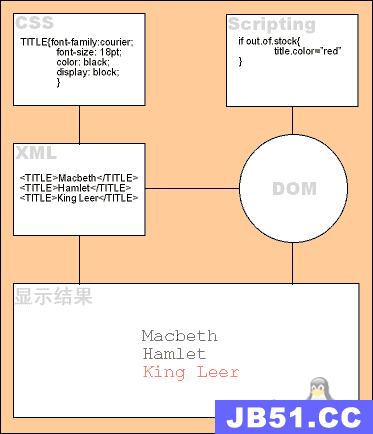
1.1 Tip:XML解析技术概述
XML解析方式分为两种:dom和sax
dom:(Document Object Model,即文档对象模型) 是 W3C 组织推荐的处理 XML 的一种方式。
sax: (Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。
XML解析器
Crimson、Xerces 、Aelfred2
XML解析开发包
Jaxp、Jdom、dom4j
1.2 Tip:JAXP
JAXP 开发包是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成
在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
1.3 Tip:使用JAXP进行DOM解析
javax.xml.parsers 包中的DocumentBuilderFactory用于创建DOM模式的解析器对象, DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法 ,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
调用DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。
调用工厂对象的newDocumentBuilder方法得到 DOM 解析器对象。
调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进行可以利用DOM特性对整个XML文档进行操作了。
//1.创建工厂 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //2。得到dom解析器 DocumentBuilder builder = factory.newDocumentBuilder(); //3。解析xml文档,得到代表文档的document Document document = builder.parse("src/book.xml");
1.1 Tip:更新XML文档
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象,
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地。
Transformer对象通过TransformerFactory获得。
public void writetoFile(){ Transformer transformer = TransformerFactory.newInstance().newTransformer(); DOMSource source = new DOMSource(document); FileOutputStream outstream =new FileOutputStream(new File("src/outbook3.xml")); StreamResult reslut = new StreamResult(outstream); transformer.transform(source,reslut); outstream.close(); }
<?xml version="1.0" encoding="UTF-8"?> <书架> <书> <书名 name="dream">做最好的自己</书名> <作者>李开复</作者> <售价>39</售价> </书> <书> <书名>退步集</书名> <作者>陈丹青</作者> <售价>35</售价> </书> </书架>
要求:1.读取<书名>退步集</书名>
2. 得到文档中所有标签
3. 得到文档中标签属性<书名 name="dream">做最好的自己</书名>
4,创建节点 <售价>30</售价>
5. 向文档中指定位置上添加节点 <售价>30</售价>
7. 删除 <售价>30</售价>
8. 更新 售价
!!! (更新完后记得写入源文档)
// 1读取<书名>退步集</书名> NodeList list=document.getElementsByTagName("书名"); Node node = list.item(1); String content = node.getTextContent(); System.out.println(content);//退步集 // 2得到文档中所有标签 Node root=document.getElementsByTagName("书架").item(0); list(root); private void list(Node node) { Node child; if (node instanceof Element) System.out.println(node.getNodeName()); NodeList nodelist = node.getChildNodes(); for (int i=0;i<nodelist.getLength();i++) { Child = nodelist.item(i); list(child); } } // 3. 得到文档中标签属性<书名 name="dream">做最好的自己</书名> NodeList list=document.getElementsByTagName("书名"); Node node=list.item(0); if(node.hasAttributes()){ NamednodeMap nodemap=node.getAttributes(); for(int i=0;i<nodemap.getLength();i++) { Node nd=nodemap.item(i); String strname=nd.getNodeName(); String strval=nd.getNodeValue(); System.out.println(strname+":"+strval);//name:dddd } } Element node2=(Element)list.item(0); String str3=node2.getAttribute("name"); System.out.println("__"+str3);//__dream } 4. //创建节点<售价>30</售价> Element price=document.createElement("售价"); price.setTextContent("30元"); //把创建的节点放到第一本书上 document.getElementsByTagName("书").item(0).appendChild(price); //把更新后的内容写回文档 writetoFile(); // 5.向文档中指定位置上添加节点 <售价>30</售价> Element price=document.createElement("售价"); price.setTextContent("30元"); //得到参考节点 Element refNode=(Element)document.getElementsByTagName("售价").item(0); //得到要挂载的节点 Element book=(Element)document.getElementsByTagName("书").item(0); //把创建的节点添加进第一本书上 document.getElementsByTagName("书").item(0).appendChild(price); // 往book节点指定位置插入售价节点 book.insertBefore(price,refNode); //把更新后的内容写回文档 writetoFile(); // 6. 向文档节点 添加属性 <售价>30</售价> Element refNode=(Element)document.getElementsByTagName("售价").item(0); refNode.setAttribute("addAtrr","new value"); //把更新后的内容写回文档 writetoFile(); // 7. 删除 <售价>30</售价> //得到要删除的节点 Element refNode=(Element)document.getElementsByTagName("售价").item(0); refNode.getParentNode().removeChild(refNode); //把更新后的内容写回文档 writetoFile(); // 8. 更新 售价 Element refNode=(Element)document.getElementsByTagName("售价").item(0); refNode.setTextContent("1000"); //把更新后的内容写回文档 writetoFile();
1.1 Tip:SAX解析
在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
阅读ContentHandler api文档,常用方法:startElement、endElement、characters
1.1 :SAX方式解析XML文档
1.使用SAXParserFactory创建SAX解析工厂
SAXParserFactoryspf = SAXParserFactory.newInstance();
2.通过SAX解析工厂得到解析器对象
SAXParser sp =spf.newSAXParser();
3.通过解析器对象得到一个XML的读取器
XMLReaderxmlReader = sp.getXMLReader();
4.设置读取器的事件处理器
xmlReader.setContentHandler(newBookParserHandler());
5.解析xml文件
xmlReader.parse("book.xml");
要求:1. 得到xml文档所有内容
3. 把每一本书封装到一个book对象,并把book对象存入一个列表中
(注意断点调试的重要性。)
//得到xml文档所有内容 class ListHandler extends defaultHandler{ @Override public void startElement(String uri,String localName,String qName,Attributes atts) throws SAXException { System.out.println("<"+qName+">"); for (int i=0;atts!=null && i<atts.getLength();i++){ String attName=atts.getQName(i); String attValue=atts.getValue(i); System.out.println(attName+"="+attValue); } } @Override public void characters(char[] ch,int start,int length) throws SAXException { System.out.println(new String(ch,start,length)); } @Override public void endElement(String uri,String qName) throws SAXException { System.out.println("</"+qName+">"); } } //获取指定标签 作者 的值 class TagValueHandler extends DefaultHandler{ private String currentTag;//记住当前解析器得到的是什么标签 private int neednumber=2;//记住想获取第几个作者标签的值 private int currentNumber;//当前解析的是第几个 @Override public void startElement(String uri,Attributes attributes) throws SAXException { currentTag=qName; if("作者".equals(currentTag)) currentNumber++; } @Override public void characters(char[] ch,int length) throws SAXException { if("作者".equals(currentTag)&& currentNumber==neednumber){ System.out.println(new String(ch,length)); } } @Override public void endElement(String uri,String qName) throws SAXException { currentTag=null; } } //把每一本书封装到一个book对象,并把book对象存入一个列表中 class BeanListHandler extends DefaultHandler{ private List<Book> list=new ArrayList<Book>(); public List<Book> getList() { return list; } private String currentTag; private Book book; @Override //判断是书后,创建书的对象 public void startElement(String uri,Attributes attributes) throws SAXException { currentTag=qName; if("书".equals(currentTag)){ book=new Book(); } } @Override //循环往书中添加各标签 public void characters(char[] ch,int length) throws SAXException { if("书名".equals(currentTag)){ book.setName(new String(ch,length)); } if("作者".equals(currentTag)){ book.setAuthor(new String(ch,length)); } if("售价".equals(currentTag)){ book.setPrice(new String(ch,length)); } } //将书对象添加到列表中,并清书对象,以便下一次使用, @Override public void endElement(String uri,String qName) throws SAXException { if(qName.equals("书")){ list.add(book); book=null; } currentTag=null; /*这句有必要,否则会出现空指针异常,因为每一次在读到结束标签后,再次读取的是结束标签后的空白处,由于currentTag在characters()中通过判断后,满足条件,所以会将空白部分的值赋给currentTag,直到最后产生空指针异常*/ } }
1.1 Tip:DOM4J解析XML文档
Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。
1.1 Tip:Document对象
DOM4j中,获得Document对象的方式有三种:
1.读取XML文件,获得document对象
SAXReader reader = newSAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document对象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主动创建document对象.
Document document = DocumentHelper.createDocument();
//创建根节点
Element root = document.addElement("members");
1.1 Tip:节点对象
1.获取文档的根节点.
Element root = document.getRootElement();
2.取得某个节点的子节点.
Elementelement=node.element(“书名");
3.取得节点的文字
String text=node.getText();
4.取得某节点下所有名为“member”的子节点,并进行遍历.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator();it.hasNext();) {
Element elm =(Element) it.next();
// do something
}
5.对某节点下的所有子节点进行遍历.
for(Iteratorit=root.elementIterator();it.hasNext();){
Elementelement = (Element) it.next();
// dosomething
}
6.在某节点下添加子节点.
Element ageElm =newMemberElm.addElement("age");
7.设置节点文字.
element.setText("29");
8.删除某节点.
//childElm是待删除的节点,parentElm是其父节点
parentElm.remove(childElm);
9.添加一个CDATA节点.
Element contentElm = infoElm.addElement("content");
contentElm.addCDATA(diary.getContent());
1.1 Tip:节点对象属性
1.取得某节点下的某属性
Elementroot=document.getRootElement();
//属性名name
Attributeattribute=root.attribute("size");
Stringtext=attribute.getText();
3.删除某属性
Attribute attribute=root.attribute("size");
root.remove(attribute);
3.遍历某节点的所有属性
Elementroot=document.getRootElement();
for(Iteratorit=root.attributeIterator();it.hasNext();){
Attributeattribute = (Attribute) it.next();
System.out.println(text);
}
newMemberElm.addAttribute("name","sitinspring");
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
1.1 Tip:将文档写入XML文件
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = newXMLWriter(newFileWriter("output.xml"));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
//指定XML编码 (和源文件相同的码表)
format.setEncoding("GBK");
XMLWriter writer = newXMLWriter(newFileWriter("output.xml"),format);
//XMLWriter writer = new XMLWriter(new OutputStreamWriter(newFileOutputStream("src/book.xml"),"GBK"),sans-serif; font-size:14px; line-height:20px; margin:10px auto!important">
//当new字符流时,因为写入的是字节,所以会去查设定的码表,但是new
//
字符流时,因为交给FileWriter去查,所以为本地默认的GB2312码表XMLWriterwriter =newXMLWriter(newFileOutputStream("src/book.xml"),format);
//XMLWriter writer = newXMLWriter(newFileWriter("src/book.xml"),format);
1.1 Tip:Dom4j在指定位置插入节点
1.得到插入位置的节点列表(list)
2.调用list.add(index,elemnent),由index决定element的插入位置。
Element元素可以通过DocumentHelper对象得到。
示例代码:
Element aaa =DocumentHelper.createElement("aaa");
aaa.setText("aaa");
List list = root.element("书").elements();
list.add(1,aaa);
//更新document
1.2 Tip:字符串与XML的转换
1.将字符串转化为XML
String text = "<members><member>sitinspring</member></members>";
Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(newFile("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。