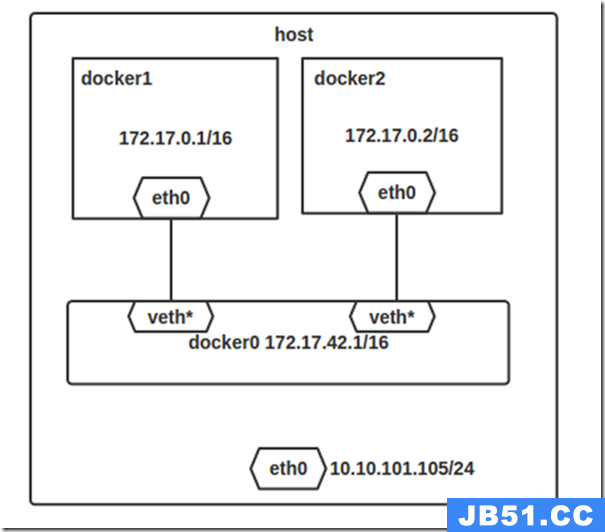
我正在基于Docker的环境中规划多节点Hadoop集群的阶段.所以它应该基于轻量级易用的虚拟化系统.
当前架构(关于文档)包含1个主节点和3个从节点.该主机使用HDFS文件系统和KVM进行虚拟化.
整个云由Cloudera Manager管理.此群集上安装了多个Hadoop模块.还有一个NodeJS数据上传服务.
这次我应该建立基于Docker的架构.
我已阅读了几篇教程并提出了一些意见,但也提出了一些问题.
A.您如何看待https://github.com/Lewuathe/docker-hadoop-cluster是我项目的良好基础?我发现了官方image,但它是单节点.
B.如果我想在单个容器中进行此操作,系统要求将如何变化?这将是很好的,因为这种架构应该在不同的位置工作,因此可以在这些位置之间轻松传输更改.这些所谓的克隆之间的同步将是重要的.
C.你有其他想法,也许是最佳做法?
要解决您的问题C.,您可能需要查看BlueData的软件平台:http://www.bluedata.com/blog/2015/06/docker-containers-big-data-clusters
它旨在在基于Docker的环境中运行多节点Hadoop集群,并且有一个可供下载的免费版本(您也可以在AWS EC2实例中运行它).
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。