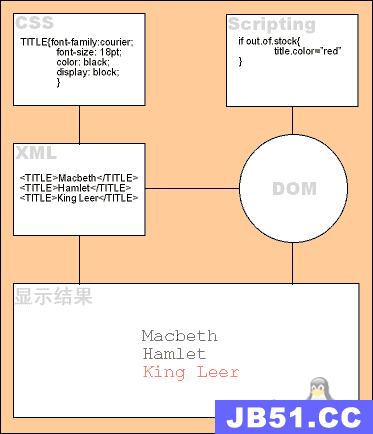
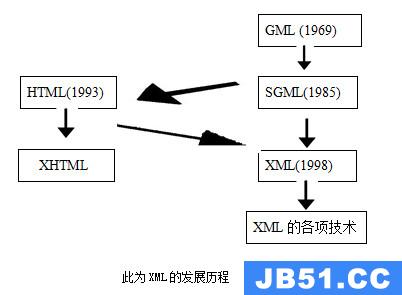
XML称为可扩展标记语言(ExtensibleMarkupLanguage),由标准通用标记语言(SGML:Standard Generalized MarkuP Language)发展而来,允许开发者自定义标签,可以实现标签和内容的有效分离。
与HTML不同,XML不再侧重于数据如何表现,而是更多的关注数据如何存储和传输。因此,XML逐渐演变成为一种跨平台的数据交换格式。通过使用XML,开发者可以在不同平台、不同系统之间进行数据交换。除此之外,还可以使用XML作为配置文件,将应用程序状态保存到XML文件中,而无须使用关系型数据库。
1.XML数据结构
XML提供统一的方法来描述独立于应用程序或供应商的结构化数据。编写XML文档至少应该满足以下四个要求:
(1)整个XML文档有且只有一个根元素。
(3)元素与元素之间应该合理嵌套。
如下的XML文档按照上述的四点要求,定义了一份人员名单(person.xml):
1 <?xml version="1.0" encoding="UTF-8"?> 2 <persons> 3 person id="1" 4 name>Jack</ 5 age>24 6 person 7 ="2" 8 >Tom 9 >2510 11 ="3"12 >Bob13 >2214 15 >
可以看出,该XML文档的根元素为<persons>,其中包含了3个元素<person>。在每个元素<person>中都包含一个元素属性值id和两个内嵌元素<name>和<age>。
当XML文档遵循上面的四个基本规范时,便可以准确的将其转换为树状结构,如图1所示,所以XML是一种树形结构的文档。
图1XML文档对应的树状结构
2.JAXP
当XML文档作为数据交换工具时,应用程序必须采用合适的方式来获取XML文档里包含的有用信息,这就需要通过程序来解析XML文档。
为了利用XML文档的结构化特性进行解析,目前有两套比较流行的规范:
(1)DOM(DocumentObjectModel):文档对象模型,是W3C推荐的处理XML文档的规范。
(2)SAX(SimpleAPIforXML):不是W3C推荐的标准,但却是整个XML行业的事实规范。
2.1DOM和SAX的区别
DOM为解析XML文档定义了一组标准接口,DOM解析器负责读入整个文档,然后将该文档转换成常驻内存的树状结构(也称为DOM树),然后程序代码就可以使用节点与节点之间的父子关系来访问DOM树,并获得每个节点所包含的数据。
SAX采用事件驱动机制来解析XML文档,每当SAX解析器发现文档开始、元素开始、文本、元素结束、文档结束等事件时,就会向外发送一次事件,而开发者则可以通过编写事件监听器处理这些事件,以此来获取XML文档里的信息。
DOM标准简单易用,但是它需要一次性地读取整个XML文档,而且在程序运行期间,整个DOM树常驻内存,导致系统开销过大。SAX解析方式占用内存小,处理速度更快。
由于DOM一次性将整个XML文档全部读入内存,因此可以随机访问XML文档的每个元素。SAX采用顺序模式来依次读取XML文档,因此无法做到随机访问XML文档的任意元素。
2.2JAXP接口
JAXP的全称是JavaAPIforXML。JAXP支持DOM、SAX以及XSLT等XML标准,但其本身没有提供任何的XML解析支持,其底层必须依赖于各种具体的XML解析器。通过在各种XML解析器之上再增加一层“工程模式”的抽象,JAXP不与任何具体的XML解析器耦合,因而使得应用程序可以在各种XML解析器之间轻松切换而无须修改源代码。
因此,JAXP是建立在DOM和SAX之上的一个抽象层,它既没有提供解析XML的新方法,也没有对DOM和SAX进行任何扩展,仅仅只是提供了一种工厂模式,允许应用程序在不同的XML解析器之间切换。
通过JAXP,开发者可以直接面向JAXP的接口和工厂类编程,至于具体选择使用哪一种XML解析器则由JAXP来决定。
JAXP本身就是JDK的一部分,由以下3个包组成。
(1)java.xml包及其子包:主要用来获取解析器的实例。
(2)org.xml.sax包及其子包:提供使用SAX方式解析时所需的接口或类。
(3)org.w3c.dom包及其子包:提供使用DOM方式解析时所需的接口或类。
其中,java.xml.parsers包中提供了如下4个与DOM和SAX解析相关的类。
(1)DocumentBuilderFactory:DOM解析器的工厂类,用于获取DOM解析器实例,它是JAXP工程模式里的工厂。
(2)DocumentBuilder:DOM解析器的标准接口,所有的DOM解析器都应该实现该接口。
(3)SAXParserFactory:SAX解析器的工厂类,用于获取SAX解析器实例,它是JAXP工程模式里的工厂。
(4)SAXParser:SAX解析器的标准接口,所有的SAX解析器都应该实现该接口。
3.JAXP的SAX支持
使用SAX解析器对XML文档进行解析时,会触发一系列事件,这些事件将被相应的事件监听器监听,从而触发相应的事件处理方法,应用程序通过这些事件处理方法实现对XML文档的访问。
3.1SAX解析器
JAXP为SAX解析器提供了以下的2组API。
(1)XMLReader和XMLReaderFactory:XMLReaderFactory工程类的creatXMLReader()静态方法用于创建XMLReader。
(2)SAXParser和SAXParserFactory:SAXParserFactory工厂类的newSAXParser()实例方法用于创建SAXParser。
以上两组API中的XMLReader和SAXParser都是SAX解析器,它们都定义了多个parser()方法,用于以SAX方式解析XML文档。
其中,XMLReader提供了如下2个用于解析XML文档的parser()方法。
(1)voidparse(InputSourceinput); //解析InputSource输入源中的XML文档
(2)voidparse(StringsystemId); //解析系统URI指定的XML文档
SAXParser则提供了如下4个用于解析XML文档的parser()方法。
(1)voidparse(Filef,DefaultHandlerdh); //解析f文件所代表的XML文档
(2)voidparse(InputSourceis,DefaultHandlerdh); //解析InputSource输入源中的XML文档
(3)voidparse(InputStreamis,DefaultHandlerdh); //解析InputStream输入源中的XML文档
(4)voidparse(Stringuri,DefaultHandlerdh); //解析系统URI指定的XML文档
可以看出,在SAXParser的parser()方法中,第二个参数是一个DefaultHandler对象,该对象就是用于监听SAX解析事件的监听器。
3.2SAX监听器
SAX的监听器有以下4个。
(1)ContentHandler:监听XML文档内容处理事件的监听器
(2)DTDHandler:监听DTD处理事件的监听器
(3)EntityResolver:监听实体处理事件的监听器
(4)ErrorHandler:监听解析错误的监听器
如果使用XMLReader来解析XML文档,开发者需要分别为上述4个监听器提供实现类,然后再调用XMLReader中的setContentHandler()、setDTDHandler()、setEntityResolver()和setErrorHandler()方法注册监听器,这将会非常麻烦。
因此,JAXP提供了DefaultHandler类来解决这个问题。DefaultHandler类实现了ContentHandler、DTDHandler、EntityResolver和ErrorHandler接口,并为这些接口中所包含的方法提供了空实现。因此,开发者只需要编写一个继承自DefaultHandler的类,并重写自己所关心的监听方法,而无须为每个方法都提供实现。
3.3使用SAX解析XML文档的一般步骤
使用SAXParser解析器解析XML文档的一般步骤如下。
(1)通过SAXParserFactory的newInstance()方法创建SAXParserFactory对象(SAX解析器工厂)。
(2)通过SAXParserFactory对象的newSAXParser()方法创建SAXParser对象(SAX解析器)。
(3)通过SAXParser对象的parser()方法解析XML文档,该方法的第二个参数需要传入一个DefaultHandler对象。
要实现上述的3个步骤也很容易,如下的代码演示了这一过程:
可以看到,在readxml()方法中,我们以InputStream对象的形式读取XML文档,创建并使用SAXParser解析器对该XML文档进行解析,最终返回解析得到的数据列表。这里解析的XML文档正是我们前面提到的那份人员名单(person.xml)。根据该XML文档,我们可以抽象出一个Person类,该类具有id、name、age三项成员变量。包含Person对象的列表正是我们解析该XML文档后所需要得到的内容。
此外,在这段代码中,我们还创建了一个MyDefaultHandle对象,MyDefaultHandle继承自DefaultHandle类,并实现了解析XML文档所必须的几个方法。
3.4MyDefaultHandle类的实现
ContentHandler监听器用于监听XML文档内容处理事件,在ContentHandler接口中提供了以下几个方法。
(1)voidstartDocument();
(2)voidendDocument();
(3)voidcharacters(char[]ch,intstart,intlength);
(4)voidstartElement(Stringuri,StringlocalName,StringqName,Attributesatts);
(5)voidendElement(Stringuri,StringqName);
(6)voidstartPrefixMapping(Stringprefix,Stringuri);
(7)voidendPrefixMapping(Stringprefix);
(8)voidignorableWhitespace(char[]ch,intlength);
(9)voidprocessingInstruction(Stringtarget,Stringdata);
(10)voidskippedEntity(Stringname);
其中,当SAX解析器开始处理文档时会触发startDocument()方法;当SAX解析器处理文档结束时会触发endDocument()方法;当SAX解析器处理字符数据时会触发characters()方法;当SAX解析器开始处理元素时会触发startElement()方法;当SAX解析器处理元素结束时会触发endElement()方法;当SAX解析器开始处理元素里的命名空间属性时会触发startPrefixMapping()方法;当SAX解析器处理元素里的命名空间属性结束时会触发endPrefixMapping()方法;当SAX解析器处理元素内容中可忽略的空白时会触发ignorableWhitespace()方法;当SAX解析器处理指令时会触发processingInstruction()方法;当SAX解析器跳过实体时会触发skippedEntity()方法。
根据所要解析的XML文档的内容,我们可以有选择的在MyDefaultHandle类中实现ContentHandler、DTDHandler、EntityResolver和ErrorHandler接口提供的方法。这里,根据需要我只是简单的实现了ContentHandler接口中提供的startDocument()、endDocument()、characters()、startElement()和endElement()方法。具体实现代码如下:
至此,我们便完成了MyDefaultHandle类的编写,并在MyDefaultHandle类中重写了startDocument()、endDocument()、characters()、startElement()和endElement()方法。
4.单体测试
当然了,最后我们还需要对以上的代码进行单体测试,以确保person.xml文件被正确解析,如图2所示。
图2单体测试结果
http://www.cnblogs.com/menlsh/archive/2013/05/04/3060250.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。