

#tjhttp 二、《图解HTTP》- HTTP协议历史发展(重点)
知识点
- 请求和响应报文的结构。
- HTTP协议进化历史,介绍不同HTTP版本从无到有的重大特性改变。(重点)
- HTTP几个比较常见的问题讨论。
2.0 介绍
这一章节基本上大部分为个人扩展,因为书中的内容讲的实在是比较浅。本文内容非常长,另外哪怕这么长也只是讲到了HTTP协议的一部分而已,HTTP协议本身十分复杂。
2.1 请求和响应报文结构
请求报文的基本内容:
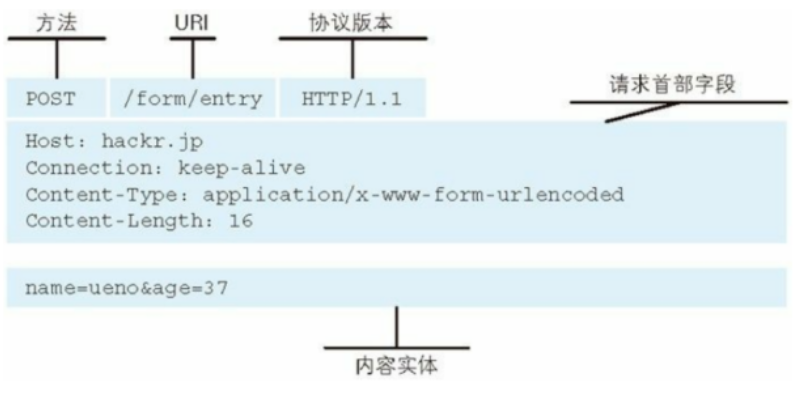
请求内容需要客户端发给服务端:
GET /index.htm HTTP/1.1
Host: hackr.jp响应报文的基本内容:

服务器按照请求内容处理结果返回:
开头部分是HTTP协议版本,紧接着是状态码 200 以及原因短语。
HTTP/1.1 200 OK
Date: Tue, 10 Jul 2012 06:50:15 GMT
Content-Length: 362
Content-Type: text/html
<html> ……2.2 HTTP进化历史
协议版本 |
解决的核心问题 |
解决方式 |
|---|---|---|
0.9 |
HTML 文件传输 |
确立了客户端请求、服务端响应的通信流程 |
1.0 |
不同类型文件传输 |
设立头部字段 |
1.1 |
创建/断开 TCP 连接开销大 |
建立长连接进行复用 |
2 |
并发数有限 |
二进制分帧 |
3 |
TCP 丢包阻塞 |
采用 UDP 协议 |
SPDY |
HTTP1.X的请求延迟 |
多路复用 |
2.2.1 概览
我们复盘HTTP的进化历史,下面是抛去所有细节,整个HTTP连接大致的进化路线。
- http0.9:只具备最基础的HTTP连接模型,在非常短的一段时间内存在,后面被快速完善。
- http1.0: 1.0版本中每个TCP连接只能发送一个请求,数据发送完毕连接就关闭,如果还要请求其他资源,就必须重新建立TCP连接。(TCP为了保证正确性和可靠性需要客户端和服务器三次握手和四次挥手,因此建立连接成本很高)
- http1.1:
- **长连接**:新增Connection字段,默认为keep-alive,保持连接不断开,即 TCP 连接默认不关闭,可以被多个请求复用;
- **管道化**:在同一个TCP连接中,客户端可以发送多个请求,但响应的顺序还是按照请求的顺序返回,在服务端只有处理完一个回应,才会进行下一个回应;
- **host字段**:Host字段用来指定服务器的域名,这样就可以将多种请求发往同一台服务器上的不同网站,提高了机器的复用,这个也是重要的优化;- **二进制格式**:1.x是文本协议,然而2.0是以二进制帧为基本单位,可以说是一个二进制协议,将所有传输的信息分割为消息和帧,并采用二进制格式的编码,一帧中包含数据和标识符,使得网络传输变得高效而灵活;
- **多路复用**:2.0版本的多路复用多个请求共用一个连接,多个请求可以同时在一个TCP连接上并发,主要借助于二进制帧中的标识进行区分实现链路的复用;
- **头部压缩**:2.0版本使用使用HPACK算法对头部header数据进行压缩,从而减少请求的大小提高效率,这个非常好理解,之前每次发送都要带相同的header,显得很冗余,2.0版本对头部信息进行增量更新有效减少了头部数据的传输;
- **服务端推送**:在2.0版本允许服务器主动向客户端发送资源,这样在客户端可以起到加速的作用;- HTTP/3:
这个版本是划时代的改变,在HTTP/3中,将**弃用**[**TCP**](https://zh.m.wikipedia.org/wiki/%E4%BC%A0%E8%BE%93%E6%8E%A7%E5%88%B6%E5%8D%8F%E8%AE%AE)**协议**,改为使用基于[UDP](https://zh.m.wikipedia.org/wiki/%E7%94%A8%E6%88%B7%E6%95%B0%E6%8D%AE%E6%8A%A5%E5%8D%8F%E8%AE%AE)协议的[QUIC](https://zh.m.wikipedia.org/wiki/%E5%BF%AB%E9%80%9FUDP%E7%BD%91%E7%BB%9C%E8%BF%9E%E6%8E%A5)协议实现。需要注意QUIC是谷歌提出的(和2.0 的SPDY 一样),QUIC指的是**快速 UDP Internet 连接**,既然使用了UDP,那么也意味着网络可能存在丢包和稳定性下降。谷歌当然不会让这样的事情发生,所以他们提出的QUIC既可以保证稳定性,又可以保证SSL的兼容,因为HTTP3上来就会和TLS1.3一起上线。基于这些原因,制定网络协议IETF的人马上基本都同意了QUIC的提案(太好了又能白嫖成果),于是HTTP3.0 就这样来了。但是这只是最基本的草案,后续的讨论中希望QUIC可以兼容其他的传输协议,最终的排序如下IP / UDP / QUIC / HTTP。另外TLS有一个细节优化是在进行连接的时候浏览器第一次就把自己的密钥交换的素材发给服务器,这样进一步缩短了交换的时间。-
队头阻塞,
HTTP/2多个请求跑在一个TCP连接中,如果此时序号较低的网络请求被阻塞,那么即使序列号较高的TCP段已经被接收了,应用层也无法从内核中读取到这部分数据,从 HTTP 视角看就是多个请求被阻塞了,并且页面也只是加载了一部分内容; -
TCP和TLS握手时延缩短:TCL三次握手和TLS四次握手,共有3-RTT的时延,HTPT/3最终压缩到1 RTT(难以想象有多快); -
连接迁移需要重新连接,移动设备从
4G网络环境切换到WIFI时,由于TCP是基于四元组来确认一条TCP连接的,那么网络环境变化后,就会导致IP地址或端口变化,于是TCP只能断开连接,然后再重新建立连接,切换网络环境的成本高;
RTT:RTT是Round Trip Time的缩写,简单来说就是通信一来一回的时间。
下面是官方对于RTT速度缩短的对比,最终只在初次连接需要1RTT的密钥交换,之后的连接均为0RTT!

2.2.2 HTTP 0.9
这个版本基本就是草稿纸协议,但是它具备了HTTP最原始的基础模型,比如只有GET命令,没有 Header 信息,传达的目的地也十分简单,没有多重数据格式,只有最简单的文本。
此外服务器一次建立发送请求内容之后就会立马关闭TCP连接,这时候的版本一个TCP还只能发送一个HTTP请求,采用一应一答的方式。
2.2.3 HTTP 1.0
协议原文:https://datatracker.ietf.org/doc/html/rfc1945
显然HTTP 0.9缺陷非常多并且不能满足网络传输要求。浏览器现在需要传输更为复杂的图片,脚本,音频视频数据。
1996年HTTP进行了一次大升级,主要的更新如下:
在HTTP1.0 协议原文中开头有一句话:
原文:
Status of This Memo:
This memo provides information for the Internet community. This memo
does not specify an Internet standard of any kind. distribution of
this memo is unlimited.这份协议用了memo这个单词,memo 的意思是备忘录,也就是说虽然洋洋洒洒写了一大堆看似类似标准的规定,但是实际上还是草稿,没有规定任何的协议和标准,另外这份协议是在麻省理工的一个分校起草的,所以可以认为是讨论之后临时的一份方案。
HTTP1.0主要改动点介绍
在了解了这是一份备忘录的前提下,我们来介绍协议的一些重要概念提出。
HTTP1.0 定义了无状态、无连接的应用层协议,纸面化定义了HTTP协议本身。
无状态、无连接定义:HTTP1.0 规定服务器和客户端之间可以保持短暂连接,每次请求都需要发起一次新的TCP连接(无连接),连接完成之后立马断开连接,同时服务器不负责记录过去的请求(无状态)。
这样就出现一个问题,那就是通常一次访问需要多个HTTP请求,所以每一次请求都要建立一次TCP连接效率非常低,此外还存在两个比较严重的问题:队头阻塞和无法复用连接。
队头阻塞:因为TCP连接是类似排队的方式发送,如果前一个请求没有到达或者丢失,后一个请求就需要等待前面的请求完成或者完成重传才能进行请求。
无法复用连接:TCO连接资源本身就是有限的,同时因为TCP自身调节(滑动窗口)的关系,TCP为了防止网络拥堵会有一个慢启动的过程。
RTT时间计算:TCP三次握手共计需要至少1.5个RTT,注意是HTTP连接不是HTTPS连接。
滑动窗口:简单理解是TCP 提供一种可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量的机制。
2.2.4 HTTP1.1
HTTP 1.1 的升级改动较大,主要的改动点是解决建立连接和传输数据的问题,在HTTP1.1中引入了下面的内容进行改进:
- 长连接:也就是
Keep-alive头部字段,让TCP默认不进行关闭,保证一个TCP可以传递多个HTTP请求 - 并发连接:一个域名允许指定多个长连接(注意如果超出上限依然阻塞);
- 管道机制:一个TCP可以同时发送多个请求(但是实际效果很鸡肋还会增加服务器压力,所以通常被禁用);
- 增加更多方法:PUT、DELETE、OPTIONS、PATCH等;
- HTTP1.0新增缓存字段(If-Modified-Since, if-none-match),而HTTP1.1则引入了更多字段,比如
Entity tag,If-Unmodified-Since, If-Match, if-none-match等更多缓存头部的缓存策略。 - 允许数据分块传输(Chunked),对于大数据传输很重要;
- 强制使用Host头部,为互联网的主机托管创造条件;
- 请求头中引入了 支持断点续传的
range字段;
下面为书中第二章节记录的笔记内容,写书日期是HTTP1.1蓬勃发展的时候 ,基本对应了HTTP1.1协议中的一些显著特点。
无状态协议
HTTP 协议自身不具备保存之前发送过的请求或响应的功能,换句话说HTTP协议本身只保证协议报文的格式符合HTTP的要求,除此之外的传输和网络通信其实都是需要依赖更下层的协议完成。
HTTP设计成如此简单的形式,本质上就是除开协议本身外的内容一切都不考虑,达到高速传输的效果。但是因为HTTP的简单粗暴,协议本身需要很多辅助的组件来完成WEB的各种访问效果,比如保持登陆状态,保存近期的浏览器访问信息,记忆密码等功能,这些都需要Cookie以及Session来完成。
HTTP/1.1引入了Cookie以及Session协助HTTP完成状态存储等操作。
请求资源定位
HTTP大多数时候是通过URL的域名来访问资源的,定位URL要访问的真实服务需要DNS的配合,DNS是什么这里不再赘述。
如果是对服务器访问请求,可以通过
*的方式发起请求,比如OPTIONS * HTTP/1.1。
请求方法
实际上用的比较多的还是GET和POST。
GET:通常视为无需要服务端校验可以直接通过URL公开访问的资源,但是通常会在URL中携带大量的请求参数,但是这些参数通常无关敏感信息所以放在URL当中非常方便简单。
POST:通常情况为表单提交的参数,需要服务端的拦截校验才能获取,比如下载文件或者访问一些敏感资源,实际上POST请求要比GET请求使用更为频繁,因为POST请求对于请求的数据进行“加密”保护。相比于GET请求要安全和靠谱很多。
持久连接
所谓的持久连接包含一定的历史原因,HTTP1.0最早期每次访问和响应都是一些非常小的资源交互,所以一次请求结束之后基本就可以和服务端断开,等到下一次需要再次请求再次连接。
但是随着互联网发展,资源包越来越大,对于互联网的需求和挑战也越来越大。
在后续 HTTP/1.1 中所有的连接默认都是持久连接,目的是减少客户端和服务端的频繁请求连接和响应。
管道化
注意HTTP真正意义上的全双工的协议是在HTTP/2才实现的,实现的核心是多路复用。
管道化可以看做是为了让半双工的HTTP1.1也能支持全双工协议的一种强化,通俗的话说就是围魏救赵。
全双工协议:指的是HTTP连接的两端不需要等待响应数据给对方就可以直接发送请求给对方,实现同一时间内同时处理多个请求和响应的功能。
HTTP/1.1允许多个http请求通过一个套接字同时被输出 ,而不用等待相应的响应(这里提示一下管道化同样需要连接双方都支持才能完成)。
需要注意这里本质上是在一个TCP请求封装了多次请求然后直接丢给服务端去处理,客户端接下来可以干别的事情,要么等待服务端慢慢等待,要么自己去访问别的资源。
客户端通过FIFO队列把多个TCP请求封装成一个发给了服务端,服务端虽然可以通过处理FIFO队列的多个请求,但是必须等所有请求完成再按照FIFO发送的顺序挨个响应回去,也就是说其实并没有根本上解决堵塞问题。
管道化的技术虽然很方便,但是限制和规矩比好处要多得多,并且有点脱裤子放屁的意思。结果是并没有十分普及也没有多少服务端使用,多数的HTTP请求也会禁用管道化防止服务端请求堵塞迟迟不进行响应。
管道化小结
- 实际上管道化可以看做原本阻塞在客户端一条条处理的请求,变为阻塞在服务端的一条条请求。
- 管道化请求通常是GET和HEAD请求,POST和PUT不需要管道化, 管道化只能利用已存在的
keep-alive连接。 - 管道化是HTTP1.1协议下,服务器不能很好处理并行请求的改进,但是这个方案不理想,围魏救赵失败并且最终被各大浏览器禁用掉。
- FIFO队列的有序和TCP 的有序性区别可以简单认为是强一致性和弱一致性的区别。FIFO队列有序性指的是请求和响应必须按照队列发送的规则完全一样,而TCP仅仅是保证了发送和响应的大致逻辑顺序,真实的情况和描述的情况可能不一致。
- 因为管道是把累赘丢给了服务端,从客户端的角度来看自己完成了全双工的通信。实际上这只是伪全双工通信。
Cookie
Cookie的内容不是本书重点,如果需要了解相关知识可以直接往上查询资料了解,基本一抓一大把。
2.2.5 HTTP/2
HTTP2的协议改动比较大,从整体上来看主要是下面一些重要调整:
- SPDY:这个概念是谷歌提出的,起初是希望作为一个独立协议,但是最终SPDY的相关技术人员参与到了HTTP/2,所以谷歌浏览器后面全面支持HTTP/2放弃了SPDY单独成为协议的想法,对于SPDY,具有如下的改进点:
- HTTP Speed + mobility:微软提出改善移动端通信的速度和性能标准,它建立在 Google 公司提出的 SPDY与 WebSocket 的基础之上。
- Network-Friendly HTTP Upgrade:移动端通信时改善 HTTP 性能。
从三者的影响力来看,显然是Google的影响力是最大的,从HTTP3.0开始以谷歌发起可以看出HTTP协议的标准制定现在基本就是谷歌说了算。
接着我们就来看看最重要SPDY,谷歌是一个极客公司,SPDY可以看做是HTTP1.1和HTTP/2正式发布之间谷歌弄出来的一个提高HTTP协议传输效率的“玩具” ,重点优化了HTTP1.X的请求延迟问题,以及解决HTTP1.X的安全性问题:
- 降低延迟(多路复用):使用多路复用来降低高延迟的问题,多路复用指的是使用Stream让多个请求可以共享一个TCP连接,解决HOL Blocking(head of line blocking)(队头阻塞)的问题,同时提升带宽利用率。
- 服务端推送:HTTP1.X的推送都是半双工,所以在2.0是实现真正的服务端发起请求的全双工,另外在WebSocket在这全双工一块大放异彩。
- 请求优先级:针对引入多路复用的一个兜底方案,多路复用使用多个Stream的时候容易单请求阻塞问题。也就是前文所说的和管道连接一样的问题,SPDY通过设置优先级的方式让重要请求优先处理,比如页面的内容应该先进行展示,之后再加载CSS文件美化以及加载脚本互动等等,实际减少用户不会在等待过程中关闭页面的几率。
- Header压缩:HTTP1.X的header很多时候都是多余的,所以2.0 会自动选择合适的压缩算法自动压缩请求加快请求和响应速度。
- 基于HTTPS的加密协议传输:HTTP1.X 本身是不会加入SSL加密的,而2.0 让HTTP自带SSL,从而提高传输可靠和稳定性。
这些内容在后续大部分都被HTTP/2 采纳,下面就来看看HTTP/2具体的实施细节。
HTTP/2具体实施(重点)
当然这一部分也只讲到了协议中一些重点的升级内容,详细内容请参考“参考资料”或点击HTTP/2的标题。
二进制帧(Stream)
HTTP/2 使用流(二进制)替代 ASCII 编码传输提升传输效率,客户端发送的请求都会封装为带有编号的二进制帧,然后再发送给服务端处理。
HTTP/2 通过 一个TCP连接完成多次请求操作,服务端接受流数据并且检查编号将其合并为一个完整的请求内容,这样同样需要按照二进制帧的拆分规则拆分响应。像这样利用二进制分帧 的方式切分数据,客户端和服务端只需要一个请求就可以完成通信,也就是SPDY提到的多个Stream 合并到一个TCP连接中完成。
二进制分帧把数据切分成更小的消息和帧,采用了二进制的格式进行编码,在HTTP1.1 当中首部消息封装到Headers当中,然后把Request body 封装到 Data帧。
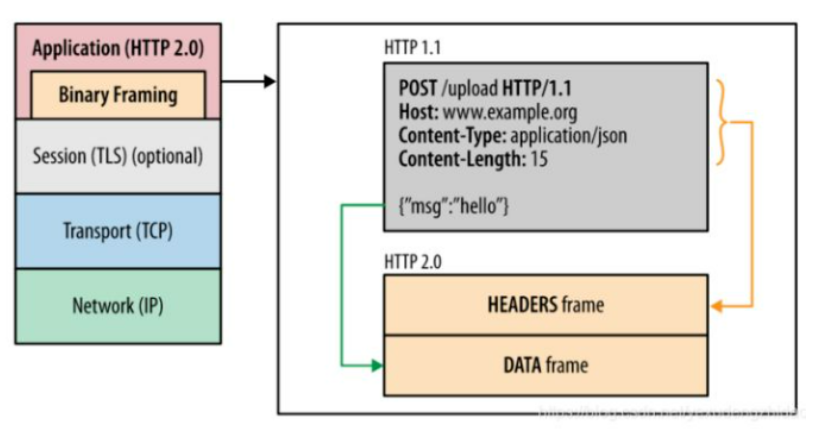
使用二进制分帧目的是向前兼容,需要在应用层和传输层之间加一层二进制分帧层,让HTTP1.X 协议更加简单的升级同时不会对过去的协议产生冲突 。
帧、消息、Stream之间的关系
- 帧:可以认为是流当中的最小单位。
- 消息:表示HTTP1.X中的一次请求。
- Stream:包含1条或者多条message。
二进制分帧结构
二进制分帧结构主要包含了头部帧和数据帧两个部分,头部在帧数只有9个字节,注意R属于标志位保留。所以整个算下来是:
3个字节帧长度+1个字节帧类型 + 31bit流标识符、1bit未使用标志位 构成。
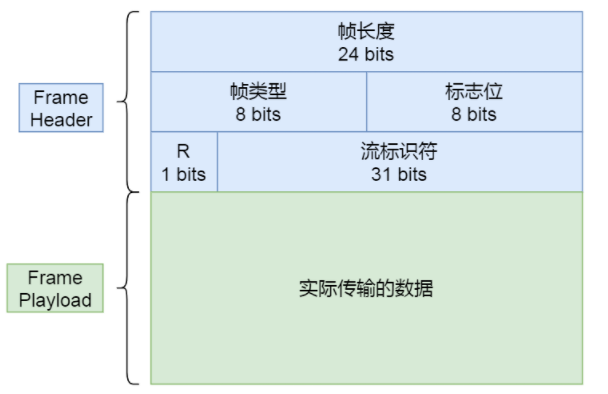
帧长度:数据帧长度,24位的3字节大小,取值为 2^14(16384) - 2^24(1677215)之间,接收方的 SETTINGS_MAS_FRAM_SIZE 设置。
帧类型:分辨数据帧还是控制帧。
标志位:携带简单控制信息,标志位表示流的优先级。
流标识符:表示帧属于哪一个流的,上限为2的31次方,接收方需要根据流标识的ID组装还原报文,同一个Stream的消息必须是有序的。此外客户端和服务端分别用奇数和偶数标识流,并发流使用了标识才可以应用多路复用。
R:1位保留标志位,暂未定义,0x0为结尾。
帧数据:实际传输内容由帧类型指定。
如果想要知道更多细节,可以参考“参考资料”部分的官方介绍以及结合WireShark抓包使用,本读书笔记没法面面俱到和深入
最后是补充帧类型的具体内容,帧类型定义了10种类型的帧数:
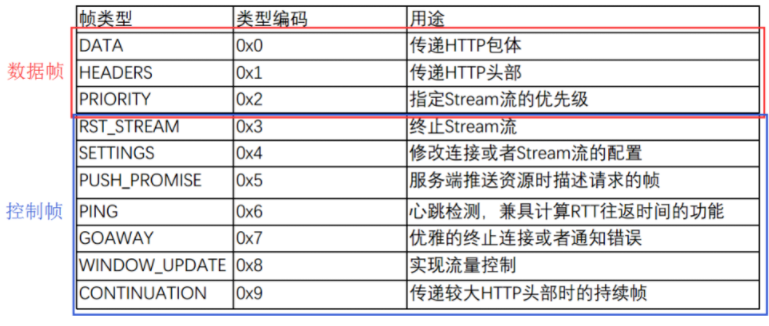
多路复用 (Multiplexing)
有了前面二进制帧结构的铺垫,现在再来看看多路复用是怎么回事,这里首先需要说明在过去的HTTP1.1中存在的问题:
同一时间同一域名的请求存在访问限制,超过限制的请求会自动阻塞。
在传统的解决方案中是利用多域名访问以及服务器分发的方式让资源到特定服务器加载,让整个页面的响应速度提升。比如利用多个域名的CDN进行访问加速
随着HTTP/2的更新,HTTP2改用了二进制帧作为替代方案,允许单一的HTTP2请求复用多个请求和响应内容,也就是说可以一个包里面打包很多份“外卖”一起给你送过来。
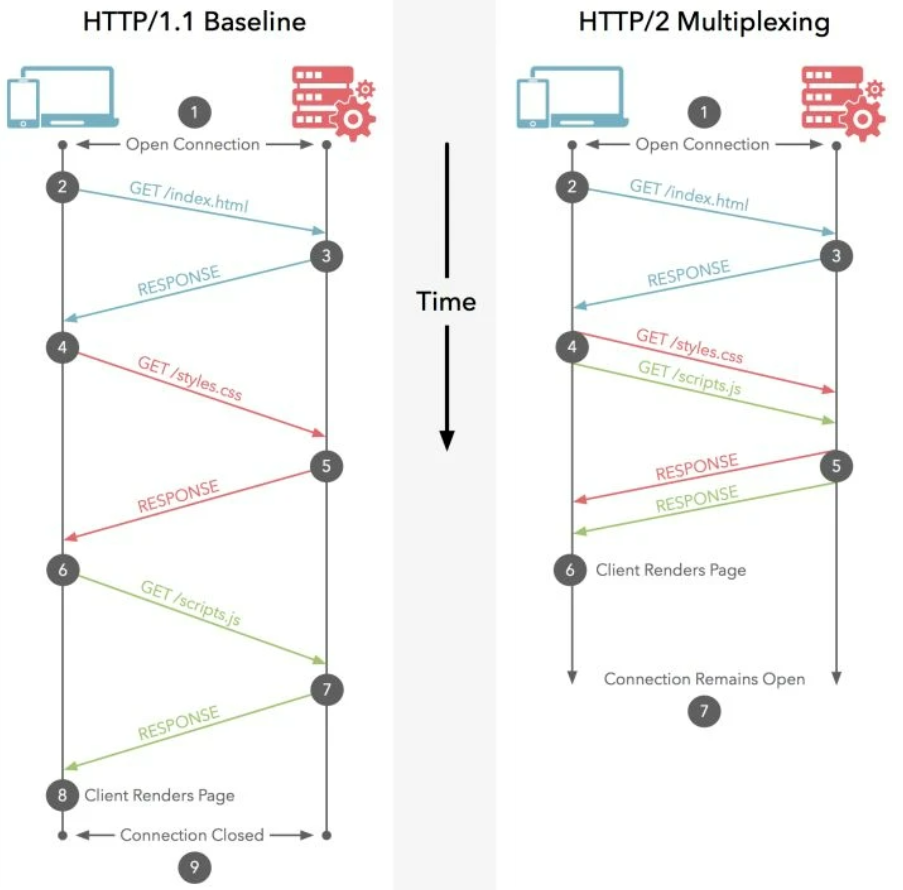
此外,流控制数据也意味着可以支持多流并行而不过多依赖TCP,因为通信缩小为一个个帧,帧内部对应了一个个消息,可以实现并行的交换消息。
Header压缩(Header Compression)
HTTP1.X 不支持Header压缩,如果页面非常多的去看下会导致带宽消耗和不必要的浪费。
针对这个问题在SPDY中 的解决方案是利用DEFLATE 格式的字段,这种设计非常有效,但是实际上存在CRIME信息泄露的攻击手段。
在HTTP/2 当中定义了HPACK,HPACK算法通过静态的哈夫曼编码对于请求头部进行编码减少传输大小,但是需要让客户端和服务端之间维护首部表,首部表可以维护和存储之前发过的键值对信息,对于重复发送的报文内容可以直接通过查表获取,减少冗余数据产生,后续的第二个请求将会发送不重复的数据。
HPACK压缩算法主要包含两个模块,索引表和哈夫曼编码,索引表同时分为动态表和静态表,静态表内部预定义了61个Header的K/V 数值,而动态表是先进先出的队列,初始情况下内容为空,而解压header则需要每次添加的时候放到队头,移除从队尾开始。
注意动态表为了防止过度膨胀占用内存导致客户端崩溃,在超过一定长度过后会自动释放HTTP/2请求。
HPACK算法
HPACK算法是对于哈夫曼算法的一种应用和改进,哈夫曼算法经典案例是就是ZIP压缩,也就是虽然我们可能不清楚却是可能天天在用的一个东西。
HPACK算法的思路是在客户端和服务端两边各维护一个哈希表,然后双端通过表中缓存Headers字段减少流中二进制数据传输,进而提高传输效率。
HPACK三个主要组件有如下细节:
- 静态表:HTTP2为出现在头部的字符串和字段静态表,包含61个基本的headers内容,
- 动态表:静态表只有61个字段,所以利用动态表存储不在静态表的字段,从62开始进行索引,在传输没有出现的字段时候,首先对于建立索引号,然后字符串需要经过哈夫曼编码完成二进制转化发给服务器,如果是第二次发送则找到对应的动态表的索引找到即可,这样有效避免一些冗余数据的传输。
- 哈夫曼编码:这一算法非常重要,对于近代互联网的发展有着重大影响。
哈夫曼编码:是一种用于无损数据压缩的熵编码(权编码)算法。由美国计算机科学家大卫·霍夫曼(David Albert Huffman)在1952年发明。 霍夫曼在1952年提出了最优二叉树的构造方法,也就是构造最优二元前缀编码的方法,所以最优二叉树也别叫做霍夫曼树,对应最优二元前缀码也叫做霍夫曼编码。
下面为哈夫曼编码对应的原始论文:
哈夫曼编码原始论文:
链接:https://pan.baidu.com/s/1r_yOVytVXb-zlfZ6csUb2A?pwd=694k 提取码:694k
此外这里有个讲的比较通俗的霍夫曼的视频,强烈建议反复观看,能帮你快速了解哈夫曼编码是怎么回事,当然前提是得会使用魔法。
https://www.youtube.com/watch?v=Jrje7ep5Ff8&t=29s
请求优先级
请求优先级实际上并不是HTTP/2才出现的,在此之前的的RFC7540中定义了一套优先级的相关指令,但是由于它过于复杂最后并没被普及,但是里面的信息依然是值得参考的。
HTTP/2的内容取消了所有关于RFC7540优先级的指令,所有的描述被删除并且被保留在原本的协议当中。
HTTP/2利用多路复用,所以有必要优先使用重要的资源分配到前面优先加载,但是实际上在实现方案过程中优先级是不均衡的,许多服务器实际上并不会观察客户端的请求和行为。
最后还有根本性的缺点,也就是TCP层是无法并行的,在单个请求当中的使用优先级甚至有可能性能弱于HTTP1.X。
流量控制
所谓流量控制就是数据流之间的竞争问题,需要注意HTTP2只有流数据才会进行控制,通过使用WINDOW_UPDATE帧来提供流量控制。
注意长度不是4个八位字节的window_update 帧需要视为 frame_size_error的错误进行响应。
PS:下面的设计中有效载荷是保留位+ 31位的无符号整数,表示除了现在已经有的流控制窗口之外还能额外传输8个字节数的数据,所以最终合法范围是
1到 2^31 - 1 (2,147,483,647)个八位字节。
WINDOW_UPDATE Frame {
Length (24) = 0x04,
Type (8) = 0x08,
Unused Flags (8),
Reserved (1),
Stream Identifier (31),
Reserved (1),
Window Size Increment (31),
}对于流量控制,存在下面几个显著特征:
- 流量控制需要基于HTTP中间的各种代理服务器控制,不是非端到端的控制;
- 基于信用基础公布每个流在每个连接上接收了多少字节,WINDOW_UPDATE 框架没有定义任何标志,并没有强制规定;
- 流量的控制存在方向概念,接收方负责流量控制,并且可以设置每一个流窗口的大小;
-
WINDOW_UPDATE可以对于已设置了END_STREAM标志的帧进行发送,表示接收方这时候有可能进入了半关闭或者已经关闭的状态接收到WINDOW_UPDATE帧,但是接收者不能视作错误对待; - 接收者必须将接收到流控制窗口增量为 0 的
WINDOW_UPDATE帧视为PROTOCOL_ERROR类型的流错误 ;
服务器推送
服务器推送意图解决HTTP1.X中请求总是从客户端发起的弊端,服务端推送的目的是更少客户端的等待以及延迟。但是实际上服务端推送很难应用,因为这意味着要预测用户的行为。服务端推送包含推送请求和推送响应的部分。
推送请求
推送请求使用PUSH_PROMISE 帧作为发送,这个帧包含字段块,控制信息和完整的请求头字段,但是不能携带包含消息内容的相关信息,因为是指定的帧结构,所以客户端也需要显式的和服务端进行关联,所以服务端推送 请求也叫做“Promised requests”。
当请求客户端接收之后是传送CONTINUATION帧,CONTINUATION帧头字段必须是一组有效的请求头字段,服务器必须通过":method"伪字段头部添加安全可缓存的方法,如果客户端收到的缓存方法不安全则需要在PUSH_PROMISE帧上响应错误,这样的设计有点类似两个特务对暗号,一个暗号对错了就得立马把对方弊了。
PUSH_PROMISE可以在任意的客户端和服务端进行传输,但是有个前提是流对于服务器需要保证“半关闭“或者“打开“的状态,否则不允许通过CONTINUATION或者HEADERS 字段块传输。
PUSH_PROMISE帧只能通过服务端发起,因为专为服务端推送设计,使用客户端推送是“不合法“的。
PUSH_PROMISE 帧结构:
再次强调有效载荷是一个保留位+ 31位的无符号整数。有效载荷是什么?是对于HTTP1.1协议中实体的术语重新定义,可以简单看做是报文的请求Body。
下面是对应源代码定义:
`PUSH_PROMISE`帧定义PUSH_PROMISE Frame {
Length (24),
Type (8) = 0x05,
Unused Flags (4),
PADDED Flag (1),
END_HEADERS Flag (1),
Unused Flags (2),
Reserved (1),
Stream Identifier (31),
[Pad Length (8)],
Reserved (1),
Promised Stream ID (31),
Field Block Fragment (..),
Padding (..2040),
}`CONTINUATION` 帧:用于请求接通之后继续传输,注意这个帧不是专用于服务端推送的。CONTINUATION Frame {
Length (24),
Type (8) = 0x09,
Unused Flags (5),
END_HEADERS Flag (1),
Unused Flags (2),
Reserved (1),
Stream Identifier (31),
Field Block Fragment (..),
}推送响应
如果客户端不想接受请求或者服务器发起请求的时间过长,可以通过RST_STREAM 帧代码标识发送CANCEL 或者REFUSED_STREAM 内容告诉服务器自己不接受服务端请求推送。
而如果客户端需要接收这些响应信息,则需要按照之前所说传递CONTINUATION以及PUSH_PROMISE接收服务端请求。
其他特点:
- 客户端可以使用SETTINGS_MAX_CONCURRENT_STREAMS设置来限制服务器可以同时推送的响应数量。
- 如果客户端不想要接收服务端的推送流,可以把SETTINGS_MAX_CONCURRENT_STREAMS设置为0或者重置
PUSH_PROMISE保留流进行处理。
2.2.6 HTTP/3
进度追踪:RFC 9114 - HTTP/3 (ietf.org)
为什么会存在3?
可以发现HTTP/2虽然有了质的飞跃,但是因为TCP协议本身的缺陷,队头阻塞的问题依然可能存在,同时一旦出现网络拥堵会比HTTP1.X情况更为严重(用户只能看到一个白板)。
所以后续谷歌的研究方向转为研究QUIC,实际上就是改良UDP协议来解决TCP协议自身存在的问题。但是现在看来这种改良不是很完美,目前国内部分厂商对于QUIC进行自己的改进。
HTTP/3 为什么选择UDP
这就引出另一个问题,为什么3.0有很多协议可以选择,为什么使用UDP?通常有下面的几个点:
- 基于TCP 协议的设备很多,兼容十分困难。
- TCP是Linux内部的重要组成,修改非常麻烦,或者说压根不敢动。
- UDP本身无连接的,没有建立连接和断连的成本。
- UDP数据包本身就不保证稳定传输所以不存在阻塞问题(属于爱要不要)。
- UDP改造相对其他协议改造成本低很多
HTTP/3 新特性
- QUIC(无队头阻塞):优化多路复用,使用QUIC协议代替TCP协议解决队头阻塞问题,QUIC也是基于流设计但是不同的是一个流丢包只会影响这一条流的数据重传,TCP 基于IP和端口进行连接,多变的移动网络环境之下十分麻烦,QUIC通过ID识别连接,只要ID不变,网络环境变化是可以迅速继续连接的。
- 0RTT:注意建立连接的0TT在HTTP/3上目前依然没有实现,至少需要1RTT。
RTT:RTT是Round Trip Time的缩写,简单来说就是通信一来一回的时间。 RTT包含三部分:
往返传播延迟。 网络设备排队延迟。 应用程序处理延迟。
HTTPS建立完整连接通常需要TCP握手和TLS握手,至少要2-3个RTT,普通的HTTP也至少要1个RTT。QUIC的目的是除开初次连接需要消耗1RTT时间之外,其他的连接可以实现0RTT。
为什么无法做到初次交互0RTT? 因为初次传输说白了依然需要传输两边到密钥信息,因为存在数据传输所以依然需要1个RTT的时间完成动作,但是在完成握手之后的数据传输只需要0RTT的时间。
具体要怎么做呢?例如3个包丢失一个包,可以通过其他数据包(实际上是校验包)异或值计算出丢失包的“编号”然后进行重传,但是这种异或操作**只能针对一个数据包丢失**计算,如果多个包丢失,用异或值是无法算出一个以上的包的,所以这时候还是需要重传(但是QUIC重传代价比TCP的重传低很多)。- 连接迁移:QUIC放弃了TCP的五元组概念,使用了64位的随机数ID充当连接ID,QUIC 协议在切换网络环境的时候只要ID一致就可以立马重连。对于现代社会经常wifi和手机流量切换的情况十分好用的一次改进。
术语解释⚠️:
5元组:是一个通信术语,英文名称为five-tuple,或5-tuple,通常指由源Ip (source IP), 源端口(source port),目标Ip (destination IP), 目标端口(destination port),4层通信协议 (the layer 4 protocol)等5个字段来表示一个会话,是会话哦。 这个概念在《网络是怎么样连接的》这本书中也有提到类似的概念。那就是在第一章中创建套接字的步骤,创建套接字实际上就需要用到这个五元祖的概念,因为要创建“通道”需要双方给自告知自己的信息给对方自己的IP和端口,这样才能完成通道创建和后续的协议通信。
4元组:即用4个维度来确定唯一连接,这4个维度分别是源Ip (source IP), 源端口(source port),目标Ip (destination IP), 目标端口(destination port)。
7元组:即用7个字段来确定网络流量,即源Ip (source IP), 源端口(source port),目标Ip (destination IP), 目标端口(destination port),4层通信协议 (the layer 4 protocol),服务类型(ToS byte),接口索引(Input logical interface (ifIndex))
- 加密认证的报文:
QUIC默认会对于报文头部加密,因为TCP头部公开传输,这项改进非常重要。 - 流量控制,传输可靠性:
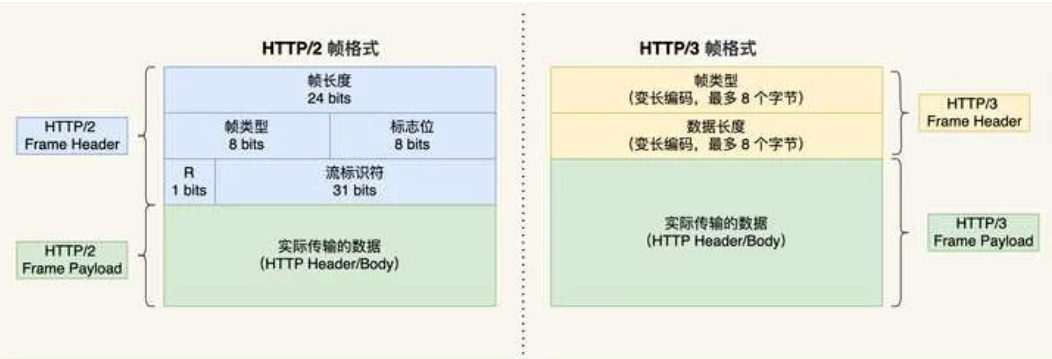
QUIC在UDP协议上加了一层数据可靠传输的可靠性传输,因此流量控制和传输可靠性都可以得到保证。 - 帧格式变化
下面是网上资料对比HTTP2和3之间的格式差距,可以发现HTTP/3 帧头只有两个字段:类型和长度。帧类型用来区分数据帧和控制帧,这一点是继承自HTTP/2的变化,数据帧包含HEADERS帧,DATA帧,Http包体。
- 关于2.0的头部压缩算法升级成了
QPACK算法:需要注意HTTP3的QPACK算法与HTTP/2中的HPACK编码方式相似,HTTP/3中的QPACK也采用了静态表、动态表及Huffman编码。
那么相对于之前的算法HPACK, QPACK算法有什么升级呢?首先HTTP/2 中的 HPACK 的静态表只有 61 项,而 HTTP/3 中的 QPACK 的静态表扩大到 91 项。
最大的区别是对于动态表做了优化,因为在HTTP2.0中动态表存在时序性的问题。
所谓时序性问题是在传输的时候如果出现丢包,此时一端的动态表做了改动,但是另一端是没改变的,同样需要把编码重传,这也意味着整个请求都会阻塞掉。

因此HTTP3使用UDP的高速,同时保持QUIC的稳定性,并且没有忘记TLS的安全性,在2018年的YTB直播中宣布QUIC作为HTTP3的标准。
YTB 地址:(2) IETF103-HTTPBIS-20181108-0900 - YouTube,可怜互联网的天花板协议制定团队IETF连1万粉丝都没有。

2.3 HTTP部分问题讨论
2.3.1 队头阻塞问题(head of line blocking)
队头阻塞问题不仅仅只是处在HTTP的问题,实际上更加底层的协议以及网络设备通信也会存在线头阻塞问题。
交换机
当交换机使用FIFO队列作为缓冲端口的缓冲区的时候,按照先进先出的原则,每次都只能是最旧的网络包被发送,这时候如果交换机输出端口存在阻塞,则会发生网络包等待进而造成网络延迟问题。
但是哪怕没有队头阻塞,FIFO队列缓冲区本身也会卡住新的网络包,在旧的网络包后面排队发送,所以这是FIFO队列本身带来的问题。
有点类似核酸排队,前面的人不做完后面的人做不了,但是前面的人一直不做,后面也只能等着。
交换机HO问题解决方案
使用虚拟输出队列的解决方案,这种方案的思路是只有在输入缓冲区的网络包才会出现HOL阻塞,带宽足够的时候不需要经过缓冲区直接输出,这样就避免HOL阻塞问题。
无输入缓冲的架构在中小型的交换机比较常见。
线头阻塞问题演示
交换机:交换机根据 MAC 地址表查找 MAC 地址, 然后将信号发送到相应的端口一个网络信号转接设备,有点类似电话局中转站。
线头阻塞示例:第 1 和第 3 个输入流竞争时,将数据包发送到同一输出接口,在这种情况下如果交换结构决定从第 3 个输入流传输数据包,则无法在同一时隙中处理第 1 个输入流。
请注意,第一个输入流阻塞了输出接口 3 的数据包,该数据包可用于处理。
无序传输:
因为TCP不保证网络包的传输顺序,所以可能会导致乱序传输,HOL阻塞会显著的增加数据包重新排序问题。
同样为了保证有损网络可靠消息传输,原子广播算法虽然解决这个问题,但是本身也会产生HOL阻塞问题,同样是由于无序传输带来的通病。
Bimodal Multicast 算法是一种使用 gossip 协议的随机算法,通过允许乱序接收某些消息来避免线头阻塞。
HTTP线头阻塞
HTTP 在 2.0 通过多路复用的方式解决了HTTP协议的弱点并且真正意义上消除应用层HOL阻塞问题,但是TCP协议层的无序传输依然是无法解决的。
于是在3.0中直接更换TCP协议为 QUIC 协议消除传输层的HOL阻塞问题。
2.4.2 HTTP/2 全双工支持
注意HTTP直到2.0才是真正意义上的全双工,所谓的HTTP支持全双工是混淆了TCP协议来讲的,因为TCP是支持全双工的,TCP可以利用网卡同时收发数据。
为了搞清楚TCP和HTTP全双工的概念, 应该理解HTTP中双工的两种模式:半双工(http 1.0/1.1),全双工(http 2.0)。
半双工:同一时间内链接上只能有一方发送数据而另一方接受数据。
- http 1.0 是短连接模式,每个请求都要建立新的 tcp 连接,一次请求响应之后直接断开,下一个请求重复此步骤。
- http 1.1 是长连接模式,可以多路复用,建立 tcp 连接不会立刻断开,资源1 发送响应,资源2 发送响应,资源3 发送响应,免去了要为每个资源都建立一次 tcp 的开销。
全双工:同一时间内两端都可以发送或接受数据 。
- http 2.0 资源1客户端发送请求不必等待响应就可以继续发送资源2 的请求,最终实现一边发,一边收。
2.4.3 HTTP 2.0 缺点
- 解决了HTTP的队头请求阻塞问题,但是没有解决TC P协议的队头请求阻塞问题,此外HTTP/2需要同时使用TLS握手和 HTTP握手耗时,同时在HTTPS连接建立之上需要使用TLS进行传输。
- HTTP/2的队头阻塞出现在当TCP出现丢包的时候,因为所有的请求被放到一个包当中,所以需要重传,TCP 此时会阻塞所有的请求。但是如果是HTTP1.X,那么至少是多个TCP连接效率还要高一些,
- 多路复用会增大服务器压力,因为没有请求数量限制,短时间大量请求会瞬间增大服务器压力
- 多路复用容易超时,因为多路复用无法鉴定带宽以及服务器能否承受多少请求。
丢包不如HTTP1.X
丢包的时候出现的情况是HTT P2.0因为请求帧都在一个TCP连接,意味着所有的请求全部要跟着TCP阻塞,在以前使用多个TCP连接来完成数据交互,其中一个阻塞其他请求依然可以正常抵达反而效率高。
二进制分帧目的
根本目的其实是为了让更加有效的利用TCP底层协议,使用二进制传输进一步减少数据在不同通信层的转化开销。
HTTP1.X的Keep-alive缺点
2.4.4 HTTP协议真的是无状态的么?
仔细阅读HTTP1.x和HTTP/2以及HTTP3.0三个版本的对比,其实会发现HTTP无状态的定义偷偷发生了变化的,为什么这么说?
在讲解具体内容之前,我们需要弄清一个概念,那就是Cookie和Session虽然让HTTP实现了“有状态”,但是其实这和HTTP协议本身的概念是没有关系的。
Cookie和Session的出现根本目的是保证会话状态本身的可见性,两者通过创立多种独立的状态“模拟”用户上一次的访问状态,但是每一次的HTTP请求本身并不会依赖上一次HTTP的请求,单纯从广义的角度看待其实所有的服务都是有状态的,但是这并不会干扰HTTP1.X本身无状态的定义。
此外HTTP协议所谓的无状态指的是每个请求是完全的独立的,在1.0备忘录定义也可以看出一次HTTP连接其实就是一次TCP连接,到了HTTP1.1实现了一个TCP多个HTTP连接依然是可以看做独立的HTTP请求。
说了这么多,其实就是说HTTP1.X在不靠Cookie和Session扶着的时候看做无状态是对的,就好比游戏里面的角色本身的数值和武器附加值的对比,武器虽然可以让角色获得某种状态,但是这种状态并不是角色本身特有的,而是靠外力借来的。
然而随着互联网发展,到了HTTP/2和HTTP3之后,HTTP本身拥有了“状态”定义。比如2.0关于HEADER压缩产生的HPACK算法(需要维护静态表和动态表),3.0还对HPACK算法再次升级为QPACK让传输更加高效。
所以总结就是严谨的来说HTTP1.X是无状态的,在Cookie和Session的辅助下实现了会话访问状态的保留。
到了HTTP/2之后HTTP是有状态的, 因为在通信协议中出现了一些状态表来维护双方重复传递的Header字段减少数据传输。
2.4 小结
这一章节本来应该是全书的核心内容,奈何作者似乎并不想让读者畏惧,所以讲的比较浅显,个人花费了不少精力收集网上资料结合自己的思考整理出第二章的内容。
关于HTTP的整个发展史是有必要掌握的,因为八股有时候会提到相关问题,问的深入一些确实有些顶不住,HTTP 协议也是应用层通信协议的核心,其次作为WEB开发人员个人认为是更是有必要掌握的。
另外了解HTTP的设计本身可以让我们过渡到TCP协议的了解,TCP的设计导致了HTTP设计的影响等问题可以做更多思考。
关于更多内容建议可以看看《网络是怎么样连接》的这一篇读书笔记,原书从整个TCP/IP 结构的角度通俗的讲述了有关互联网发展的基本脉络,而这一篇讲述了HTTP发展的基本历史和未来的发展方向。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

