

机器之心专栏
机器之心编辑部
本文解读了香港科技大学陈雷教授团队、北京邮电大学邵蓥侠副教授、上海交通大学沈艳艳副教授和香港理工大学曹建农教授联合发表在国际数据库与数据管理顶级会议 vldb 2022 上的论文“面向大规模图神经网络的陈旧性感知通信回避的去中心化全图训练框架(SANCUS: Staleness-Aware Communication-Avoiding Full-Graph Decentralized Training in Large-Scale Graph Neural Networks)”,该论文获得了大会最佳研究论文奖(Best Regular Research Paper)。
近年来,图神经网络(GNN)在社交媒体、电子商务、知识图谱、推荐系统、生命科学等领域得到了广泛应用。随着图数据规模的快速增长,亟需发展分布式大规模图神经网络高效训练技术。现有的方法主要采用中心化的参数服务器(PS)架构,计算节点间的大量网络通信成为了训练的性能瓶颈。
为了克服这一挑战,本文提出了一种陈旧性感知且通信回避的去中心化全图 GNN 训练框架 SANCUS,实现了高效地分布式图神经网络训练。SANCUS 通过利用历史嵌入,主动创造异步性,避免了大量通信;设计了跳过广播(skip-broadcast)机制,训练时动态重塑通信拓扑,实现了嵌入的灵活传输。为了自适应地维护历史嵌入,提出了嵌入有界陈旧性指标,并从理论上证明了陈旧性感知训练框架的收敛性。实验结果表明,与 SOTA 方法相比,在不损失精度的前提下,SANCUS 可以节约高达 74% 的网络通信,平均吞吐量提升至少 1.86 倍。SANCUS 将传统分布式机器学习中的有界梯度陈旧性泛化到去中心化分布式 GNN 中的历史嵌入上,理论上新指标可以推广至其他分布式 GNN 训练架构。

论文链接:https://www.vldb.org/pvldb/vol15/p1937-peng.pdf代码链接:https://github.com/chenzhao/light-dist-gnn更多详细信息:http://home.cse.ust.hk/~leichen/一、引言
如今图神经网络 (GNNs) 因为具有良好的学习性能,已广泛应用于不同领域的预测分析任务。但面对大规模图,GNN 仍面临着巨大挑战,主要表现为随着数据和模型规模的增长而产生的占用内存和计算资源的爆炸式增长。分布式 GNN 训练成为了一种有效的解决方案。流行的基于采样的分布式 GNN 训练存在信息损失、采样开销大、收敛性保证难的问题,本文聚焦全图 GNN 的分布式训练。分布式全图 GNN 训练,除了占用大量的内存外,由于不规则邻域访问和迭代学习过程的耦合,计算节点间产生了密集的通信,包括梯度、模型参数以及嵌入的传输,这使得高效的分布式 GNN 训练更具挑战性。目前如阿里巴巴、亚马逊、微软等公司研发的分布式 GNN 系统主要采用中心化参数服务器 (PS) 架构。为了追求效率和可伸缩性,PS 架构需要昂贵的预处理和复杂工作流。对于大规模神经网络,研究表明去中心化的架构在理论上更具有优越性。在图神经网络方面,CAGNET 是当前最先进的去中心化的训练算法。然而,CAGNET 在训练过程中需要大量同步,产生了大量的额外通信开销。
针对上述挑战,本文提出了陈旧性感知且通信回避的去中心化分布式 GNN 训练框架 SANCUS。它将 GNN 训练视作一系列矩阵乘法,通过对历史嵌入进行自适应的缓存和跳过广播,极大地降低了训练过程中的网络通信。同时,设计了有界陈旧性指标,并基于指标动态缓存历史嵌入,实现了主动地 GNN 异步训练。此外,从理论上证明了新框架下模型的收敛性,并通过大量实验验证了 SANCUS 通信避免的效果和精度的稳定性。
二、SANCUS 介绍
2.1 框架概述

上图展示了 SANCUS 框架的基本训练流程,主要包括五个步骤:(1)数据加载,(2)陈旧性边界检查,(3)嵌入广播,(4)GNN 模型计算,以及(5)结果缓存。接下来分别介绍这些步骤。

(1)如上图所示,将全图的整个稀疏邻接矩阵和密集嵌入矩阵横向划分为矩阵块和(i [1,4]),与完整的权重矩阵 W 一起存入,每个 GPU 保留自己的完整模型副本;
(2)在每个 GPU 上,广播上一轮 GNN 计算结果之前,根据陈旧性指标检查嵌入的陈旧性,如果对应 GPU 的嵌入陈旧度在规定边界内,则跳过嵌入广播,并用缓存的历史嵌入迭代模型计算;
(3)否则,如果特征的陈旧性超过边界,则将最新嵌入一对多并行广播到所有 GPU,在缓存中更新。在 GPU 轮询一轮之后,就可以为一层更新整个嵌入矩阵 H;
(4)将最新嵌入或缓存的历史嵌入加载到 GNN 模型中进行计算;
(5)在广播之前,更新的嵌入被分派到下一迭代的陈旧性检查中。
2.2 传播算法和训练过程
训练过程如上图所示,将分布式 GNN 视作矩阵乘法序列,以避免聚合过程中密集的邻居获取。邻接矩阵 A 和嵌入矩阵 H 被分块存放到不同的设备,对并行的分布式进程 P(i),定义了矩阵乘法的中间结果。SANCUS 利用 Ring-AllReduce 进行前向、反向传播。

SANCUS 的传播算法如上图所示。计算设备并行分别对每个层进行训练。在向其他设备广播之前,先检查进程 j 的嵌入
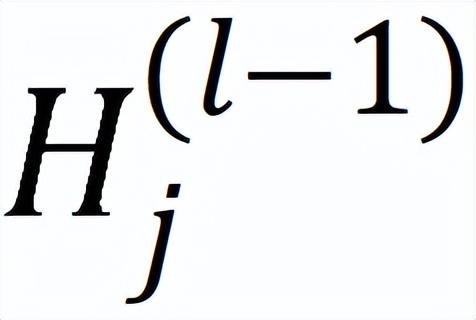
的陈旧性。若进程状态是活跃,则将
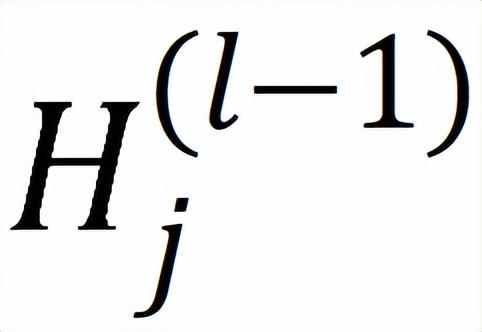
从根 rank 通过环形通信拓扑中的一对多广播依次复制到所有设备,并相应地缓存。否则,如果进程陈旧,SANCUS 将执行跳播。这一迭代进程 j 停止广播

,所有其他设备重复使用历史嵌入

的缓存版本。每个设备在本地进一步计算中间结果
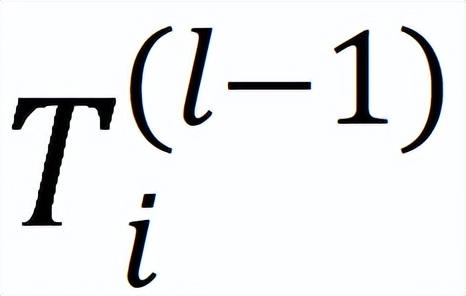
,用于计算嵌入

。在得到最新嵌入
后,检查
是否在陈旧性边界内,对应更新进程状态标识 F(i)。在反向传播时,梯度

以类似的方式广播。为最后,为了更新模型,执行 AllReduce 整合来自所有设备的梯度结果并将其发送到所有 ranks。
三、缓存历史嵌入管理机制和自适应跳播机制
3.1 缓存历史嵌入
为进一步降低设备间通信,在训练中主动的利用历史嵌入。历史嵌入缓存在每个 GPU 中,只保留一份最近用到的嵌入。进程
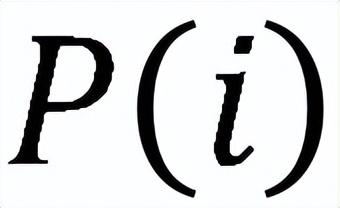
活跃以广播嵌入子矩阵

的最新结果或陈旧以重复使用历史
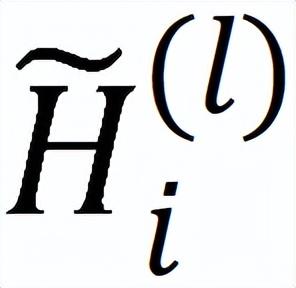
,具体如下式所示:
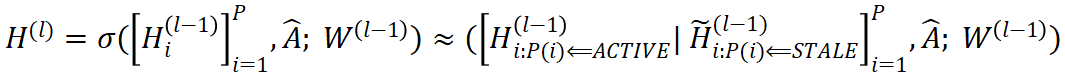
3.2 自适应跳过广播
SANCUS 实现了一种通信原语,即一种跳过广播 (Skip-broadcast) 机制,以达到设备间的通信和批量同步。
特别地,SANCUS 允许在训练过程中无缝重构通信拓扑结构。SANCUS 为每个进程 i 存储一个状态标志
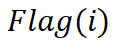
,指示该设备上进程计算的嵌入
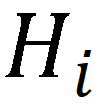
相应的状态。具体来说,活跃状态意味着该进程需要广播嵌入
的最新版本到所有其他设备进程,并缓存。如果状态陈旧, 则跳播
并让其他设备使用缓存的陈旧嵌入。
3.3 嵌入陈旧性的三种度量及其管理机制
跳过广播机制可以有效降低通信量,但每个设备上存在不同版本的嵌入,在系统中主动的创造了不一致性。为了将不一致控制在合理范围,需要对陈旧的历史嵌入进行管理,具体来说,利用边界来约束嵌入陈旧度。为保持去中心化, SANCUS 在每个设备上设计了轻量本地状态跟踪器以进行高效的有界嵌入陈旧性检查。
陈旧性最基本的定义是:让

和 e 分别表示陈旧嵌入的 epoch 数和当前 epoch 数,可容忍的陈旧 epochs 的最大值为

,即历史嵌入满足

。在每
个 epochs 之后广播嵌入。照此定义检查陈旧性的算法如下。这个检查算法和 Algorithm 1 组成 SCS-E 算法。

接着,SANCUS 提出了更加灵活的自适应陈旧性度量:每个进程必须在最多个 epoch 接收到来自邻居的陈旧嵌入后,向其他设备广播最新嵌入。检查算法 Algorithm 2 和 Algorithm 1 组成 SCS-A 算法。

最后,SANCUS 还提出了基于变化值的自适应陈旧性度量:给定边界, ,当嵌入变化超过,就需广播最新版本。这里不需要版本追踪,只用考虑变化量大小。Algorithm 4 和 Algorithm 1 组成 SCS-H 算法。

理论支撑:文中作者分析了系统的通信成本界限。证明了 SANCUS 中嵌入和梯度的近似误差都是有边界的,同时保证了训练的收敛。SANCUS 的收敛速度比基于抽样的图神经网络方法更快也更接近于全图训练。
四、实验结果
实验选取的主要模型是 GCN。实验在四种不同的 GPU 配置上进行:①通过 PCIe 3.0 X 16 连接的 8 个 RTX 2080 Ti;②通过 10Gbps 以太网连接的两台服务器,每个服务器通过 PCIe 3.0 有 4 个 RTX 2080 Ti;③四个通过 NVLink 连接的 A100 40GB;④ 4 个通过 NVLink 连接的 V100 32GB。作者在 Flickr、Reddit、Amazon 和 ogbn-products 上使用①评估,在 ogbn-products 上使用①②③评估。对当前最大的 ogbn-papers100M 数据集使用③,而④作为常用的训练环境配与其他 SOTA 系统进行总体比较。作者亦实现了 GAT 模型展示系统通用性。
对于 Flickr、Reddit、Amazon、ogbn-products 和 ogbn-papers100M,总的训练 epoch 数分别为 300/300/400/500/200。对于陈旧度界限,选择范围 [1,7] 的,范围 [1,5] 中的,和范围 [0.01,0.05] 中的来控制变化幅度。
4.1 不同环境下的通信避免情况

数据集以规模递增顺序展示,以此展示模型的可扩展性。图中只展示精度损失在 0.01 以内的结果。与 SOTA 工作 CAGNET 和有界梯度法 SkipG 相比,我们的所有系统进一步避免了至少 35% 到 74% 的通信。虽然基于传统梯度陈旧度的 SkipG 也优于 CAGNET,但它以准确性为代价。此外,如图所示,在不同的数据集上,SANCUS 的各种变体仍比 SkipG 获得了 29% 到 63% 的通信降低。SANCUS 在 Flickr 上使用 SCS-H3(=0.03)避免了约 74% 的通信,在 Reddit 上使用 SCS-A3 避免了 48% 的通信,在 ogbn-products 上使用 SCS-H3 避免了 50% 的通信。
为进一步显示训练时间的改进,下表给出了 epoch 中计算和通信的具体时间。
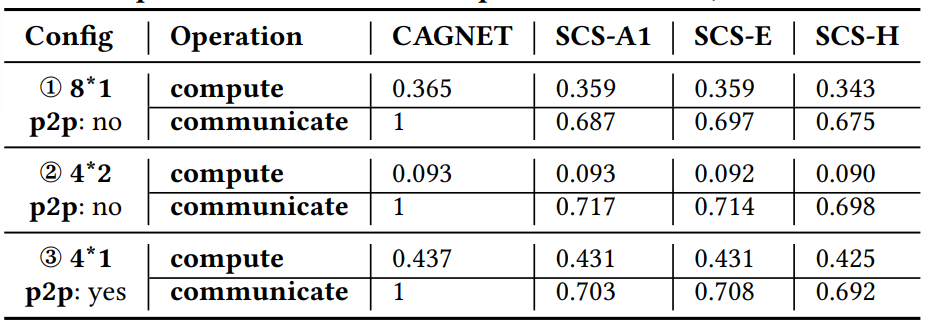
接下来,用表现最差的 SANCUS 变体 SCS-E1/A1/H1(避免通信最少)演示通用性。下图根据 GPU 配置、GPU 数量、GNN 总层数和 ogbn-products、Flickr、Reddit 和 ogbn-papers100M 上的隐藏特征大小来表示系统的变量。

具体来说,图 a 中不同 GPU 配置下的通信时间差异很大。尽管 GPU 配置对通信本身有很大的影响, SANCUS 仍在所有配置中展示了良好的通信避免表现 -- 无论是单机多卡还是多服务器环境。进一步检查,SCS-A1 可以在所有设置 (包括多服务器设置) 中一致地实现最少的通信开销。再者,如图 b 所示,随着 GPU 数量增加,相对于 CAGNET 的总成本依然不断降低。虽然通信成本随 GPU 数量增加而增加,但是 SANCUS 可以将使用 8 个 GPU 的通信成本,减少到接近使用 2 个 GPU 的 SOTA 工作 CAGNET 的通信成本,并减少 67% 的计算成本。更重要的是,SANCUS 避免的通信比例随着 GPU 使用数量反而增加,这是中心化 PS 架构难以实现的。此外,当增加隐藏特征大小时,与 CAGNET 相比,SANCUS 变体的通信增加更少也更慢。以上总结了 SANCUS 的鲁棒性和通用性。
4.2 通信避免情况下准确率的表现
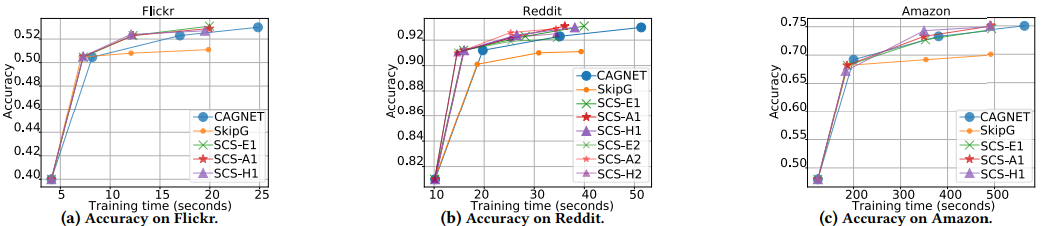
SANCUS 所有的策略变体都收敛到与全图 SOTA 工作非常接近或相同的准确率值(<0.005),甚至更高。此外,达到满意精度的时间也快得多。
4.3 与 SOTA 的对比
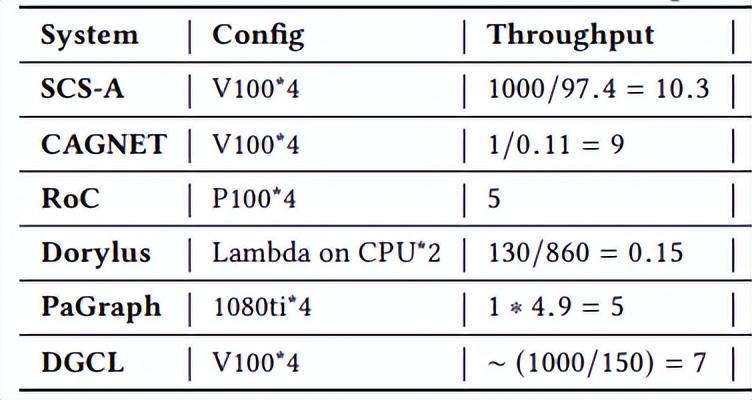
在常用的 Reddit 数据集上,上表比较了表现最差的 SANCUS 变体 SCS-A1 与五个相关 SOTA 分布式系统的吞吐量(epoch /second),包括:CAGNET、RoC、Dorylus、基于采样的 PaGraph 和 DGCL。可以看到,避免通信最少的 SCS-A1 仍然优于所有相关的 SOTA 分布式 GNN 系统。SCS-A1 策略平均吞吐量至少快 1.86 倍,每秒可以处理 10.3 个 epochs。与目标是低成本的全图分布式 GNN 训练系统 Dorylus 相比,SANCUS 的速度是 68.7 倍,成本仅为 20%。
4.4 跳播机制下的 epoch 分布
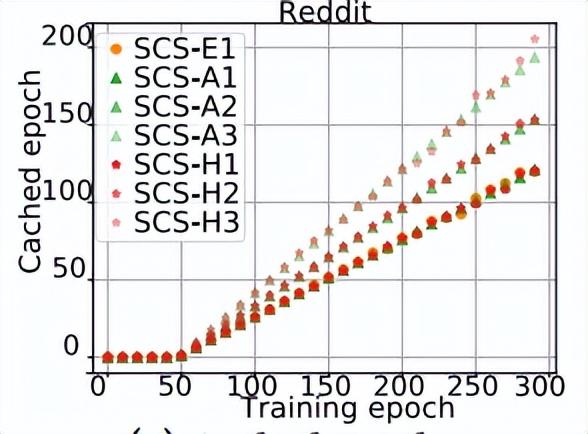
如图绘制了在 SANCUS 训练中实际执行广播的相应 epoch。图中 SCS-E1 每 2 个 epoch 就会广播最新结果。因此,橙色点表示的缓存 epoch 有规律地增加。对于自适应方案 SCS-A 和 SCS-H,通过观察点间间距的变化发现广播呈不规则模式,尤其是基于变化量的 SCS-H。
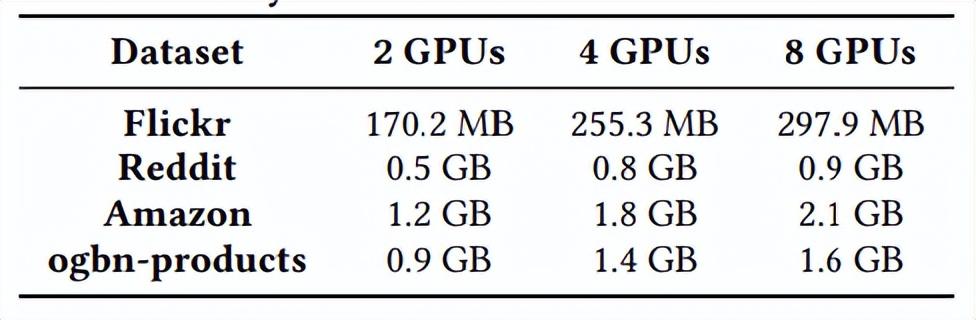
4.5 历史嵌入的缓存占用情况
在 SANCUS 训练过程中,GPU 内存占用分为三部分:本地数据(即嵌入、本地邻接矩阵和全权矩阵)、矩阵运算内存和历史嵌入缓存。与 CAGNET 相比,SANCUS 唯一额外消耗的是历史嵌入缓存。因此,下表说明了缓存占用情况。总的来说,对于现代 GPU 来说,缓存成本很低。
4.6 陈旧性度量的有效性分析和边界选择

如图 a 中的
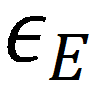
、图 b 中的

和图 c 和 d 中的
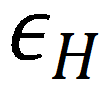
所示。随着陈旧度边界的增大,波动越大,收敛越不稳定,但避免通信越多。虽然收敛速度会有所下降,但由于跳播避免了大量通讯时间,总训练时间仍然更短。较大的陈旧度边界有助于提高吞吐量,但会对准确性产生负面影响。在实际应用中,可根据场景需求,结合收敛速度、通信避免量、准确率来相应调整
、
和
。虽然这仍是一个开放研究问题,但从结果可以得出,
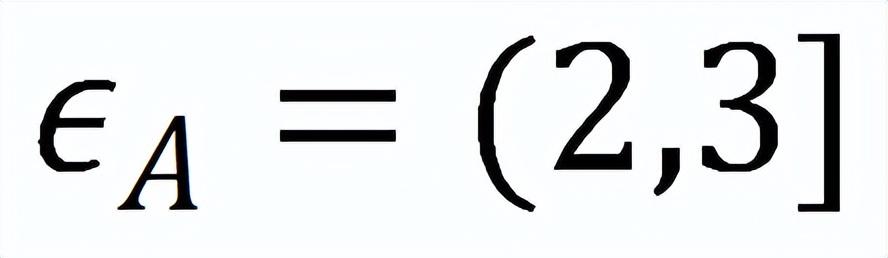
和

的自适应策略在所有试验数据集和系统配置中均可达到合理的平衡。
五、总结
本论文提出了一个分布式图神经网络训练系统 SANCUS。这是第一个主动的利用嵌入陈旧性感知制造异步性以避免通信的去中心化图神经网络系统,可以在提高训练效率的同时保持模型性能。作者提出了一组新颖的有界嵌入陈旧性度量指标:epoch 固定的陈旧性、epoch 自适应的陈旧性和基于方差变化的 epoch 自适应陈旧性;并将历史嵌入缓存和有界嵌入陈旧性检查应用到去中心化的图神经网络中,以自适应地跳过计算节点之间的数据广播。在大规模基准图数据集的大量实验结果验证了 SANCUS 的高效性和有效性,以及从传统分布式机器学习中被动解决梯度陈旧性到 SANCUS 中主动基于历史嵌入陈旧性与其自适应管理策略的必要性。更多的技术细节和实验可以阅读原论文:https://www.vldb.org/pvldb/vol15/p1937-peng.pdf。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

