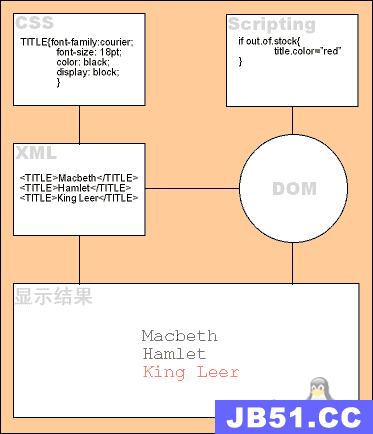
“在开始本项目之前,建议你花点时间去阅读有关XML的资料。”书说到:
‘我是很想阅读,我不会的还太多。’
要求是‘通过单个XML文件生成一个完整的网站’
先看书上写了个XML文件,website.xml
<website>
<page name="index" title="Home Page">
<h1>Welcome to My Home Page</h1>
<p>Hi,there,My name is Mr.Gumby,and this is my home page,Here are some of my interests:</p>
<ul>
<li><a href="interests/shouting.html"> Shouting</a></li>
<li><a href="interests/sleepling.html"> Sleeping</a></li>
<li><a href="interests/eating.html"> Eating</a></li>
</ul>
</page>
<directory name="interests">
<page name="shouting" title="Shouting">
<h1>Mr.Gumby's Shouting page</h1>
<p>...</p>
</page>
<page name="sleeping" title="Sleeping">
<h1>Mr.Gumby's Sleeping Page</h1>
<p>...</p>
</page>
<page name="eating" title="Eating">
<h1>Mr.Gumby's Eating Page</h1>
<p>...</p>
</page>
</directory>
</website>
的标记和C中的花括号一样,各自包含自己的语句。
虽然里面语法什么的都不懂,但还是大致理解点,感觉像 <page></page>和<ul></ul>之类的
外国人学这个就是有大大的优势,像开始 ‘该页的名字’为‘index’‘标题’为‘Home Page’
<h1></h1>里面是小标题,<p></p>是其中的内容吧。
from xml.sax.handler import ContentHandler
from xml.sax import parse
class HeadlineHandler(ContentHandler):
in_headline=False
def __init__(self,headlines):
ContentHandler.__init__(self)
self.headlines=headlines
self.data=[]
def startElement(self,name,attrs):
if name=='h1':
self.in_headline=True
def endElement(self,name):
if name=='h1':
text=''.join(self.data)
self.data=[]
self.headlines.append(text)
self.in_headline=False
def characters(self,string):
if self.in_headline:
self.data.append(string)
headlines=[]
parse('website.xml',HeadlineHandler(headlines))
print 'The following <h1> elements were found: '
for h in headlines:
print h
运行后标签,<h1></h1>之间的内容都会由headines列表输出。
__int__方法中为什么会调用父类的构造函数啊?按书上来说,应该是先调用的startElement,
找到标签<h1>,然后调用characters,将标签间的字符串添加到self.data列表中,最后调用endElement. 重置self.data列表为空,并且把原字符串添加到headlines列表中。
endElement中的‘h1’是指的配对的那个</h1>吗?要不最终self.in_headline是True还是False
明显是True后chararcts才能调用。。.
然后是生成HTML页面:
from xml.sax.handler import ContentHandler
from xml.sax import parse
class PageMaker(ContentHandler):
passthrough=False
def startElement(self,attrs):
if name=='page':
self.passthrough=True
self.out=open(attrs['name']+'.html','w')
self.out.write('<html><head>\n')
self.out.write('<title>%s</title>\n'%attrs['title'])
self.out.write('</head><body>\n')
elif self.passthrough:
self.out.write('<'+name)
for key,val in attrs.items():
self.out.write('%s="%s"'%(key,val))
self.out.write('>')
def endElement(self,name):
if name=='page':
self.passthrough=False
self.out.write('\n</body></html>\n')
self.out.close()
elif self.passthrough:
self.out.write('</%s>'%name)
def characters(self,chars):
if self.passthrough:
self.out.write(chars)
parse('website.xml',PageMaker())
最后是再次实现,
from xml.sax.handler import ContentHandler
from xml.sax import parse
import os
class Dispatcher():
def dispatch(self,prefix,attrs=None):
mname=prefix+name.capitalize()
dname='default'+prefix.capitalize()
method=getattr(self,dname,None)
if callable(method):
args=()
else:
method=getattr(self,None)
args=name,if prefix=='start':
args+=attrs,if callable(method):
method(*args)
def startElement(self,attrs):
self.dispatch('start',attrs)
def endElement(self,name):
self.dispatch('end',name)
class WebsiteConstructor(Dispatcher,ContentHandler):
passthrough=False
def __init__(self,directory):
self.directory=[directory]
self.ensureDirectory()
def ensureDirectory(self):
path=os.path.join(*self.directory)
if not os.path.isdir(path):
os.makedirs(path)
def characters(self,chars):
if self.passthrough:
self.out.write(chars)
def defaultStart(self,attrs):
if self.passthrough:
self.out.write('<',name)
for key,val))
self.out.write('>')
def defaultEnd(self,name):
if self.passthrough:
self.out.write('</%s>'%name)
def startDirectory(self,attrs):
self.directory.append(attrs['name'])
self.ensureDirectory()
def endDirectory(self):
self.directory.pop()
def startPage(self,attrs):
filename=os.path.join(*self.directory+[attrs['name']+'.html'])
self.out=open(filename,'w')
self.writeHeader(attrs['title'])
self.passthrough=True
def endPage(self):
self.passthrough=False
self.writeFooter()
self.out.close()
def writeHeader(self,title):
self.out.write('<html>\n <head>\n <title>')
self.out.write(title)
self.out.write('</title>\n </head>\n <body>\n')
def writeFooter(self):
self.out.write('\n</body>\n</html>\n')
parse('website.xml',WebsiteConstructor('public_html'))
Dispatcher中的dispatch方法是用来寻找合适的处理程序,startElement和endElement应该就是寻找的开始和结束处理程序,还有个默认处理程序defaultStart和defaultEnd,当找不到的时候,应该就调用默认程序了。然后是两个处理目录的startDirectory,endDirectory和两个处理页面的startPage,endPage。writehea der和writefooter分别输出了页首和页脚。
最后运行一直出错,说defaultStart参数有问题,结果页只有个public-html的文件夹,里面没有相应的html文件。
TypeError: defaultStart() takes excatly 3 arguments (given 2)
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。