

目录
一、数据仓库概述
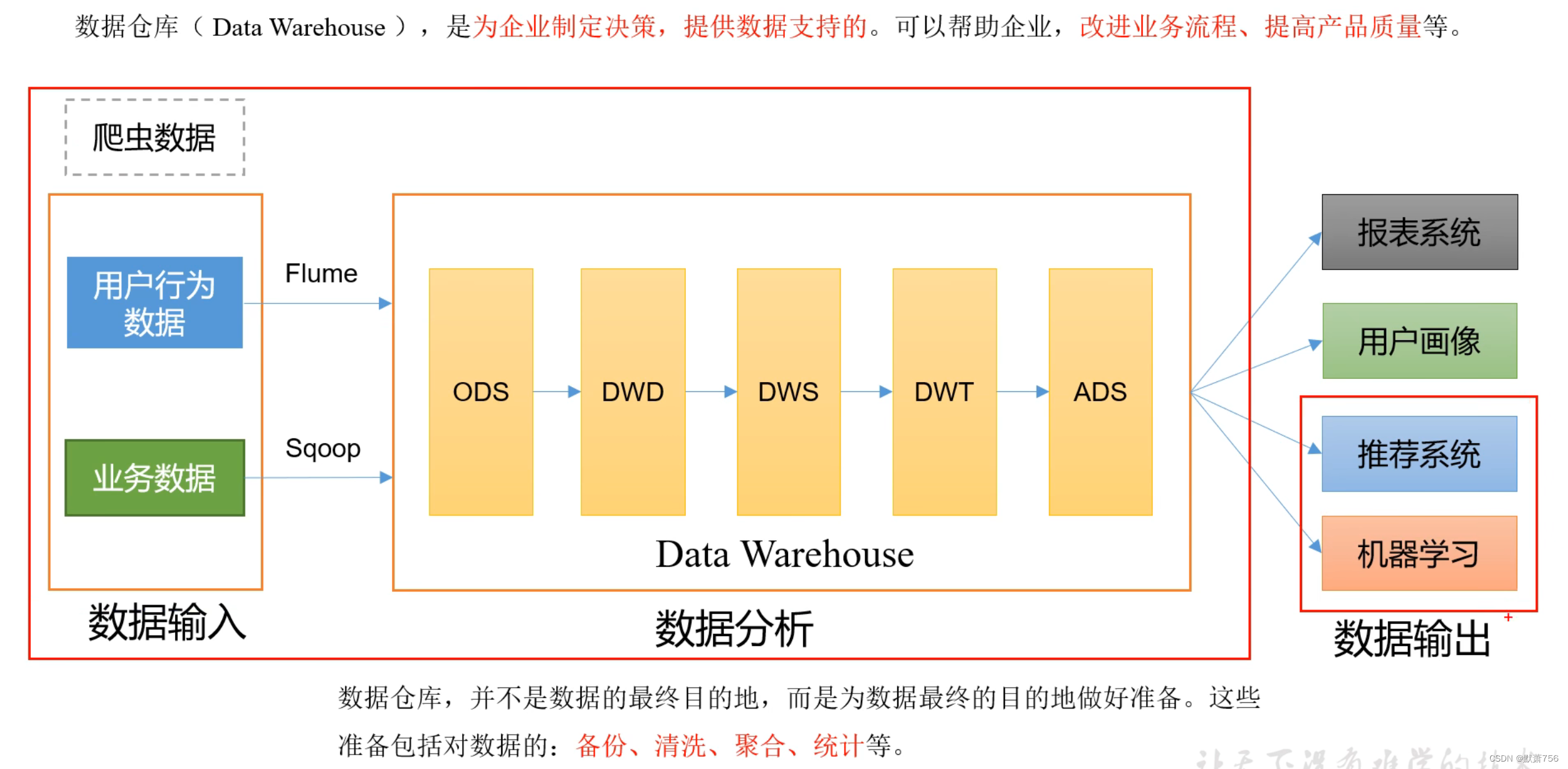
二、项目需求及架构设计
1、需求分析

2、项目框架
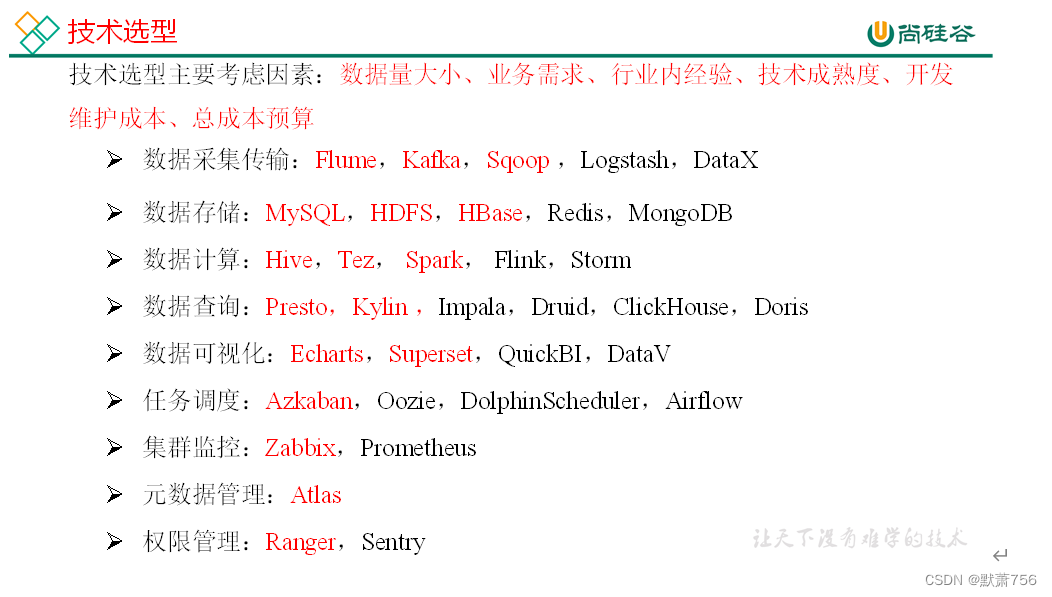
2.1 技术选型
三、数据生成模块
1、目标数据
我们要收集和分析的数据主要包括页面数据、事件数据、曝光数据、启动数据和错误数据。
四、数据采集模块
各类安装及编写脚本这里就不进行过多说明了
1、Kafka
1.1 Kafka常用命令

Kafka Topic列表在Flume安装后再进行创建
1.2 项目经验之Kafka机器数量计算

2、Flume
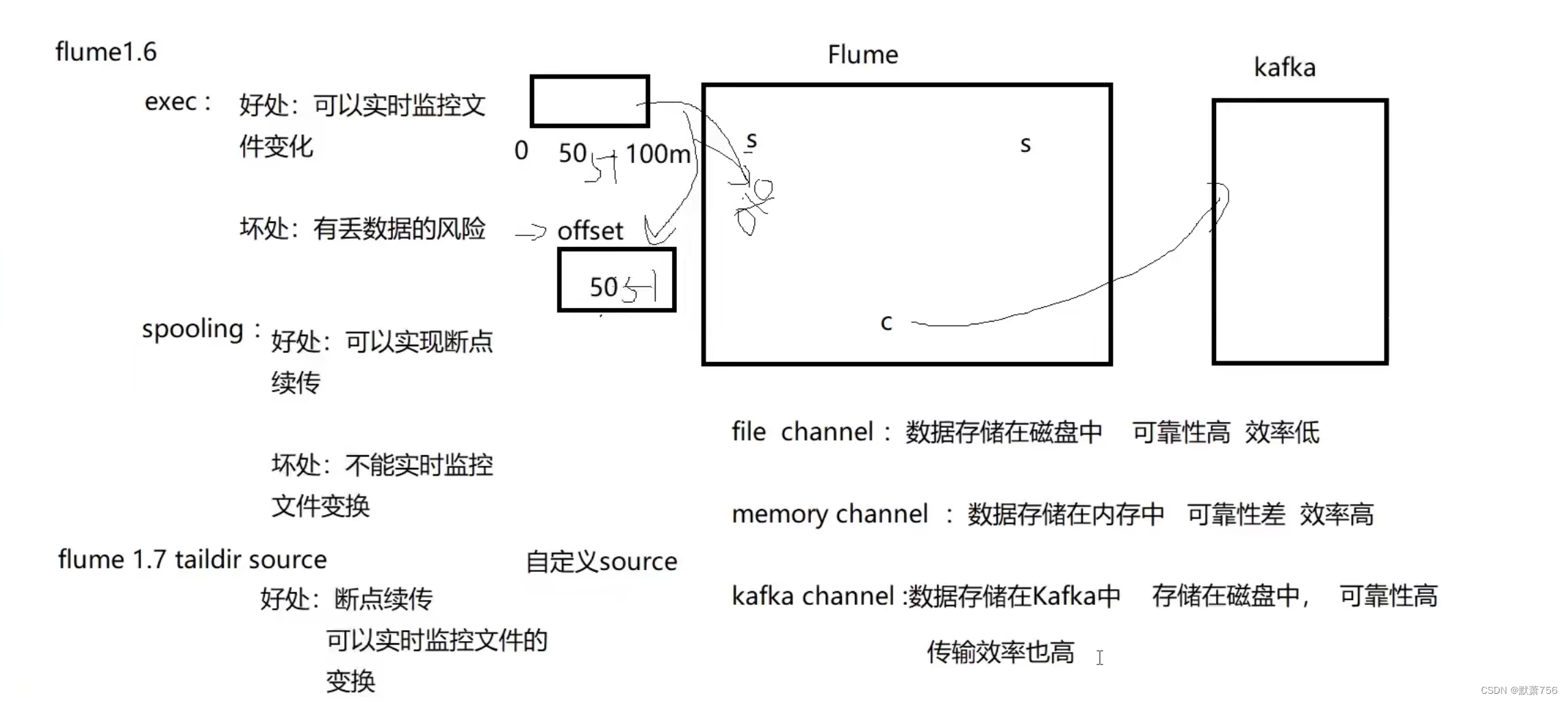
2.1 组件选型

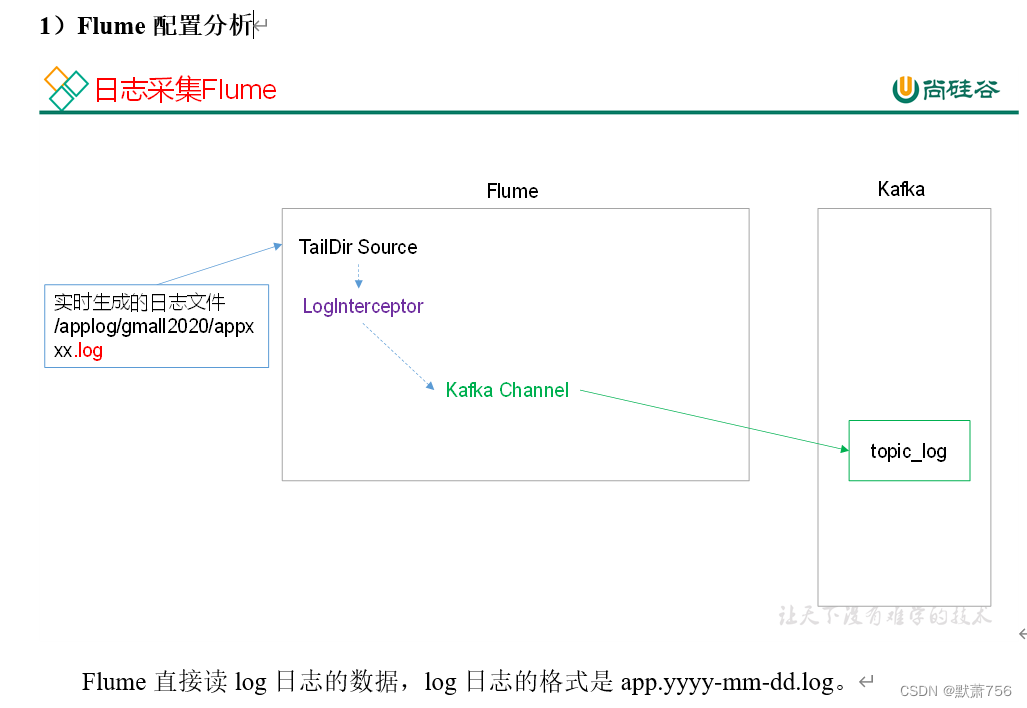
2.2 日志采集Flume配置
开始的部分安装已经完成,安装的具体内容可以去查看文档,这里不做具体说明,但是要注意要每一个集群的启动顺序,不然貌似无法启动完成
2、消费Kafka数据Flume
2.1消费者Flume配置


文件配置如下:
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
#控制生成的小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
2.2 Flume时间戳拦截器
由于Flume默认会用Linux系统时间,作为输出到HDFS路径的时间。如果数据是23:59分产生的。Flume消费Kafka里面的数据时,有可能已经是第二天了,那么这部门数据会被发往第二天的HDFS路径。我们希望的是根据日志里面的实际时间,发往HDFS的路径,所以下面拦截器作用是获取日志中的实际时间。
解决的思路:拦截json日志,通过fastjson框架解析json,获取实际时间ts。将获取的ts时间写入拦截器header头,header的key必须是timestamp,因为Flume框架会根据这个key的值识别为时间,写入到HDFS。
package com.atguigu.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parSEObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
events.clear();
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
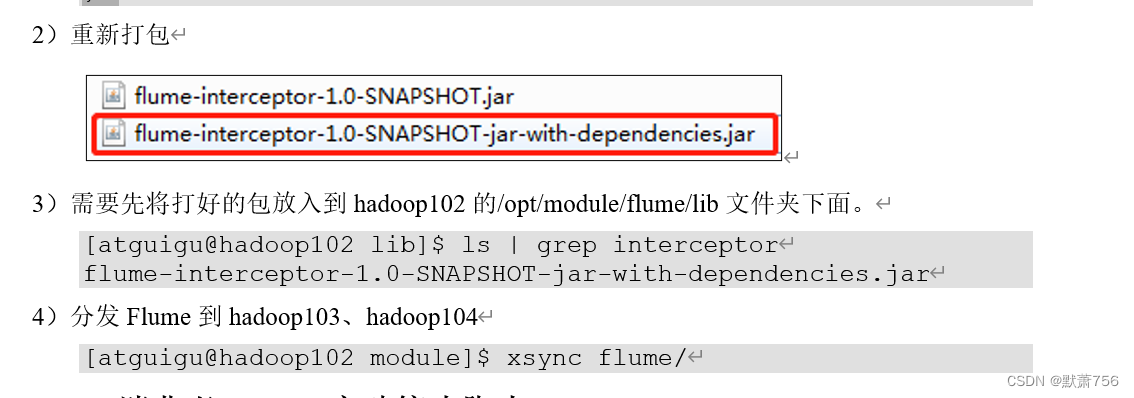
3、常见问题及解决方案
3.1 2NN不能显示完整信息
1)问题描述
访问2NN页面http://hadoop104:9868,看不到详细信息
2)解决办法
(1)在浏览器上按F12,查看问题原因。定位bug在61行
[atguigu@hadoop102 static]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/hdfs/webapps/static
[atguigu@hadoop102 static]$ vim dfs-dust.js
:set nu
修改61行
return new Date(Number(v)).toLocaleString();
(3)分发dfs-dust.js
[atguigu@hadoop102 static]$ xsync dfs-dust.js(4)在http://hadoop104:9868/status.html 页面强制刷新
原文地址:https://www.jb51.cc/wenti/3288069.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

