package dom;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Result;
import javax.xml.transform.source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomParse {
public DomParse() {
// Todo Auto-generated constructor stub
}
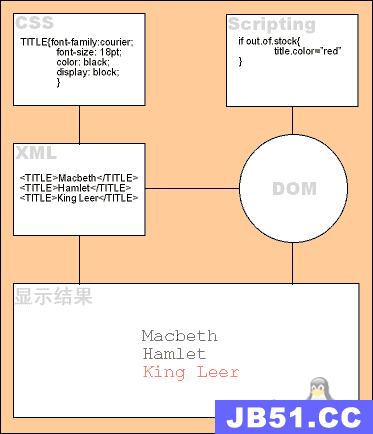
/** * xml的解析技术:JAXP是Java API for XML Processing的英文字头缩写,* 中文含义是:用于XML文档处理的使用Java语言编写的编程接口。JAXP支持DOM、SAX、XSLT等标准。 下面我们研究两种解析方式: * 1.dom解析 2.sax解析:Simple API for XML 下面是dom解析的实例。 JAXP-DOM解析实例: * 下面的实例实现的功能是,通过javax.xml包实现dom方式的xml的解析 具体的操作有增加节点,删除节点,修改节点内容,查询节点信息 */
// 可以用junit测试工具的方法进行测试
public static void main(String[] args) throws Exception {
demo05();
DomParse domParse = new DomParse();
}
// 获取和解析器关联的Document对象
public static void demo01() throws Exception {
// ==============获得document==========================
// 1.获得工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.获得解析器
DocumentBuilder builder = factory.newDocumentBuilder();
// 3.根据解析器获取Document对象
@SuppressWarnings("unused")
Document document = builder.parse(new File("db.xml"));
}
// 查询
public static void demo02() throws Exception {
// 1.获得document
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/db.xml").getCanonicalFile());
// 2.获得根元素--books(可以省略)
@SuppressWarnings("unused")
Element rootElement = document.getDocumentElement();
// 3.获取所有的book元素,属性id
NodeList allBookElements = document.getElementsByTagName("book");
// 4遍历book元素----本实例db.xml中有两个book元素
for (int i = 0; i < allBookElements.getLength(); i++) {
Element childNode = (Element) allBookElements.item(i);
System.out.println(i);
// 4.1获取book元素的id属性
String id = childNode.getAttribute("id");
System.out.println("###id:" + id);
System.out.println(childNode.getNodeName());
// 4.2获取book元素下的子节点
NodeList childNodeList = childNode.getChildNodes();
// 注意文本也是节点,所以回车换行的部分会是文本,也会添加到上面定义的childNodeList中
// 遍历
for (int j = 0; j < childNodeList.getLength(); j++) {
// 做判断-是否是非文本节点
Node childNode2 = childNodeList.item(j);
// 有两种方式判断是否一定是元素
// ================方法1=========================
if (childNode2.getNodeType() == Node.ELEMENT_NODE) {
// 获取标签的名称
System.out.print(childNode2.getNodeName());
System.out.println(":");
// 获取元素标签的内容
System.out.println(childNode2.getTextContent());
}
// ===============方法2==========================
if (childNode2 instanceof Element) {// ...........}
// =============================================
}
}
}
}
// 增加
public static void demo03() throws Exception {
// 获取doument对象-dom方式
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/db.xml").getCanonicalFile());
// 获取根元素
Element rootElement = document.getDocumentElement();
// 创建新元素,不要以为是rootElement创建的哦,Document创建,用appendchild()关联
Element bookElement = document.createElement("book");
// 为元素创建id属性
bookElement.setAttribute("id","b0003");
// 为book元素创建子元素
Element newTitleElement = document.createElement("title");
newTitleElement.setTextContent("Flex开发");
Element newPriceElement = document.createElement("price");
newPriceElement.setTextContent("98");
Element newAuthorElement = document.createElement("author");
newAuthorElement.setTextContent("胡玉勉");
bookElement.appendChild(newTitleElement);
bookElement.appendChild(newPriceElement);
bookElement.appendChild(newAuthorElement);
// 将book添加到根节点rootElement下*****************
rootElement.appendChild(bookElement);
// =======将创建好了新元素的document更新到原来的文件中=====
// 运用javax.transform技术
TransformerFactory tformFactory = TransformerFactory.newInstance();
// transform(Source xmlSource,Result outputTarget)
// 将 XML Source 转换为 Result。
Transformer transformer = tformFactory.newTransformer();
// 这里面的参数不用rootElement,用document
Source xmlSource = new DOMSource(document);
Result outputTarget = new StreamResult(new File("src/db.xml").getCanonicalFile());
transformer.transform(xmlSource,outputTarget);
}
// 删除-通过父节点删除子节点
@SuppressWarnings("unused")
public static void demo04() throws Exception {
// 获取document
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("db.xml"));
// 获取根元素
Element rootElement = document.getDocumentElement();
// 删除某一个book元素,比如id为“b003”
// 1.获取id为“b003”的元素
NodeList allBookElement = document.getElementsByTagName("book");
for (int m = 0; m < allBookElement.getLength(); m++) {
Element bookElement = (Element) allBookElement.item(m);
String id = bookElement.getAttribute("id");
if ("b0003".equals(id)) {
// 注意删除节点的时候,应遵循由自己找到父节点,然后通过父节点删除
bookElement.getParentNode().removeChild(bookElement);
}
}
// =======将删除了的document更新到原来的文件中=====
// 运用javax.transform技术:Transformer此抽象类的实例能够将源树转换为结果树
TransformerFactory tformFactory = TransformerFactory.newInstance();
// transform(Source xmlSource,Result outputTarget)
// 将 XML Source 转换为 Result。
Transformer transformer = tformFactory.newTransformer();
// 这里面的参数不用rootElement,用document
Source xmlSource = new DOMSource(document);
Result outputTarget = new StreamResult(new File("db.xml"));
transformer.transform(xmlSource,outputTarget);
}
// 修改
@SuppressWarnings("unused")
public static void demo05() throws Exception {
// 获取document
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/db.xml").getCanonicalFile());
Element rootElement = document.getDocumentElement();
// 获取元素进行修改
NodeList bookNodeList = document.getElementsByTagName("book");
// 遍历,对id=“b002”的book元素进行修改
for (int i = 0; i < bookNodeList.getLength(); i++) {
// 获取低i个book元素
Element bookNode = (Element) bookNodeList.item(i);
String id = bookNode.getAttribute("id");
if ("b002".equals(id)) {
// 获取book元素的子节点进行修改
NodeList childNodeList = bookNode.getChildNodes();
int m = 0;
for (int j = 0; j < childNodeList.getLength(); j++) {
Node bookChildNode = childNodeList.item(j);
if (bookChildNode.getNodeType() != Node.TEXT_NODE) {// 判断是否有子节点防止修改text节点
System.out.println(bookChildNode.getNodeName());
System.out.println(bookChildNode.getTextContent());
bookChildNode.setTextContent("vincent");
System.out.println(bookChildNode.getTextContent());
m++;
}
}
System.out.println("执行了" + m + "次");
}
}
// 记住别忘了回写到xml文件中
// =======将删除了的document更新到原来的文件中=====
// 运用javax.transform技术:Transformer此抽象类的实例能够将源树转换为结果树
TransformerFactory tformFactory = TransformerFactory.newInstance();
// transform(Source xmlSource,Result outputTarget)
// 将 XML Source 转换为 Result。
Transformer transformer = tformFactory.newTransformer();
// 这里面的参数不用rootElement,用document
Source xmlSource = new DOMSource(document);
Result outputTarget = new StreamResult(new File("src/db.xml").getCanonicalFile());
transformer.transform(xmlSource,outputTarget);
}
}
所用的xml文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?><books>
<book id="b001">
<title>android</title>
<price>28</price>
<author>vincent</author>
</book>
<book id="b002">
<title>vincent</title>
<price>vincent</price>
<author>vincent</author>
</book>
<book id="b0003">
<title>Flex开发</title>
<price>98</price>
<author>胡玉勉</author>
</book>
<book id="b0003">
<title>Flex开发</title>
<price>98</price>
<author>胡玉勉</author>
</book>
<book id="b0003">
<title>Flex开发</title>
<price>98</price>
<author>胡玉勉</author>
</book>
<book id="b0003">
<title>Flex开发</title>
<price>98</price>
<author>胡玉勉</author>
</book>
</books>
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。