

一、sklearn实现
1.1 SVM介绍
| 模型类型 | 主要特点 |
|---|---|
| LinearSVC | 基于liblinear库的SVM分类模型,仅支持线性核,可选择对prime问题或者dual问题进行二次规划求解,求解算法为坐标下降法。可调节损失函数和惩罚项。多分类问题采用’ovr’策略。不支持分类概率输出。 |
| LinearSVR | 基于liblinear库的SVM回归模型,仅支持线性核,可选择对prime问题或者dual问题进行二次规划求解,,求解算法为坐标下降法。可调节损失函数和惩罚项。 |
| SVC | 基于libsvm库的C-SVC分类模型,转换为dual问题利用SMO算法求解。支持线性核和多种非线性核,但无法调节损失函数和惩罚项。多分类问题采用’ovo’策略。支持概率输出。 |
| SVR | 基于libsvm库C-SVR回归模型,转换为dual问题利用SMO算法求解。支持线性核和多种非线性核,但无法调节损失函数和惩罚项。多分类问题采用’ovo’策略。支持概率输出。 |
| NuSVC | 基于libsvm库v-SVC分类模型,参数设定、功能及实现机理与SVC基本相同,但提供对支持向量个数下限值的设定(参数nu,其本质是将SVC中的’C’的取值范围从正数域压缩为(0,1]) |
| NuSVR | 基于libsvm库v-SVR回归模型,参数设定、功能及实现机理与SVR基本相同,但提供对支持向量个数下限值的设定(参数nu,其本质是将SVC中的’C’的取值范围从正数域压缩为(0,1]) |
| OneClassSVM | 用于异常检测,支持各类核函数 |
1.2 SVC和SVR
1.2.1 模型主要参数
| 模型参数 | SVC | SVR |
|---|---|---|
| C | 正则系数,表示模型对分类/回归误差的容忍度,其值越大,表示对误差的容忍度越低,因此分类边界越复杂。默认值为1。 | 同SVC |
| epsilon | —— | tube损失函数的上下限松弛系数,表示该误差范围内不做惩罚。 |
| kernel | 核函数类型,常见可选’linear’(线性核)、‘poly’(多项式核)、‘rbf’(高斯核)、‘sigmoid’(sigmoid核),默认’rbf’。 | 同SVC |
| degree | ‘poly’(多项式核)中的幂参数,默认3。 | 同SVC |
| gamma | ‘poly’(多项式核)、‘rbf’(高斯核)和’sigmoid’(sigmoid核)中的核函数系数。可选值’scale’, ‘auto’或浮点数,默认值’scale’。若为’scale’,值根据1 / (n_features * X.var())计算;若为’auto’,值取1 / n_features。 | 同SVC |
| coef0 | ‘poly’(多项式核)和’rbf’(高斯核)的偏置参数,默认值为0。 | 同SVC |
| shrinking | SMO算法中的策略,即移除一些已经满足条件的α,从而加快收敛速度。默认值True。 | 同SVC |
| probability | 基于Platt Scaling方法,将样本点距分隔面的距离压缩到[0,1]区间,从而实现概率值的输出 | —— |
| tol | 数值算法的误差允许阈值,默认值1e-3,用于早停。 | 同SVC |
| class_weight | 分类权重,可设置权重字典或’balanced’。其会影响各类别的惩罚项C,即class_weight[i]*C。 | —— |
| random_state | 随机种子,影响SMO算法中的选择顺序。 | 同SVC |
| max_iter | 最大迭代步数,默认-1,即不设置上限。 | 同SVC |
| decision_function_shape | 控制样本点到各分类决策分隔面的距离矩阵(decesion function)形状,表示分类的置信度,可用于进行分类概率值输出。可选值’ovo’, ‘ovr’, 默认值’ovr’。 | —— |
1.2.2 模型主要方法
| 模型方法 | SVC | SVR |
|---|---|---|
| fit | 模型训练,注意参数不可设置sample_weight | 同 |
| predict | 模型预测分类或回归结果 | 同 |
| decision_function | 样本点距超平面距离 | —— |
| predict_proba | 基于Platt Scaling的分类概率值预测 | 同 |
| predict_log_proba | 基于Platt Scaling的分类对数概率值预测 | 同 |
1.2.3 模型主要属性
| 模型属性 | SVC | SVR |
|---|---|---|
| support_ | 所有支持向量的索引号 | 同 |
| support_vectors_ | 所有支持向量的向量值 | 同 |
| n_support_ | 各class的支持向量个数 | —— |
| dual_coef_ | dual问题的系数a,矩阵形状为(n_class-1, n_SV) | 同 |
| coef_ | 仅对线性核有用,primal问题的特征参数,矩阵性状为(n_class * (n_class-1) / 2, n_features) | 仅对线性核有用,primal问题的特征参数,矩阵性状为(1, n_features) |
| fit_status_ | 训练效果,0表示可以良好的拟合,而1表示不可以。 | 同 |
| intercept_ | decision function中的截断系数 | 同 |
| classes_ | 分类类别 | —— |
| probA_ | 分类结果进行Platt Scaling的系数A | —— |
| probB_ | 分类结果进行Platt Scaling的系数B | —— |
| class_weight_ | 分类权重,可设置权重字典或’balanced’。其会影响各类别的惩罚项C,即class_weight[i]*C。 | —— |
| shape_fit_ | 样本矩阵shape | —— |
1.3 sklearn随机数实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
#这里我们创建了50个数据点,并将它们分为了2类
x,y=make_blobs(n_samples=50,centers=2,random_state=6)
print(y)
#构建一个内核为线性的支持向量机模型
clf=svm.SVC(kernel="linear",C=1000)
clf.fit(x,y)
plt.scatter(x[:,0],x[:,1],c=y,s=30,cmap=plt.cm.Paired)
#建立图形坐标
ax=plt.gca()
xlim=ax.get_xlim()#获取数据点x坐标的最大值和最小值
ylim=ax.get_ylim()#获取数据点y坐标的最大值和最小值
#根据坐标轴生成等差数列(这里是对参数进行网格搜索)
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=clf.decision_function(xy).reshape(XX.shape)
#画出分类的边界
ax.contour(XX,YY,Z,colors='k',levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],s=100,linewidths=1,facecolors="none")
plt.show()
分类结果:
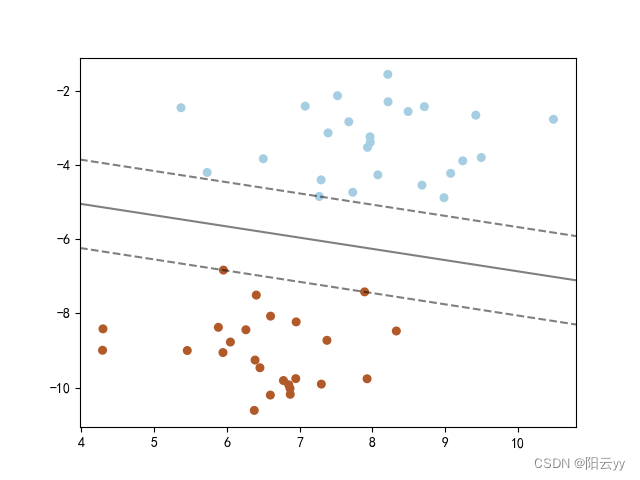
1.4 sklearn数据集实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import load_wine
def make_meshgrid(x,y,h=0.2):
x_min,x_max=x.min()-1,x.max()+1
y_min,y_max=y.min()-1,y.max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
return xx,yy
#定义一个绘制等高线的函数
def plot_contours(ax,clf,xx,yy,**param):
Z=clf.predict(np.c_[xx.ravel(),yy.ravel()])
Z=Z.reshape(xx.shape)
out=ax.contourf(xx,yy,Z,**param)
return out
wine=load_wine()
X=wine.data[:,:2]
y=wine.target
C=1.0#SVM的正则化参数
models=(svm.SVC(kernel="linear",C=C),#L1正则化
svm.LinearSVC(C=C),#L2正则化
svm.SVC(kernel="rbf",gamma=0.7),#径向基 gamma为内核宽度
svm.SVC(kernel="poly",degree=3,C=C))#特征多项式
model = []
for clf in models:
mode = clf.fit(X, y)
model.append(mode)
#设定图例
titles=('SVC with linear kernel',"LinearSVC","SVC WITH rbf ","SVC with polynomial")
#s设定一个子图形的个数和排列方式
fig,sub=plt.subplots(2,2)
plt.subplots_adjust(wspace=0.4,hspace=0.4)
#使用前面定义的函数进行画图
X0,X1=X[:,0],X[:,1]
xx,yy=make_meshgrid(X0,X1)
for clf,title,ax in zip(models,titles,sub.flatten()):
plot_contours(ax,clf,xx,yy,cmap=plt.cm.plasma,alpha=0.8)
ax.scatter(X0,X1,c=y,cmap=plt.cm.plasma,s=20,edgecolors='k')
ax.set_xlim(xx.min(),xx.max())
ax.set_ylim(yy.min(),xx.max())
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(title)
plt.savefig('wine_SVM')
plt.show()
分类结果:

1.5 SVM回归
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
boston=load_boston()#boston数据中含有13个特征信息
#划分数据集
X,y=boston.data,boston.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=8)#random_state是设置随机种子数
st=StandardScaler()
st.fit(X_train)
X_train=st.transform(X_train)
X_test=st.transform(X_test)
for kernel in ['linear','rbf']:
svr=SVR(kernel=kernel)
svr.fit(X_train,y_train)
print(kernel,"核函数训练集:",svr.score(X_train,y_train))
print(kernel,"核函数测试集:",svr.score(X_test,y_test))
回归结果:
linear 核函数训练集: 0.7056333150364087
linear 核函数测试集: 0.6983657869087585
rbf 核函数训练集: 0.6649619040718826
rbf 核函数测试集: 0.6945967225393969
原文地址:https://www.jb51.cc/wenti/3287901.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

