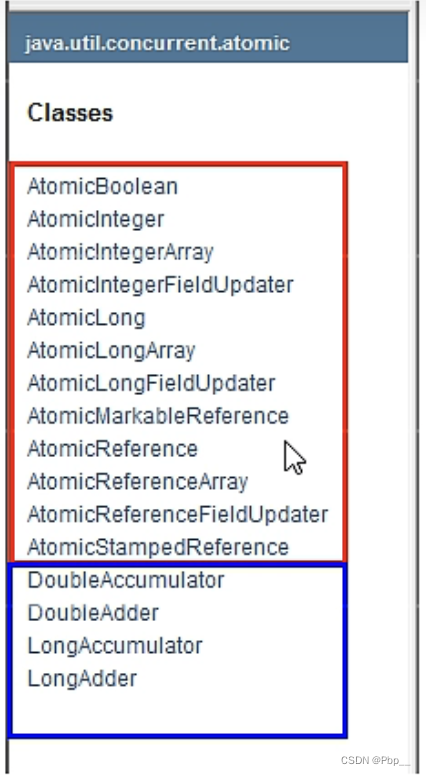
原子类是指java.util.concurrent.atomic 包下的18个原子操作类。他们天生支持原子操作,底层依赖CAS,不用加synchronized这样的重锁也能保证原子安全性的结果。
- 再进行分类
1、AtomicBoolean AtomicInteger AtomicIntegerArray AtomicIntegerFieldUpdater AtomicLong AtomicLongArray AtomicLongFieldUpdater AtomicmarkableReference atomicreference atomicreferenceArray atomicreferenceFieldUpdater AtomicStampedReference
2、DoubleAccumulator DoubleAdder LongAccunmulator LongAdder
代码的例子在com.pbp.thread.atomic包下
- 基本类型原子类:AtomicInteger , AtomicBoolean , AtomicLong
- 数据类型原子类 :AtomicIntegerArray, AtomicLongArray , atomicreferenceArray
- 应用类型原子类 : atomicreference :自旋锁 SpinLockDemo ,
AtomicStampedReference ,携带版本号的引用类型原子类,可以解决ABA问题。主要解决修改过多少次
AtomicmarkableReference :与AtomicStampedReference 类似,但是只记录有没有修改过,主要解决是否修改过。而 AtomicStampedReference 可以记录修改过多少次。 - 对象的属性修改原子类: AtomicIntegerFieldUpdater: ,原子更新对象中int类型字段值
AtomicLongFieldUpdater ,原子更新对象long类型字段值
atomicreferenceFieldUpdater ,原子更新引用类型字段值
作用:以一种线程安全的方式操作非线程安全对象内的某些字段
使用要求:更新的对象属性必须使用public volitile修饰
因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。
以前要线程安全时的做法是需要加synchronized关键字锁住整个对象
class Bank {
String bankName = "CCB";
int money = 0;
//利用synchronized锁住
public synchronized void add(){
money++;
}
}
public class AtomicIntegerReferenceUpdaterTest {
public static void main(String[] args) throws InterruptedException {
/* AtomicIntegerFieldUpdater<bank> bankUpdater =
AtomicIntegerFieldUpdater.newUpdater(bank.class, "money");*/
CountDownLatch countDownLatch = new CountDownLatch(10);
Bank bank = new Bank();
for (int i = 0; i < 10; i++) {
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(1);
bank.add();
} catch (InterruptedException e) {
e.printstacktrace();
} finally {
countDownLatch.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println(Thread.currentThread().getName()+":"+bank.money);
}
}
看看现在用atomicreferenceFieldUpdater
class Bank {
String bankName = "CCB";
volatile int money = 0;
AtomicIntegerFieldUpdater<Bank> bankUpdater =
AtomicIntegerFieldUpdater.newUpdater(Bank.class, "money");
public void transMoney(Bank bank){
bankUpdater.incrementAndGet(bank);
}
}
public class AtomicIntegerReferenceUpdaterTest {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(10);
Bank bank = new Bank();
for (int i = 0; i < 10; i++) {
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(1);
for (int i1 = 0; i1 < 1000; i1++) {
bank.transMoney(bank);
}
} catch (InterruptedException e) {
e.printstacktrace();
} finally {
countDownLatch.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println(Thread.currentThread().getName()+":"+bank.money);
}
}
在使用了atomicreferenceFieldUpdater后,发现确实和synchronized关键字呈现的效果是一样的,但是它有一个局限性,就是只能对volatile int类型的字段进行原子更新,别的类型不可以。那么如果要更新别的类型的字段呢?接下来我们看atomicreferenceFiledUpdater<T,V>,指定的volatile字段进行原子更新
例子:
class MyVal{//资源类
public volatile Boolean isInit = Boolean.FALSE;
//利用它提供的静态方法newUpdater来获取对象,可以看文档
atomicreferenceFieldUpdater referenceFieldUpdater = atomicreferenceFieldUpdater.newUpdater(MyVal.class,Boolean.class,"isInit");
public void init(MyVal myVal){
if(referenceFieldUpdater.compareAndSet(myVal,false,true)){
System.out.println(Thread.currentThread().getName()+":开始初始化");
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printstacktrace();
}
System.out.println(Thread.currentThread().getName()+":初始化结束");
}else{
System.out.println(Thread.currentThread().getName()+":无法初始化,因为已被其他线程初始化");
}
}
}
public class atomicreferenceFieldUpdaterTest {
public static final int count = 10;
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(count);
CountDownLatch countDownLatch = new CountDownLatch(count);
MyVal myVal = new MyVal();
for (int i = 0; i < count; i++) {
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(1);
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printstacktrace();
} catch (brokenBarrierException e) {
e.printstacktrace();
}
myVal.init(myVal);
countDownLatch.countDown();
},String.valueOf(i)).start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printstacktrace();
}
System.out.println(Thread.currentThread().getName()+"结束");
}
}
上面利用atomicreferenceFieldUpdater对资源类进行了微创小手术,只改变对象的某个属性时只锁定对应的属性就好了,不用使用synchronized锁住整个对象
- 原子操作增强类原理深度解析
DoubleAccumulator、 DoubleAdder 、LongAccunmulator、 LongAdder
如果是JDK8的话,推荐使用LongAdde对象,比AtomicLong性能更好(减少乐观锁的重试次数)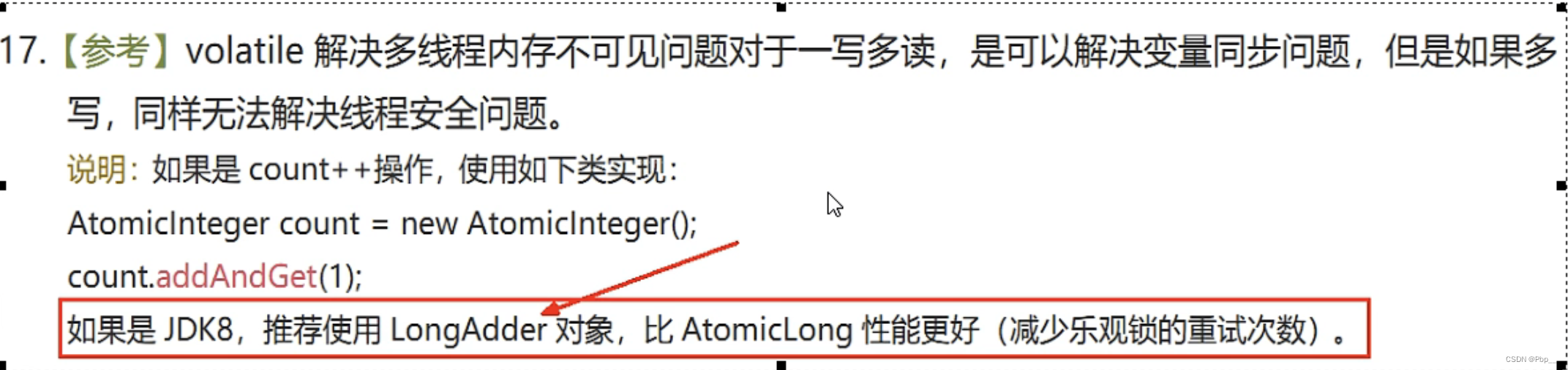
题目举例:
- 热点商品点赞计数器,点赞数加加操作,不需要实时精确
- 一个很大的List,里面都是int类型,如何实现加加操作,说说思路
入门讲解:
下面是LongAccumulator的例子:
public class LongAccumulatorTest {
public static void main(String[] args) {
LongAccumulator longAccumulator = new LongAccumulator(new LongBinaryOperator() {
@Override
public long applyAsLong(long left, long right) {
return left+right;//left是初始值,right是传进来的值
}
},1);
longAccumulator.accumulate(2);
System.out.println(longAccumulator.get());
}
}
class ClickNumber{
public int number = 0;
public synchronized void add(){
number++;
}
AtomicLong atomicLong = new AtomicLong(0);
public void addByAtomicLong(){
atomicLong.incrementAndGet();
}
LongAdder longAdder = new LongAdder();
public void addByLongAdder(){
longAdder.increment();
}
LongAccumulator longAccumulator = new LongAccumulator((x,y)-> x+y,0);
public void addByAccumulator(){
longAccumulator.accumulate(1);
}
}
public class AccumulateCompareDemo {
public static int _1W = 10000;
public static int threadNum = 50;
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch1 = new CountDownLatch(threadNum);
CountDownLatch countDownLatch2 = new CountDownLatch(threadNum);
CountDownLatch countDownLatch3 = new CountDownLatch(threadNum);
CountDownLatch countDownLatch4 = new CountDownLatch(threadNum);
ClickNumber clickNumber = new ClickNumber();
Long startTime;
Long endTime;
startTime = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
new Thread(()->{
try{
for (int i1 = 1; i1 <= _1W * 100; i1++) {
clickNumber.add();
}
}finally {
countDownLatch1.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch1.await();
endTime = System.currentTimeMillis();
System.out.println("消耗了:"+(endTime-startTime));
System.out.println("synchronized完成,总数是:"+clickNumber.number);
startTime = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
new Thread(()->{
try{
for (int i1 = 1; i1 <= _1W * 100; i1++) {
clickNumber.addByAtomicLong();
}
}finally {
countDownLatch2.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch2.await();
endTime = System.currentTimeMillis();
System.out.println("消耗了:"+(endTime-startTime));
System.out.println("addByAtomicLong完成,总数是:"+clickNumber.atomicLong.get());
startTime = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
new Thread(()->{
try{
for (int i1 = 1; i1 <= _1W * 100; i1++) {
clickNumber.addByLongAdder();
}
}finally {
countDownLatch3.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch3.await();
endTime = System.currentTimeMillis();
System.out.println("消耗了:"+(endTime-startTime));
System.out.println("addByLongAdder完成,总数是:"+clickNumber.longAdder.sum());
startTime = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
new Thread(()->{
try{
for (int i1 = 1; i1 <= _1W * 100; i1++) {
clickNumber.addByAccumulator();
}
}finally {
countDownLatch4.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch4.await();
endTime = System.currentTimeMillis();
System.out.println("消耗了:"+(endTime-startTime));
System.out.println("addByAccumulator完成,总数是:"+clickNumber.longAccumulator.get());
}
}
输出:
消耗了:1039
synchronized完成,总数是:50000000
消耗了:581
addByAtomicLong完成,总数是:50000000
消耗了:73
addByLongAdder完成,总数是:50000000
消耗了:40
addByAccumulator完成,总数是:50000000
可以看到LongAdder和LongAccumulator的效率比前面2个的高上不少,那么它们高效的原因我们分析一下:
AtomicLong:
这个原子类的底层是利用CAS,CAS只允许一个线程操作共享变量,其他线程会在外面自旋。
如果是低并发量,数据量少的情况下当然没什么问题。但是量变会引发质变。像上面的例子,几十个线程在外面自旋,cpu的占用一下就会升高
LongAdder:
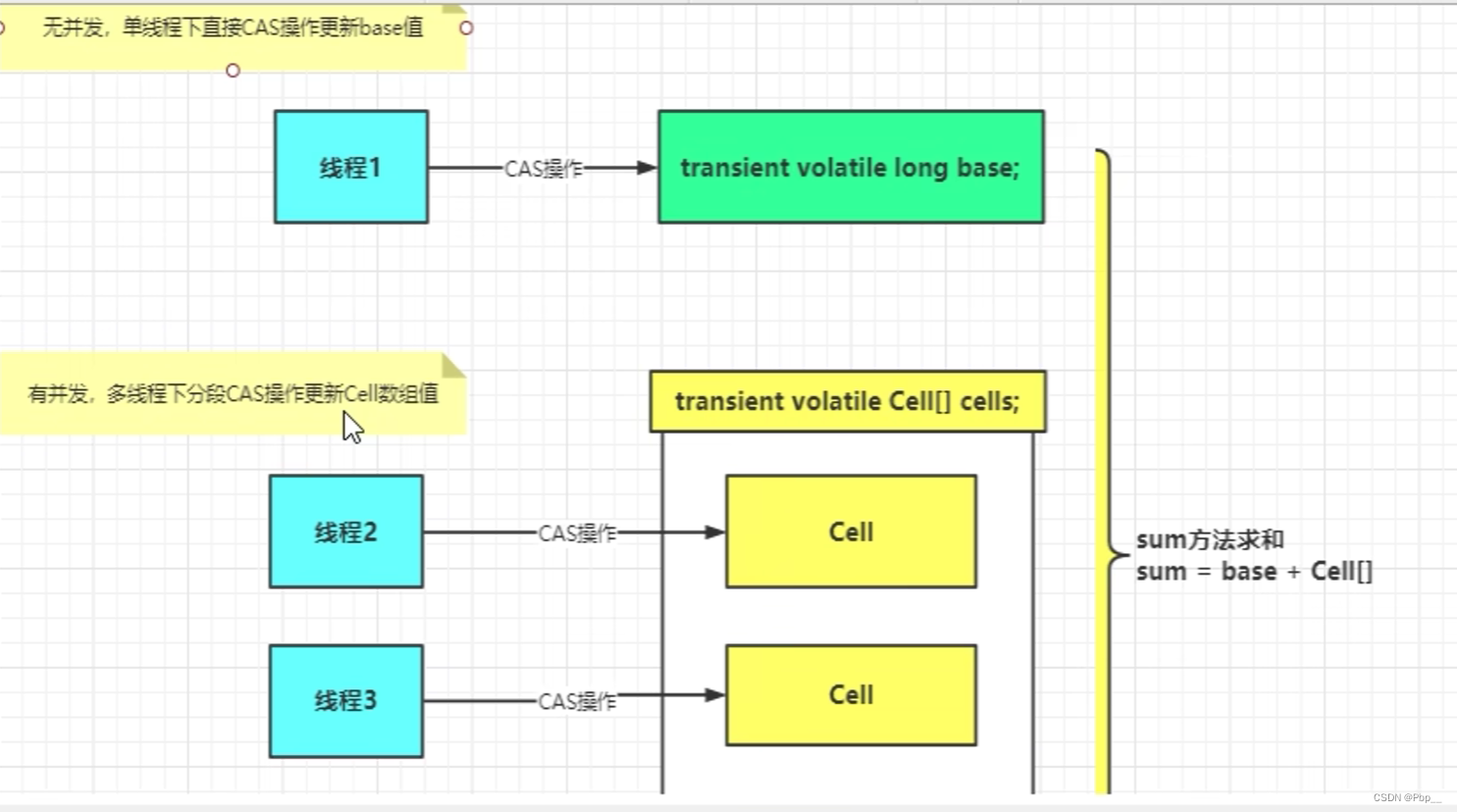
化整为零,分散热点。
底层有个属性:long base和Cell[] cells,在低并发的时候和AtomicLong一样只有一个base,当在高并发时,LongAdder会分散热点,在数组里面创建多个节点给其他线程进行操作。
例子:假设在火车站买票只有一个网点,如果现在人少来买票的话AtomicLong和LongAdder是一样的,只有一个网点,大家都在这个网点排队。当人多起来的时候,AtomicLong还是只有一个网点,只能默默承受。而LongAdder可以创建多个网点供人们买票,这就是LongAdder性能高的原因。——分散热点
总结:LongAdder的基本思路就是分散热点,将value的值分散到一个Cell数组中,不同的线程会命中到对应的数组的不同的槽中,各个线程只会对自己槽中的value进行CAS操作,这样就把热点给分散了,冲突的概率就会小很多。如果要获得真正的long值,只要将槽中的value加起来返回。
sum()会将Sell和base的值相加返回,核心思想就是将AtomicLong的value分散到多个value中,从而降级更新热点
LongAdder为什么那么快?(源码解读)
**LongAdder的继承关系:**继承与Striped64
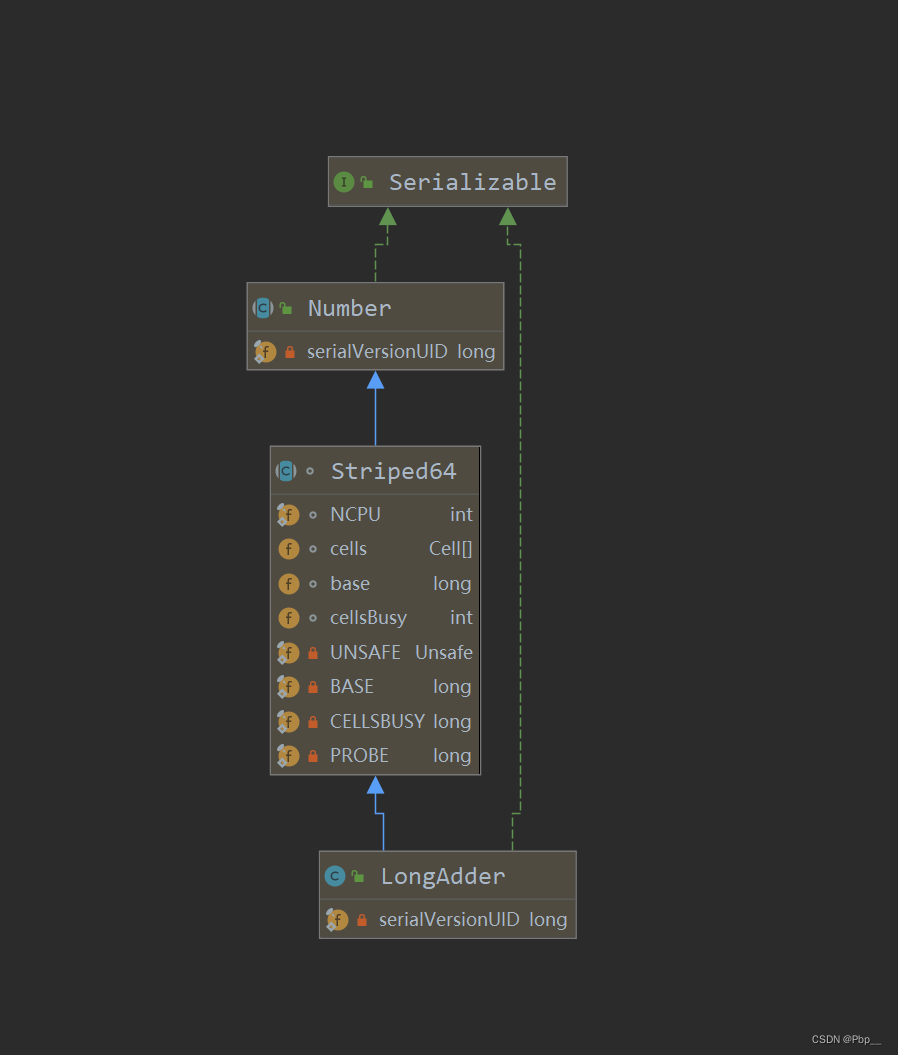
对于Striped64,里面有几个比较关键的属性:

Striped64里相关属性介绍:

主要思路就是:低并发是,LongAdder和LongAtomic的机制是一样的,但是高并发时,LongAdder会进行分散热点。
源码分析
知道LongAdder为什么那么快,开始分析源码。看源码之前,我们先看总结:
总结:LongAdder在无竞争的时候,跟AtomicLong一样,对同一个base进行操作。当出现高竞争的时候,则采用化整为零分散热点的方法,用空间换时间,用一个数组cells,将一个value拆分到这个cells里。多个线程需要同时对value进行操作时,可以根据线程id进行hash运算得到hash值,再根据哈希值映射到数组的某个下标,再对该下标对应的值进行自增操作。当所有线程完成后,将数组cells的所有值和base值求和得到最终结果。
现在以longAdder.increment()为例,基础方法有三个
- add():base的相加,数组的扩容
- longAccumulate:主要干活的方法
- sum:求和
//as为cell数组的引用
//b为base值
//v为当前线程定位到的cell的value
//m为cells长度-1,用于hash时作掩码使用
//a为当前线程命中的cell单元格
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
//判断1
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
//判断2
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
- (低并发)判断1:当只有一个线程进入的时候,判断:(as = cells) != null 为false,因为此时数组还没有初始化。接下来看第二个判断条件:这里是调用cas进行自增,在低并发时修改值成功,再取反为false,所以直接跳过下面的代码。
现在有多个线程进来了。
- (高并发)判断1:在竞争激烈的时候,对于判断1的分析如下:同样的,判断:(as = cells) != null 为false,因为此时还没有初始化数组。在第二个判断时,由于竞争激烈,cas修改值失败,所以开始执行longAccumulate()。
进入到longAccumulate(),里面有一个 for (;
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

