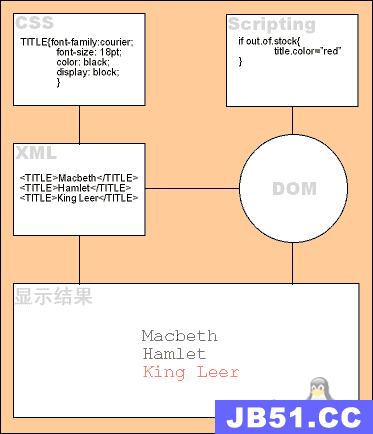
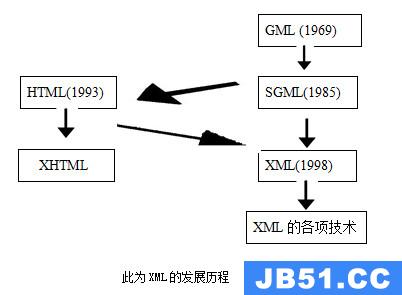
学习日记01
XMl语法:
1.文档声明:
在编写XML文档时,需要先使用XML文档声明,声明XML文档的类型
最简单的文档声明语法:<?xml version=”1.0” ?>
用encoding属性说明文档的字符编码
<?xml version=”1.0”encoding=”UTF-8” ?>
用standalone属性说明文档是否独立:
<?xmlversion=”1.0” encoding=”UTF-8” standalone=”yes” ?>
2.元素:XML中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写形式:
一个标签中也可以嵌套若干子标签。但所有标签必须合理的嵌套,绝对不允许交叉嵌套,例如:
<a>welcome to<b>www.it315.org</a></b>
格式良好的XML文档必须有且仅有一个根标签,其它标签都是这个根标签的子孙标签
对于XML标签中出现的所有空格和换行,XML解析程序都会当作标签内容进行处理。例如:下面两段内容的意义是不一样的
<网址>www.itcast.cn</网址>
<网址>
www.itcast.cn
</网址>
由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,使用换行和缩进等方式来让原文件中的内容清晰可读的“良好”书写习惯可能要被迫改变。
l 一个XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守下面的一些规范:
l 区分大小写,例如,<P>和<p>是两个不同的标记。
l 不能以数字或"_" (下划线)开头。
l 不能以xml(或XML、或Xml 等)开头。
l 不能包含空格。
l 名称中间不能包含冒号(:)。
3.属性
一个标签可以有多个属性,每个属性都有它自己的名称和取值,例如:
<input name=“text”>
属性值一定要用双引号(")或单引号(')引起来
多学一招:在XML技术中,标签属性所代表的信息,也可以被改成用子元素的形式来描述,例如:
<input>
<name>text</name>
</input>
4.注释
Xml文件中的注释采用:“<!--注释-->” 格式。
注意:
XML声明之前不能有注释
注释不能嵌套,例如:
<!--大段注释
……
<!--局部注释-->
……
-->
5.CDATA区,特殊字符
在编写XML文件时,有些内容可能不想让解析引擎解析执行,而是当作原始内容处理
遇到此种情况,可以把这些内容放在CDATA区里,对于CDATA区域内的内容,XML解析程序不会处理,而是直接原封不动的输出。
语法:<![CDATA[ 内容 ]]>
<![CDATA[
<itcast>
<br/>
</itcast>
]]>
6.处理指令(processing instruction)
简称PI (processing instruction)。处理指令用来指挥解析引擎如何解析XML文档内容。
例如,在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,应用css文件显示xml文档内容。
<?xml-stylesheettype="text/css" href="1.css"?>
处理指令必须以“<?”作为开头,以“?>”作为结尾,XML声明语句就是最常见的一种处理指令。
XML约束:在XML技术里,可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束
l 常用的约束技术
XML DTD (DocumentType DeFinition),全称为文档类型定义
XML Schema
引用DTD约束:
l XML文件使用 DOCTYPE 声明语句来指明它所遵循的DTD文件,DOCTYPE声明语句有两种形式:
当引用的文件在本地时,采用如下方式:
<!DOCTYPE 文档根结点 SYstem "DTD文件的URL">
例如: <!DOCTYPE 书架 SYstem “book.dtd”>。在xml文件中手写一下。
<!DOCTYPE 文档根结点 PUBLIC "DTD名称" "DTD文件的URL">
例如:<!DOCTYPE web-app PUBLIC
"-//sunmicrosystems,Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
DTD约束语法细节:
l 元素定义
在DTD文档中使用ELEMENT声明一个XML元素,语法格式如下所示:
<!ELEMENT 元素名称 元素类型>
元素类型可以是元素内容、或类型
•如为元素内容:则需要使用()括起来,如
<!ELEMENT 书架(书名,作者,售价)>
<!ELEMENT 书名(#PCDATA)>
• 如为元素类型,则直接书写,DTD规范定义了如下几种类型:
•EMPTY:用于定义空元素,例如<br/> <hr/>
•ANY:表示元素内容为任意类型。
• 用逗号分隔,表示内容的出现顺序必须与声明时一致。<!ELEMENT MYFILE(TITLE,AUTHOR,EMAIL)>
• 用|分隔,表示任选其一,即多个只能出现一个
<!ELEMENT MYFILE (TITLE|AUTHOR|EMAIL)>
+: 一次或多次 (书+)
?:0次或一次 (书?)
*: 0次或多次 (书*)
也可使用圆括号( )批量设置,例
<!ELEMENT MYFILE ((TITLE*,AUTHOR?,EMAIL)* | COMMENT)>
l 属性定义
语法格式:
<!ATTLIST元素名
……
>
属性声明举例:
<!ATTLIST 商品
类别 CDATA #required
颜色 CDATA #IMPLIED
>
对应XML文件:
<商品类别="服装" 颜色="黄色">…</商品>
<商品类别="服装">…</商品>
设置说明:
• #IMPLIED:可以设置也可以不设置
• #FIXED:说明该属性的取值固定为一个值,在 XML 文件中不能为该属性设置其它值。但需要为该属性提供这个值
直接使用默认值:在 XML 中可以设置该值也可以不设置该属性值。若没设置则使用默认值
举例:
<!ATTLIST 页面作者
姓名 CDATA #IMPLIED
年龄 CDATA #IMPLIED
联系信息 CDATA #required
网站职务 CDATA #FIXED "页面作者"
个人爱好 CDATA "上网"
>
常用属性值类型:
l CDATA:表示属性值为普通文本字符串。
l ENUMERATED
l ID
l ENTITY(实体)
属性值类型àENUMERATED
l 属性的类型可以是一组取值的列表,在 XML 文件中设置的属性值只能是这个列表中的某个值(枚举)
<?xml version ="1.0" encoding="GB2312" standalone="yes"?>
<!DOCTYPE 购物篮 [
<!ELEMENT肉 EMPTY>
<!ATTLIST肉 品种 ( 鸡肉 | 牛肉 | 猪肉 | 鱼肉 ) "鸡肉">
]>
<购物篮>
<肉 品种="鱼肉"/>
<肉 品种="牛肉"/>
<肉/>
</购物篮>
属性值类型à ID
ID 属性的值只能由字母,下划线开始,不能出现空白字符
l 实体定义:
实体用于为一段内容创建一个别名,以后在XML文档中就可以使用别名引用这段内容了。
在DTD定义中,一条<!ENTITY …>语句用于定义一个实体。
实体可分为两种类型:引用实体和参数实体。
实体定义à引用实体 :
l 引用实体主要在 XML 文档中被应用
l 语法格式:
•<!ENTITY实体名称 “实体内容” >:直接转变成实体内容
l 引用方式:
&实体名称;
l 举例:
<!ENTITYcopyright “I am a programmer">
……
©right;
实体定义à参数实体:
参数实体被 DTD 文件自身使用
语法格式:
引用方式:
%实体名称;
举例1:
<!ENTITY % TAG_NAMES "姓名 | EMAIL | 电话 | 地址">
<!ELEMENT 个人信息 (%TAG_NAMES; | 生日)>
<!ELEMENT 客户信息 (%TAG_NAMES; | 公司名)>
举例2:
<!ENTITY % common.attributes
" id ID #IMPLIED
account CDATA #required"
>
...
<!ATTLIST purchaSEOrder %common.attributes;>
<!ATTLIST item %common.attributes;>
XML编程(CRUD)
XML解析技术概述:
lXML解析方式分为两种:dom和sax
ldom:(Document Object Model,即文档对象模型) 是W3C 组织推荐的处理XML 的一种方式。
lsax: (Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。
lXML解析器
• Crimson(sun)、Xerces(IBM) 、Aelfred2(dom4j)
lXML解析开发包
• Jaxp(sun)(最差)、Jdom(jdom)(中等,基本不用)、dom4j(dom4j)(最优)
使用JAXP进行DOM解析:
ljavax.xml.parsers包中的DocumentBuilderFactory用于创建DOM模式的解析器对象 , DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
SAX解析:
SAX解析XML文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的XML文件内容作为方法的参数传递给事件处理器。
事件处理器有程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到SAX解析器解析到的数据,从而可以决定如何对数据进行处理。
SAX方式解析XML文档:
l使用SAXParserFactory创建SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
l通过SAX解析工厂得到解析器对象
SAXParser sp = spf.newSAXParser();
l通过解析器对象得到一个XML的读取器
XMLReader xmlReader = sp.getXMLReader();
l设置读取器的事件处理器
xmlReader.setContentHandler(new BookParserHandler());
l解析xml文件
xmlReader.parse("book.xml");
DOM4J解析XML文档:
DOM4j中,获得Document对象的方式有三种:
1.读取XML文件,获得document对象
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document对象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主动创建document对象.
Document document = DocumentHelper.createDocument();
//创建根节点
Elementroot = document.addElement("members");
1.获取文档的根节点.
Element root =document.getRootElement();
2.取得某个节点的子节点.
Elementelement=node.element(“书名");
3.取得节点的文字
Stringtext=node.getText();
4.取得某节点下所有名为“member”的子节点,并进行遍历.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator();it.hasNext();) {
Element elm =(Element) it.next();
// do something
}
5.对某节点下的所有子节点进行遍历.
for(Iteratorit=root.elementIterator();it.hasNext();){
Elementelement = (Element) it.next();
//do something
}
6.在某节点下添加子节点.
Element ageElm = newMemberElm.addElement("age");
7. 设置节点文字.
element.setText("29");
8. 删除某节点.
//childElm是待删除的节点,parentElm是其父节点
parentElm.remove(childElm);
9. 添加一个CDATA节点.
Element contentElm = infoElm.addElement("content");
contentElm.addCDATA(diary.getContent());
节点对象属性:
l1.取得某节点下的某属性
Elementroot=document.getRootElement();
//属性名name
Attributeattribute=root.attribute("size");
l2.取得属性的文字
Stringtext=attribute.getText();
l3.删除某属性
Attribute attribute=root.attribute("size");
root.remove(attribute);
l4.遍历某节点的所有属性
Elementroot=document.getRootElement();
for(Iteratorit=root.attributeIterator();it.hasNext();){
Attributeattribute = (Attribute) it.next();
Stringtext=attribute.getText();
System.out.println(text);
}
l5.设置某节点的属性和文字.
newMemberElm.addAttribute("name","sitinspring");
l6.设置属性的文字
Attributeattribute=root.attribute("name");
attribute.setText("sitinspring");
将文档写入XML文件:
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = newXMLWriter(newFileWriter("output.xml"));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
// 指定XML编码
format.setEncoding("GBK");
XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format);
writer.write(document);
writer.close();
XML Schema:
XML Schema 也是一种用于定义和描述 XML 文档结构与内容的模式语言,其出现是为了克服 DTD 的局限性
XML Schema VS DTD:
XML Schema符合XML语法结构。
DOM、SAX等XML API很容易解析出XML Schema文档中的内容。
XML Schema比XML DTD支持更多的数据类型,并支持用户自定义新的数据类型。
XML Schema定义约束的能力非常强大,可以对XML实例文档作出细致的语义限制。
XML Schema不能像DTD一样定义实体,比DTD更复杂,但Xml Schema现在已是w3c组织的标准,它正逐步取代DTD。
Schema约束快速入门:
XML Schema 文件自身就是一个XML文件,但它的扩展名通常为.xsd。
一个XML Schema文档通常称之为模式文档(约束文档),遵循这个文档书写的xml文件称之为实例文档。
和XML文件一样,一个XML Schema文档也必须有一个根结点,但这个根结点的名称为Schema。
编写了一个XML Schema约束文档后,通常需要把这个文件中声明的元素绑定到一个URI地址上,在XML Schema技术中有一个专业术语来描述这个过程,即把XML Schema文档声明的元素绑定到一个名称空间上,以后XML文件就可以通过这个URI(即名称空间)来告诉解析引擎,xml文档中编写的元素来自哪里,被谁约束。
使用名称空间引入Schema:
为了在一个XML文档中声明它所遵循的Schema文件的具体位置,通常需要在Xml文档中的根结点中使用schemaLocation属性来指定,例如:
<itcast:书架xmlns:itcast="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.itcast.cn book.xsd">
schemaLocation此属性有两个值。第一个值是需要使用的命名空间。第二个值是供命名空间使用的 XML schema的位置,两者之间用空格分隔。
注意,在使用schemaLocation属性时,也需要指定该属性来自哪里。
基本格式:
xmlns="URI"
举例:
<书架xmlns="http://www.it315.org/xmlbook/schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.itcast.cn book.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
<书架>
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。