

-
目录
1.SVM与KNN区别
Joshua say:
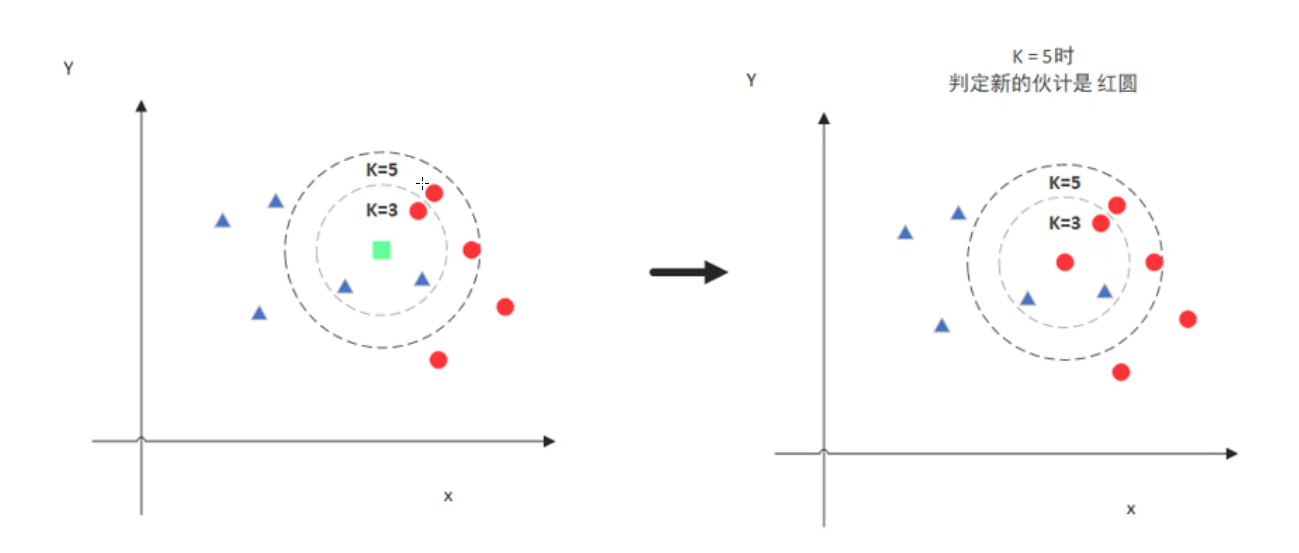
1. KNN没有训练过程,基本原理就是找到训练数据集里面离需要预测的样本点距离最近的K个值(距离可以使用比如欧式距离,K的值需要自己调参)来实现分类。
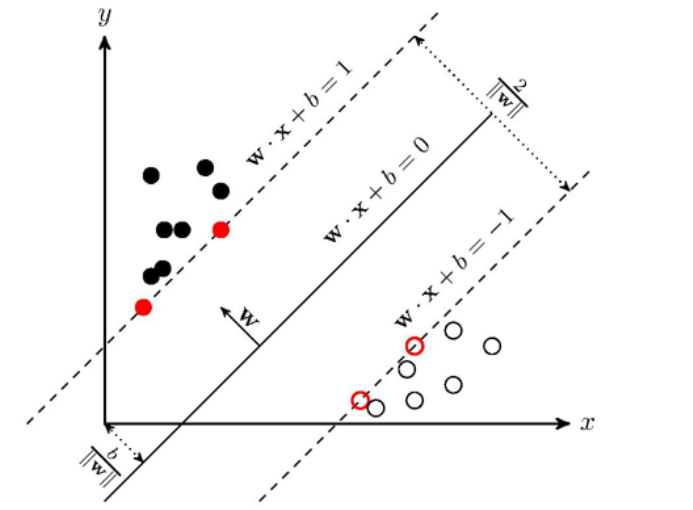
SVM需要超平面wx+b来分割数据集(此处以线性可分为例),因此会有一个模型训练过程来找到w和b的值。训练完成之后就可以拿去预测了,根据函数y=wx+b的值来确定样本点x的label,不需要再考虑训练集。对于SVM,是先在训练集上训练一个模型,然后用这个模型直接对测试集进行分类。
2. 根据第一条,两者效率差别极大。
KNN没有训练过程,但是预测过程需要挨个计算每个训练样本和测试样本的距离,当训练集和测试集很大时,预测效率感人。SVM有一个训练过程,训练完直接得到超平面函数,根据超平面函数直接判定预测点的label,预测效率很高(一般我们更关心预测效率)。
3. 两者调参过程不一样。 KNN只有一个参数K,而SVM的参数更多,在线性不可分的情况下(这种情况更普遍),有松弛变量的系数,有具体的核函数。
————————————————
原文链接:https://blog.csdn.net/WarGames_dc/article/details/89235746
2.SVM原理梳理
支持向量积:
1> 两个范围区域中哪两个点相对来说比较近(挑出来作为支持向量)
2>找出一条决策边界将其分开
注意:支持向量要较小的,考虑离自己最近的雷
决策边界要大的,要最宽的道路才能行动的更快,不容易踩雷
寻找支持向量:
距离与数据定义:在平面上构造了直线,点到平面的距离公式,借助了向量和法向量进行相关求解
具体步骤:
1. 距离计算(点到平面距离)
点知道,面不知道(面为假设),用到向量和法向量知识
2. 目标函数
目的:找到一条线,使得离该线最近的点最远
放缩变换和优化目标
目标函数能够体现SVM的基本定义
3. 部分数学原理
拉格朗日乘子法(约束条件下求极值)
4.软间隔优化
考虑一些异常的噪音,让分类更合理。(引入松弛因子)

目标函数的变化,及C的引入(能够体现容错能力)

升维,二位的变成三维的,可能能够很好的用平面分开

映射到高维,可能更好看出来不同,但确实计算量增大了很多
3.SVM代码运行注释
加载相关包:

加载数据、切分数据集:

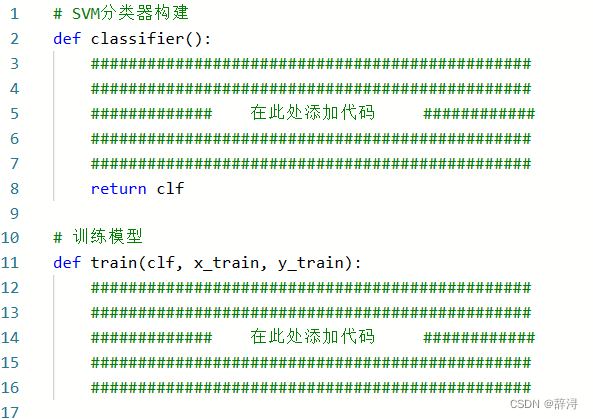
初始化分类器实例,训练模型 :

展示训练结果及验证结果 :


原文地址:https://www.jb51.cc/wenti/3288525.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

